jupyter notebook是运行python的首选工具,那么能不能用它来运行SQL呢?调用sqlite3 两行代码就能轻松实现啦:
调包
import pandas as pd
import sqlite3
导入数据
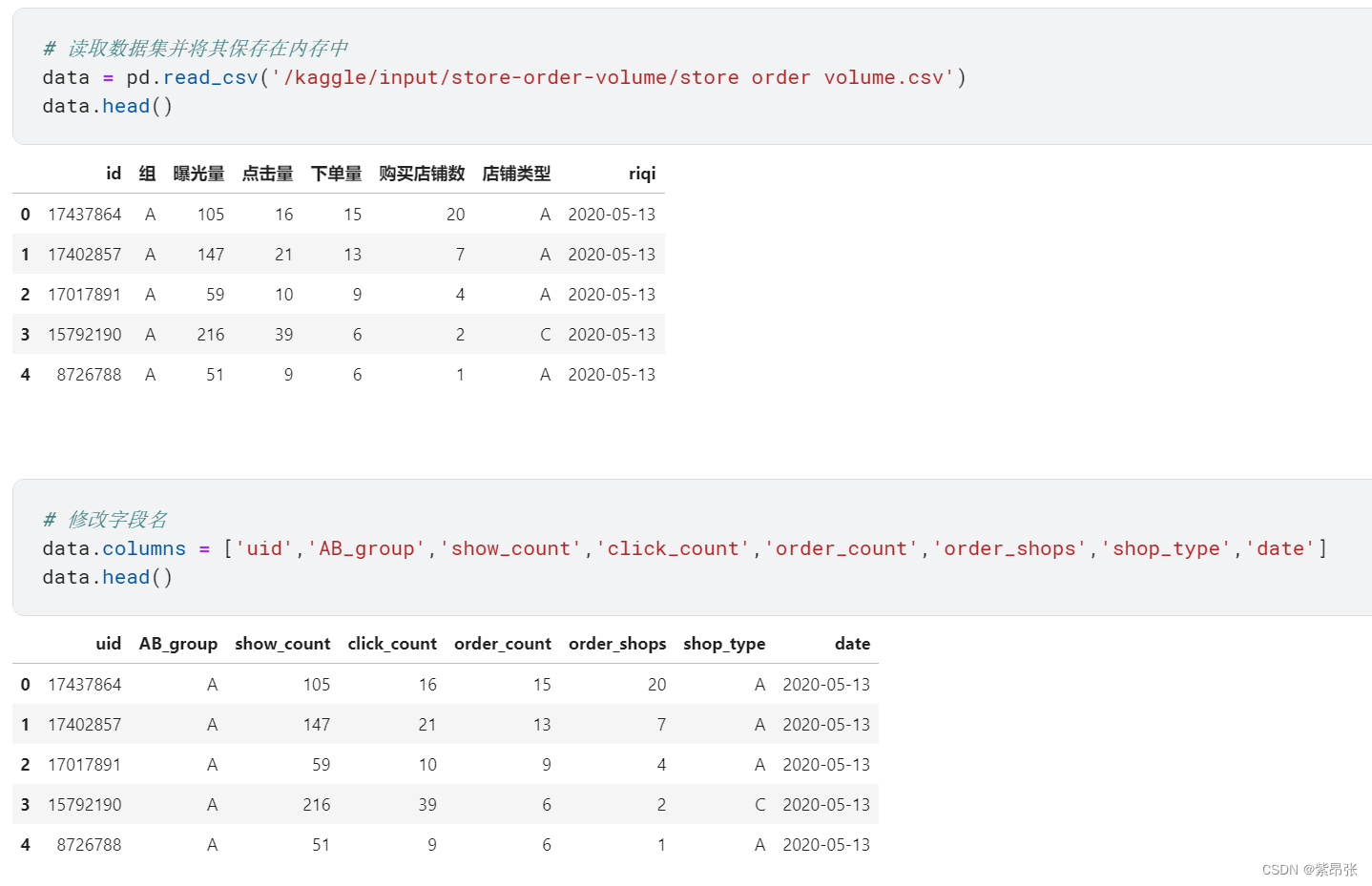
# 读取数据集并将其保存在内存中
data = pd.read_csv('/kaggle/input/store-order-volume/store order volume.csv')
# 修改字段名
data.columns = ['uid','AB_group','show_count','click_count','order_count','order_shops','shop_type','date']
data.head()
代码详解:
data是我们用来存数据集的变量,是dataframe的格式;
data.columns返回的是列索引,我们可以用它对字段名进行修改,注意字段名要和数据集的一致。(因为原数据集的字段名是中文,需要修改成英文,以满足数据库的使用习惯)
调用sqlite3工具
# 创建内存数据库:使用sqlite3库创建一个内存数据库
conn = sqlite3.connect(':memory:')
# 将数据导入数据库:将加载的数据集导入到内存数据库中
data.to_sql('store_order', conn, index=False)代码详解:
这段代码的作用是创建了一个空的SQLite内存数据库,并建立了一个连接对象以便后续操作。
SQLite是一种轻量级的关系型数据库管理系统,它可以在本地文件或内存中创建数据库。
“:memory:”是SQLite中专门用于表示内存数据库的特殊字符串,它表示创建一个空的内存数据库。
to_sql()函数是pandas中用于将数据框数据写入到SQL数据库中的函数。它接受三个必需的参数:表名、数据库连接和写入模式。
查询
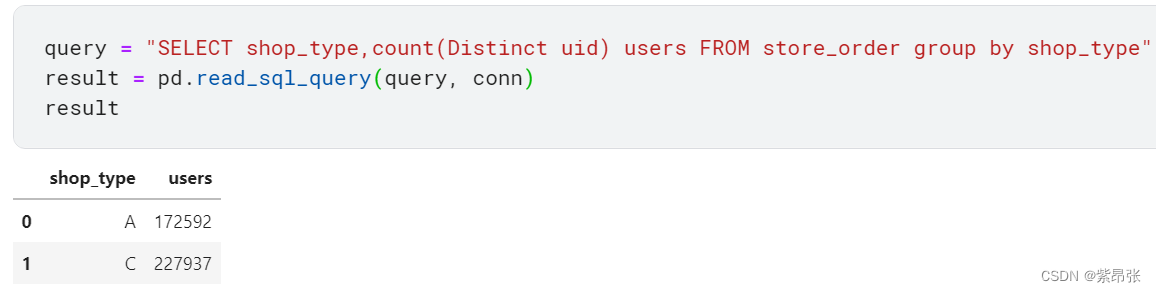
最后把SQL赋值进query里就能进行查询啦:
query = "SELECT shop_type,count(Distinct uid) users FROM store_order group by shop_type"
result = pd.read_sql_query(query, conn)
result运行结果:
版权声明:本文为Sukey666666原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。