本次又从kaggle上淘来了
King County
的房价数据,结合近期学习的Python分析工具,对影响房价的可能因素进行分析。
-
提出问题
随着国家对房产市场的宏观调控越来越严格,此前一路高歌猛进的房产市场也随之开始转冷,那么除了政策因素,还有哪些因素会影响房价呢?
本次我们以
King County
的房价数据为参考依据,对房价可能存在的影响因素进行分析:
①
房价与环境配套有哪些关系?
分别从
海滨区域、设施等级、房屋评级等级
进行分析(评级标准为当地自己的评级系统所产生,本次分析将直接引用);
②
房价与房间配置有哪些关系?
分别从
卧室数、洗浴室数、楼层
进行分析;
③
房价与得房率的关系?
得房率=使用面积/建筑面积
;
由于2015年有房主自行翻修,可能存在扩大使用面积情况,故此处
使用面积
用
2015年使用面积
;
④
房价与房龄的关系?
房龄=2015-建成时间
;
数据为2015年上传,故按照2015为时间起始点计算;
⑤
房屋实看数
房屋实看数=房屋被实际查看的数量;
房屋查看的数量一定程度上可反映出用户对于房价的接受程度;
-
理解数据
由于下载的数据格式为CSV格式,故直接本地数据upload至Jupyter notebook;
#读取CSV,均转为str格式数据,后期在进行其他格式数据转换
import pandas as pd
import numpy as np
priceDf=pd.read_csv('kc_house_data.csv',dtype='object')
#打印头5行查看数据
priceDf.head()
-
数据清洗
1)选择子集
#选择子集
subpriceDf=priceDf.loc[:,'id':'grade']

2)重命名列名
#将需要使用的列名重新命名
calNameDict={'date':'日期',
'price':'房价',
'bedrooms':'卧室数',
'bathrooms':'洗浴室数',
'sqft_living':'使用面积',
'sqft_lot':'建筑面积',
'floors':'楼层',
'waterfront':'海滨区',
'view':'实看数','grade':'房屋等级',
'yr_built':'建成年份',
'yr_renovated':'翻修年份',
'zipcode':'邮编',
'sqft_living15':'使用面积(2015)',
'condition':'条件设施',
'sqft_lot15':'建筑面积(2015)',
'id':'编号',
'sqft_above':'地上建筑面积',
'sqft_basement':'地下建筑面积',
'lat':'纬度',
'long':'经度'}
priceDf.rename(columns=calNameDict,inplace=True)
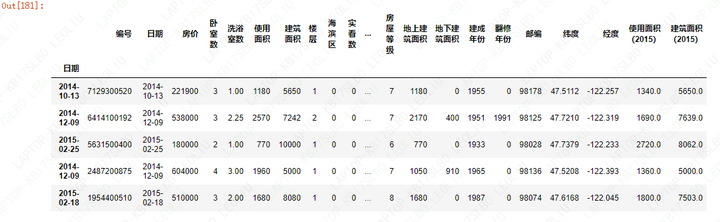
3)缺失值处理(仅删除)
#处理缺失值(本次仅做删除处理)
priceDf=priceDf.dropna(subset=['卧室数','洗浴室数','楼层','海滨区','条件设施','房屋等级','使用面积(2015)','建筑面积(2015)','建成年份','实看数'],how='any')
4)数据类型转化
#将数据中属于浮点型的数据进行转化
priceDf['洗浴室数']=priceDf['洗浴室数'].astype('float')
priceDf['lat']=priceDf['lat'].astype('float')
priceDf['long']=priceDf['long'].astype('float')
priceDf['使用面积(2015)']=priceDf['使用面积(2015)'].astype('float')
priceDf['建筑面积(2015)']=priceDf['建筑面积(2015)'].astype('float')
#打印出结果,查看是否更改彻底
print(priceDf.dtypes)
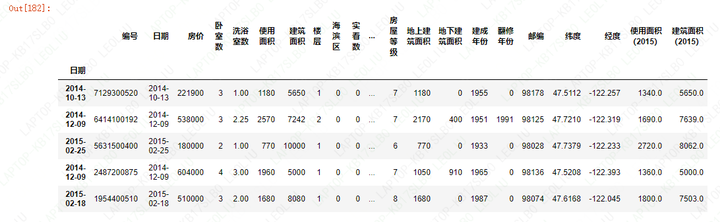
#将数据中日期的字符串形式转化
priceDf.loc[:,'日期']=pd.to_datetime(priceDf.loc[:,'日期'],
format='%Y-%m-%d',
errors='coerce')
-
构建模型
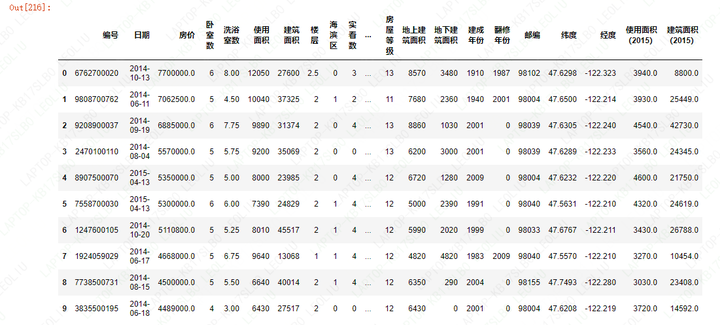
1)房价与环境配套的相关性
此处仅对’房价’,’海滨区’,’条件设施’,’房屋等级’进行展示,并查看其相关性;
#去重
kpi1_Df=priceDf.drop_duplicates(
subset=['房价','海滨区','条件设施','房屋等级'])
#结果按'房价'倒叙排列
kpi1_Df=kpi1_Df.sort_values(by='房价',
ascending=False)
#重新命名编号列
kpi1_Df=kpi1_Df.reset_index(drop=True)
#打印出结果的前十行数据
kpi1_Df.head(10)
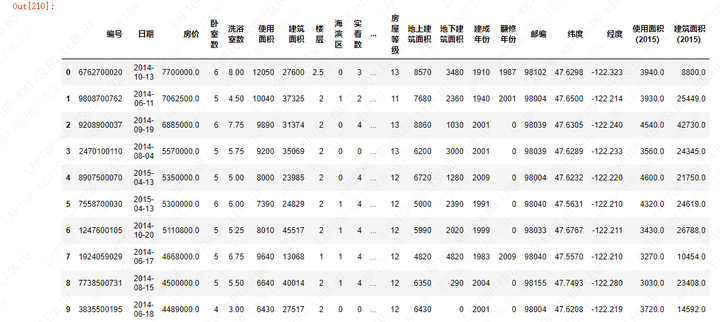
2)房价与房间配置的相关性
方法与模型1)类似,此处不再赘述,详见代码;
#去重
kpi2_Df=priceDf.drop_duplicates(
subset=['房价','卧室数','洗浴室数','楼层'])
#结果按'房价'倒叙排列
kpi2_Df=kpi2_Df.sort_values(by='房价',
ascending=False)
#重新命名编号列
kpi2_Df=kpi2_Df.reset_index(drop=True)
#打印出结果的前十行数据
kpi2_Df.head(10)
3)得房率
#统计建筑面积&使用面积之和(以2015年为基准)
totalAreaF1=priceDf.loc[:,'建筑面积(2015)'].sum()
totalAreaF2=priceDf.loc[:,'使用面积(2015)'].sum()
kpi3_Df=totalAreaF2/totalAreaF1
print('得房率=',kpi3_Df)
得房率= 0.15558283207827878;
4)房价与房龄的相关性
#按照建成年代进行分组,并查看对应房价的平均值
builtyrF=priceDf['房价'].groupby(priceDf['建成年份']).mean()
#按金额倒叙排序,并限制展示前十房源
builtyrF=builtyrF.sort_values(ascending=False)
builtyrF.head(10)

5)房屋实看数
实际看房数一定程度上说明了用户的偏好情况;
#按照实看数进行分组,并查看对应房价的平均值
viewF=priceDf['房价'].groupby(priceDf['实看数']).mean()
#按金额进行正序排序
viewF=viewF.sort_values(ascending=False)
viewF.head(10)

-
小结
1)房价与环境配套的相关性
King County的高价房源都集中于海滨区域,且评分都较高,最高价高达7700000美金。
2)房价与房间配置的相关性
高价房源的建筑面积较高,其中价格前十的房源大部分拥有5-6个卧室或洗浴室,而楼层偏底层,大部分为2层建筑,猜测此部分房源可能为海滨区的别墅住宅;
房源价格与卧室数、洗浴室数以及建筑面积成正相关的关系。
3)得房率
整体得房率≈ 0.16,可用面积相对较低,体现该地区房源的占地面积较大,购买房源或可拥有大面积院落;
4)房价与房龄的相关性
房源价格前十的房龄,主要集中于两个区间:90年代初期与2015年(取数时间近期);
有历史的房源和新建成的房源,一定程度上可以卖的上好价钱。
5)房屋实看数
房源实看数最高为4次,此类房源的平均价格为1463711美金;
高房价房源的实看数均较高,看房行为并不能代表最终成交,具体成交数据还有待进一步挖掘。