文章目录
?哈希表(Java实现)
?哈希表定义
哈希表
(hash table,也叫散列表),是根据关键码值(
key value
)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫
散列函数
,存放记录的数组叫
散列表
。
哈希表可以提供快速的插入和查找工作,哈希表运算的非常快,而且编程实现也比较容易。哈希表是数组和链表结构。
?哈希表的内存结构示意图
在散列表中,不像普通数组,每个格子里存放的是一个单一的数据,而是在每一个格子中存放的是一个链表。如图:
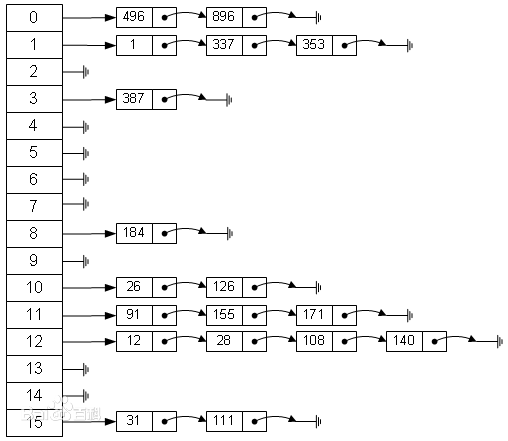
?哈希表存储示意
哈希表
是根据关键码值(
key value
)而直接进行访问的数据结构,通过一个散列函数来将
码、键
进行映射。所以我们需要提前编写一个规则,即函数
y = f(key);
在存储和访问时,我们通过k进行计算,得到一个位置来进行存储或访问。
举个例子,如下一个简单的哈希表,我们给出一个关于取模操作的散列函数
y = f(key) = key % 5

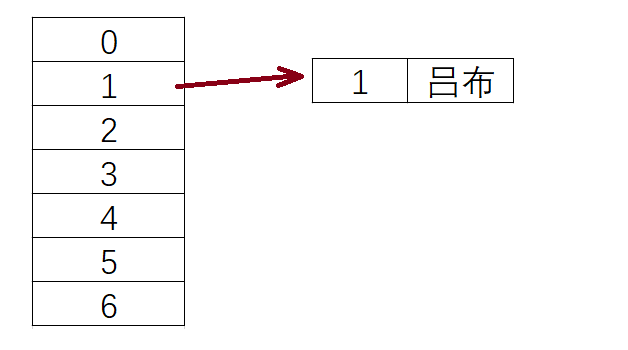
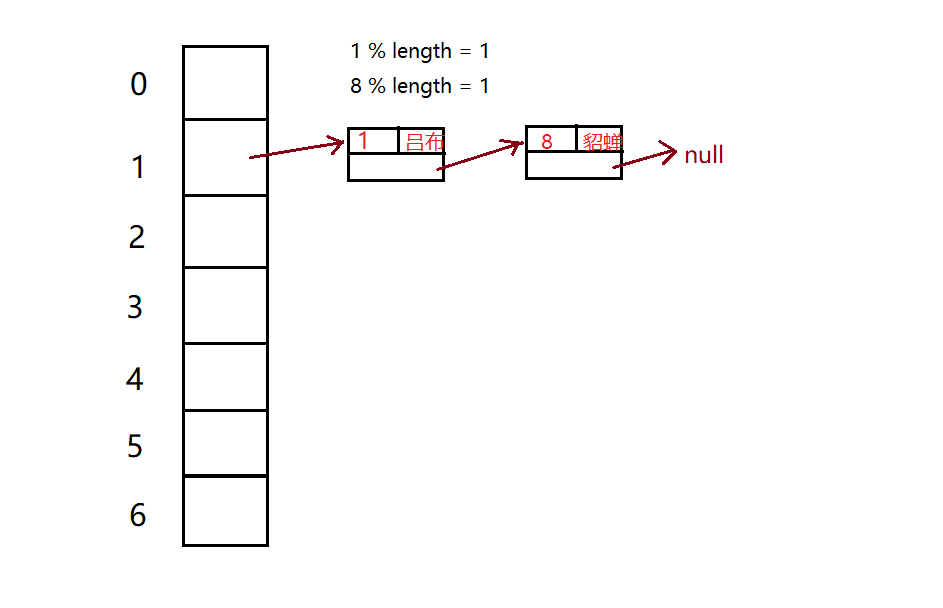
现在我们需要插入员工的信息,以员工的编号作为key值,比如我们先插入
(1,吕布)
员工,经过散列函数计算,
1 % 7 = 1
,所以我们要将该数据插入到数组下标为1的位置去。
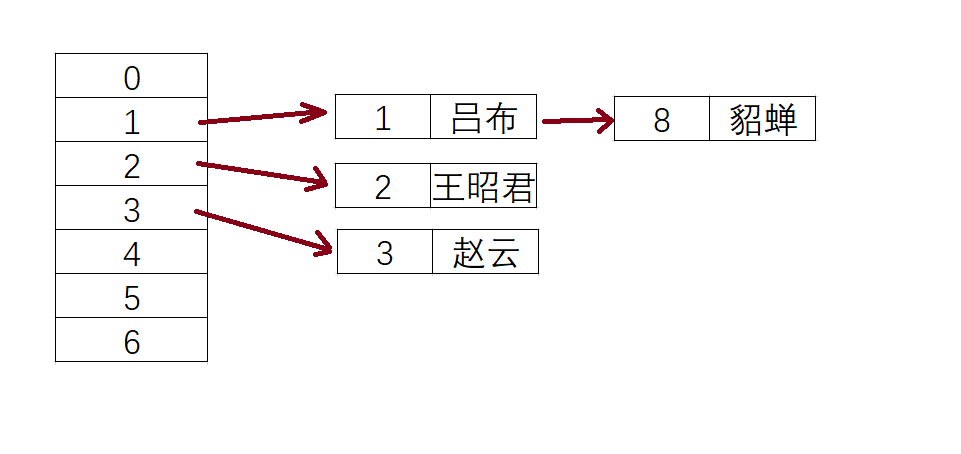
同理,我们也将
(2,王昭君),(3,赵云),(8,貂蝉)
数据插入到哈希表中。
?代码演示
?项目背景
有一个公司,当有新的员工来报道时,要求将该员工的信息加入(id,姓名),当输入该员工的id时,要求可以查到该员工的所有信息。
要求:
不使用数据库,尽量节省内存,速度越快越好(哈希表)。
?员工Emp类
public class Emp {
private int id;
private String name;
private Emp next;
public Emp(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public Emp getNext() {
return next;
}
public void setNext(Emp next) {
this.next = next;
}
}
?链表结构EmpLinkedList类
包含add添加员工操作,list显示员工信息操作,findEmpById查找员工操作,deleteEmp删除员工操作。
public class EmpLinkedList {
private Emp head;
//添加员工
public void add(Emp emp) {
//添加的是第一个员工
if (head == null) {
head = emp;
return;
}
//添加的不是第一个员工
Emp curemp = head;
while (true) {
if (curemp.getNext() == null) {
break;
}
curemp = curemp.getNext();
}
curemp.setNext(emp);
}
//遍历链表的雇员信息
public void list(int no) {
if (head == null) {
System.out.println("第" + (no + 1) +"条链表为空");
return;
}
Emp curemp = head;
System.out.print("第" + (no + 1) +"条链表信息为:");
while (true) {
System.out.printf("员工id:%d\t 员工姓名:%s\t",curemp.getId(),curemp.getName());
if (curemp.getNext() == null) {
break;
}
curemp = curemp.getNext();
}
System.out.println();
}
//通过员工编号查找员工
public Emp findEmpById(int id) {
if (head == null) {
System.out.println("链表为null");
return null;
}
Emp curemp = head;
while(true) {
if (curemp.getId() == id) {
return curemp;
}
if (curemp.getNext() == null) {
curemp = null;
break;
}
curemp = curemp.getNext();
}
return curemp;
}
//通过员工编号删除员工
public boolean deleteEmp(int id) {
if (head == null) {
return false;
}
if (head.getNext() == null && head.getId() == id) {
head = null;
return true;
}
Emp curemp = head;
while(true) {
if (curemp.getNext().getId() == id) {
curemp.setNext(curemp.getNext().getNext());
return true;
}
if (curemp.getNext().getNext() == null) {
break;
}
}
return false;
}
}
?HashTab类
public class HashTab {
private EmpLinkedList[] empLinkedListArray;
int size;
public HashTab(int size) {
this.size = size;
empLinkedListArray = new EmpLinkedList[size];
for (int i = 0;i < size;i++) {
empLinkedListArray[i] = new EmpLinkedList();
}
}
//添加雇员
public void add(Emp emp) {
int emplinkedListArrayNo = hashFun(emp.getId());
empLinkedListArray[emplinkedListArrayNo].add(emp);
}
//遍历所有的链表
public void list() {
for (int i = 0; i < size; i++) {
empLinkedListArray[i].list(i);
}
}
//查找
public void findEmpById(int id) {
int emplinkedListArrayNo = hashFun(id);
Emp emp = empLinkedListArray[emplinkedListArrayNo].findEmpById(id);
if (emp == null) {
System.out.println("没有找到~~");
}else {
System.out.printf("找到了,在第%d条链表中,id = %d",emplinkedListArrayNo + 1,id);
}
System.out.println();
}
//删除员工
public void deleteEmp(int id) {
int emplinkedListArrayNo = hashFun(id);
boolean res = empLinkedListArray[emplinkedListArrayNo].deleteEmp(id);
if (res) {
System.out.println("删除成功");
}else {
System.out.println("没有此员工");
}
}
//散列函数 取模法
public int hashFun(int id) {
return id % size;
}
}
?哈希表测试类HashTabDemo
import java.util.Scanner;
public class HashTabDemo {
public static void main(String[] args) {
HashTab hashTab = new HashTab(7);
int key = -1;
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.println("--------1.添加雇员-----------");
System.out.println("--------2.显示雇员-----------");
System.out.println("--------3.查找雇员-----------");
System.out.println("--------4.删除雇员-----------");
System.out.println("--------0.退出系统-----------");
key = scanner.nextInt();
switch (key) {
case 1:
System.out.println("请输入雇员id");
int id = scanner.nextInt();
System.out.println("请输入雇员姓名");
String name = scanner.next();
Emp emp = new Emp(id, name);
hashTab.add(emp);
break;
case 2:
hashTab.list();
break;
case 3:
System.out.println("请输入要查找的员工编号");
id = scanner.nextInt();
hashTab.findEmpById(id);
break;
case 4:
System.out.println("请输入要删除的员工编号");
id = scanner.nextInt();
hashTab.deleteEmp(id);
break;
case 0:
scanner.close();
System.exit(0);
break;
}
}
}
}
?结果演示

?哈希算法
?哈希算法定义
由于哈希算法被计算的数据是无限的,而计算后的结果范围有限,因此总会存在不同的数据经过计算后得到的值相同(两个不同的数据计算后的结果一样)。当我们对某个元素进行哈希运算,得到一个存储地址,然后根据地址进行元素的存储操作。
?哈希碰撞定义
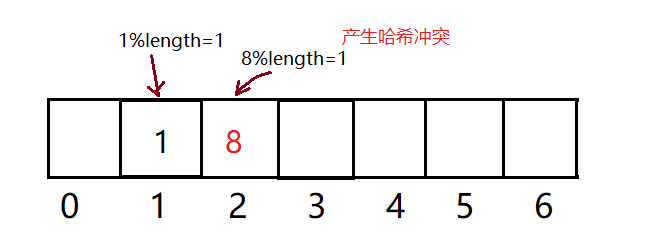
要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。哈希函数的设计至关重要,好的哈希函数会尽可能地保证计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?
?解决哈希碰撞的方式
?线性探测法
⛵思想
主要根据
index = val.hashcode()%element.length
来解决哈希冲突问题。从数组当前位置(hashcode())开始,找到下一个空位置,进行存放。当数组填充满之后,进行数组的扩容操作,继续存放值。存储的键值对中键相等进行值的覆盖操作。进行扩容后的操作,还得进行元素的重新哈希操作。
?代码实现
import java.util.Arrays;
import java.util.Map;
//线性探测法
public class LineHashMap<K extends Comparable<K>, V extends Comparable<K>> {
private static final double LOAD_FACTOR = 0.75;//扩容因子
private static final int INIT_CAPACITY = 1 << 4;//默认初始化大小 16
private Entry<K, V>[] table;
private int size;//有效个数
public LineHashMap() {
table = new Entry[INIT_CAPACITY];
this.size = 0;
}
public V get(K key) {//有数据 index key 相等 2.有数据 发生冲突 3.没有该数据
int index = key.hashCode() % table.length;
//如果发生哈希冲突
if (table[index].key.compareTo(key) != 0) { //对象比较方式?
int count = 0;
int i = index;
for (; table != null && table[index].key.compareTo(key) != 0; i = ++i % table.length) {
// count++;
// if (count == table.length) {
// System.out.println("没有该数据");
// return null;
// }
}
return table[i].value == null ? null : table[i].value;
}
return table[index].value;
}
public void rehash() {
if ((double) size / table.length >= LOAD_FACTOR) {
Entry<K, V>[] newtable = new Entry[table.length << 1];
for (int i = 0; i < table.length; i++) {
int index = table[i].key.hashCode() % newtable.length;
if (table[i] != null) {
if (newtable[index] == null) {
newtable[index] = table[i];
} else {
int j = index;
for (; newtable[j] != null; j = ++j % newtable.length) {
}
newtable[j] = table[i];
}
}
}
table = newtable;
}
}
public void put(K key, V value) {
rehash();
Entry<K, V> entry = new Entry<>(key, value);
//需要将entry 放置到下标index = entry.key.hashcode() % table.length
int index = entry.key.hashCode() % table.length;
if (table[index] == null) {
table[index] = entry;
} else {
int j = index;
for (; table[j] != null; j = ++j % table.length) {
}
table[j] = entry;
}
size++;
}
//Entry 静态内部类
static class Entry<K, V> implements Map.Entry<K, V> {
private K key;
private V value;
public Entry(K key, V value) {
this.key = key;
this.value = value;
}
@Override
public K getKey() {
return null;
}
@Override
public V getValue() {
return null;
}
@Override
public V setValue(V value) {
return null;
}
}
}
?链地址法
线性探测法当产生哈希冲突的键值对越多,遍历数组的次数就会越多。为了解决这个问题,我们采用数组和链表结合的方式,数组元素是一个链表结构,产生哈希冲突,在相同的索引下标下进行链表的插入操作。
?️思想
不足:
① 链地址法存在的不足在于,当产生哈希冲突的节点越多,那么数组索引下标查找就会变成链表的遍历操作。数组的优势在于随机取值,时间复杂度达到O(1),而链表的查找时间效率达到O(n)。
② 当产生数组扩容时,所有的元素节点都必须进行重新哈希。
?️代码实现
import java.util.Map;
public class MyLinkedHashMap<K,V> {
private static final int INIT_CAPACITY = 1 << 14;
private static final double LOAD_FACTOR = 0.75;
private Node<K,V>[] table;
private int size;//有效个数,数组被占个数
public MyLinkedHashMap() {
table = new Node[INIT_CAPACITY];
}
public void rehash() {
//扩容
if ((float)size / table.length >= LOAD_FACTOR) {
Node<K,V>[] newtable = new Node[table.length << 1];
size = 0;
for (int i = 0;i < table.length;i++) {
if (table[i] != null) {
Node<K,V> p = table[i];
for (;p != null; p = p.next) {
// int index = p.n_value.key.hashCode() % newtable.length;
// if (newtable[index] != null) {
// p.next = newtable[index];
// p = newtable[index];
// }else {
// newtable[index] = p;
// }
put(p.n_value.key,p.n_value.e_value);
}
}
}
table = newtable;
}
}
public void put(K key,V val) {
rehash();
Node<K,V> node = new Node<>(key,val,null);
//扩容?重新哈希
rehash();
int index = key.hashCode() % table.length;
if (table[index] != null) {
node.next = table[index];
table[index] = node;
}else {
table[index] = node;
}
size++;
}
// public V get(K key) {
// int index = key.hashCode() % hashCode();
// if (table[index] == null) {
// System.out.println("没有该值");
// return null;
// }
// }
static class Node<K,V> {
Entry<K,V> n_value;
Node<K,V> next;
public Node(K key,V value, Node<K, V> next) {
this.n_value = new Entry<>(key,value);
this.next = next;
}
}
static class Entry<K, V> { //键值对
private K key;
private V e_value;
public Entry(K key, V value) {
this.key = key;
this.e_value = value;
}
}
}