LinuxTCP拥塞控制-Congestion Control In LinuxTCP-拥塞状态机(一)
摘要这篇文章描述了LinuxTCP设计的基础,集中讨论拥塞控制算法。LinuxTCP支持SACK,时间戳,拥塞感知,撤销调整拥塞窗口等技术等。
为了提高TCP性能,Linux的代码实现比IETF标准规定的走出更远,可能有很多细节不同。我们将针对这些不同的东西进行讨论,看看采用了quickack、速率减半、拥塞窗口调整撤销等算法的Linux实现和不采用这些算法实现的情况有多大的性能差异。
1.简介
TCP已经走过了20年,并成为最受欢迎的传输层协议。它的特色在于拥塞控制算法,该算法规定,在发送端得知丢包的情况下应该减速,因为这种丢包可能是路由器拥塞引起的。
Linux作为生命力强劲的开源系统,得到众多工作者的代码贡献。但是,阅读源码总是枯燥。本文描述linux2.4内核的TCP设计原则。LinuxTCP的实现和其它系统有所不同。
IETF的RFC文档中有几十份关于TCP的内容,此外,为了提高特定场景的TCP性能,TCP实现方面有所增加。
实现兼容性较好的TCP不是一件容易的事。比如,RFC最初规定了TCP拥塞控制算法的框架,如果TCP实现要在此基础上支持SACKS,那么代码会和RFC规定的有所不同。完全按照RFC编写兼容联众算法的代码会十分繁杂。
我们将揭示LINUXTCP实现的方法,LinuxTCP通过一个拥塞状态机来实现大多数RFC规定的算法,SACK和TCPreno共用大部分代码。为了提高性能,LinuxTCP改善了许多标准。本文的目标是指出LinuxTCP和传统TCP实现以及RFC有何不同。
2.TCP Basics
我们将简要描述TCP拥塞控制算法,实际上,为了提高TCP性能,关于RFC标准的改进已经提出了很多。我们挑选最重要的部分进行讨论。
2.1 TCP拥塞控制
TCP Basics在RFC 793【引 1】中定义,为了应对主机数量急剧增长带来的拥塞问题,Jacobson提出了拥塞控制,后来被RFC采纳。
TCP使用拥塞窗口cwnd来限制发送速率,cwnd被初始化为1或2,最初,TCP每收到一个ACK,cwnd加1,这就是慢启动,cwnd达到ssthresh阈值限制后,转入拥塞避免阶段,每个RTT增加1。
TCP通过收到重复ACK来感知拥塞,当接收端收到了乱序段,就会发送连续的重复ACK。发送端重传丢失的段,并将阈值设置为当前已经发送数据的一半,cwnd设置为阈值加3,这是根据已经发送的段数和收到的重复ACK数目决定的。【注 1】
由收到重复ACK引起的重传称为快速重传。在快速重传之后,TCP发送端进入快速恢复,直到上一个窗口的所有段都被确认了。在快速恢复阶段,TCP发送端在cwnd允许的前提下,维持包守恒策略,即收到一个ACK,发送一个数据包。有时,为了重传数据包,cwnd可能短暂增长,每收到一个重复ACK加1【注 2】。在退出快速恢复阶段时,cwnd还原为进入此阶段的值【注 3】。
IETF提供了两个快速恢复变体,标准版会在收到窗口更新ACK【注 4】之后退出快速恢复。但是,如果同一个窗口之内有多于一个数据段丢失,标准版就不能有效工作【注 5】。为了提高TCP性能,一种称为TCP NewReno的变体被提出。NewReno退出快速恢复的时机是上一个窗口的所有数据段都被确认【注 6】。
重传也可以被重传定时器触发。如果发送端长时间没有收到确认新数据的ACK,重传定时器就会超时。RTO可以作为丢包指示,并触发未确认数据段的重传。另外,在RTO发生时,发送端将窗口调整为一个数据段,因为RTO可能表征着网络状况发生了剧烈变化。
TCP发送端定期测量RTT并计算RTO,RTT测量算法如下:
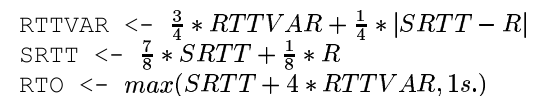
R是测量到的往返时间,RTTVAR是当前RTT的表征,SRTT是对当前RTT平滑处理的值【注 7】。
2.2 增强
标准TCP从丢包中恢复的效率很低,因为累积ACK的机制在一个RTT内只允许重传一个段【注 8】。
因此,SACK选择性确认被提出来。SACK能表明多个分散段的丢失【注 9】,从而允许发送端一次重传更多的段。SACK需要受到两端主机的支持。
SACK能帮助发送端进行更精确的拥塞控制,而不是短暂调整拥塞窗口。发送端能跟踪已经发送的数据并和当前窗口进行比较,以确定是否能发送新段。但是用未确认数据段来定量outstanding data时,策略有所不同。IETF提出的保守策略是,将所有未确认数据段当做outstanding【注 10】。FACK算法采取激进策略,将所有SACK的未确认区间当做丢失段。虽然这种策略通常带来更佳的网络性能,但是过于激进,因为SACK未确认的区间段可能只是发送了重排,而并非丢失【注 11】。SACK也能用于报告虚假重传,DSACK技术使得接收端可以使用SACK通告它收到的重复段。有了这个信息,发送端就知道自己是否不必要地降低了拥塞控制参数,并将参数调整到重传之前的值。例如,包重排是不必要重传的潜在原因,因为乱序的段会触发dup ACKs。
TCP 时间戳选项可用于精准的RTT测量,尤其是在高带宽时延积的链路上。每个包都有相应的时间戳,并通过ACK回显给发送端。发送端从而可以测量精确的RTT并用于定时器。更加精确的测量需要排除旧数据段的时间戳。
时间戳也可用于探测不必要的重传,Eifel算法说明了这一点:如果对于重传段的确认回显了一个时间错,而这个值比发送端存储的值要早【注 12】,那就表明最初的数据段已经达到了发送端,重传是不必要的,发送端应该将参数调整回重传前的值。
以上讲的这些措施多半通过丢包探知拥
塞,除此之外,还有一种重要的方法:ECN,显式拥塞通知。在交换机、路由器发生了拥塞时,可以在数据包上打标记,当TCP发送端从接收端获得了带有ECN标记的包时,就会调整发送速率以降低拥塞。ECN让发送端在丢包之前就得知拥塞,显然是有利于网络的【注 13】。
2.3 评价
IETF标准的某些细节在实现中有问题,许多RFC文档规定了一整套用于实现的算法,但是混合这些算法往往带来不便。比如同时使用SACK和TCP NewReno会带来某些问题,变量和算法框架不尽相同。
TCP拥塞控制算法在快速恢复阶段可能会增加拥塞窗口,以便发送包,保持outstanding包数目稳定。因而,快速恢复期间拥塞窗口的大小没有如实反映允许outstanding的数据包【注 14】。
当快速恢复结束时,cwnd调整为合适的值,这个步骤是必要的,因为拥塞窗口的值应该用SND.NXT和SND.UNA来表征。通过精细测量outstanding数据段,cwnd可以维系于和网络相关的合适值。
调整拥塞窗口的算法一贯是个问题,有了SACK之后更是如此,为了保持代码一致性,需要为SACK和非SACK的TCP设计通用的变量和框架。
最后,上面提到过的RTO算法受到了质疑。很多网络的延时是几十ms,最小RTO限制为1s,并不会给TCP性能带来太大问题。但是,在高延迟网络中,RTO的策略至关重要【注 15】。例如RTT突然变小时,因为RTT系数的不同,RTO可能保持为过大的值。而当cwnd增长进入了平缓阶段时,可能是RTT系数导致RTO增长不够快。这可能会导致虚假重传。也有其他可选的RTO定时器,比如Eifel重传定时器,克服了标准RTO定时器的弱点。但是,它引入了复杂的计算式,因而难以实现【注 16】。
文章比较长,先翻译到第二部分,或有错讹,还望指出。转载请注明出处。
引用:
【1】 http://blog.csdn.net/dlmu2001/article/details/1184366 RFC 793 TCP 中文翻译
注:
【1】 实际上,加三是合理的,因为ACK由数据段驱动,三个重复ACK代表网络总能容纳三个段。但是减半通常被认为是过于激进的策略,很多新的算法不这样做。
【2】 某些情况下,cwnd可能不够大,以至于重传的数据段不能发送。这时需要增加cwnd,但并不一定是每收到一个重复ACK就加1,关于这一部分代码,下一篇博文会讲。
【3】 拥塞窗口调整撤销,快速恢复是一个短暂状态。
【4】 有些ACK能更新滑动窗口,有些不能,确认了滑动窗口左边seq的ACK都是oldack,不能更新当前滑动窗口。
【5】 有丢包就会引起降窗,无论处于哪个阶段。这里说标准版在此情况下不能有效工作,不知何意,有待后续博文讨论。
【6】 NewReno维持快速恢复的时间显然更长,在此期间,一直执行包守恒策略,偶有窗口提升也是为了重传包。实际上,在此阶段cwnd一般较低。【5】中说的性能下降可能是退出时机不对,导致cwnd不合时宜地降低或增加。
【7】 这部分代码在内核中很容易找,为了方便初学者,后续博文还是会讲解一下。
【8】 这句话不是从发送端角度理解的,应该从接收端考虑,累积ACK没有SACK那么强大,实际上只能表明一个段的丢失,所以重传也只能是一个段。
【9】 一个SACK最多可以表示四个区间段的丢失,参加另一篇博文:SACK包格式。
【10】 这里outstanding原意为“未偿付的”,可以理解为还没有确认的,即in_flight的包。
【11】 实际上,过多的不必要重传会引起网络负担,参见博文:增大拥塞窗口的优劣。
【12】 时间戳并不等同于时间,在网咯中做时间同步是吃力不讨好的事情。关于时间戳的作用和意义,后续博文会讲。
【13】 除了ECN,还有其他的通知方式,比如直接向发送端通知拥塞。遗憾的是,ECN并未得到广泛支持。关于交换机如何判定拥塞,也有不同的算法,比如常见的队尾丢弃和RED,早期队列丢弃。这并不是一个简单的问题,后续会尝试说明。
【14】 快速恢复期间,有时为了重传,在cwnd不够时需要增加。这种情况一般是暂时的,而增大了的cwnd不会减少,因此不能准确反映outstanding的包数。退出快速恢复,cwnd会重新调整,关于这部分需要详细讨论和阅读源码。
【15】 不合适的RTO可能导致过多的沉默时段,例如,重传丢包发生时,在高延迟网络中有很长一段时间,发送端没有收到信息,保持沉默,吞吐量迅速降低。
【16】 例如,引入了浮点和非四则运算的算法,虽然看起来可能很漂亮,但是不实用,因为Linux内核对float的支持并不好,简单的除法都需要通过整数模拟实现。