前面我们讲了链表这种数据结构,相比于数组的好处是对元素在增删场景效率特别高,弥补了数组新增和删除效率极低的缺陷。同样链表也存在自己致命的缺陷,那就是查询和修改效率太低。其实数组和链表这两种数据结构刚好是互补的,只是前者的优点是后者的缺点,而后者的优点是前者的缺点。可以看出对这两种结构而言,并不是尽善尽美的,我们只能根据自己开发的场景选择其中最符合我们设计的数据结构。那么问题来了,有没有一种数据结构,能够充分利用这两者的优点,各取所长了。答案肯定是存在的,比如哈希表、树以及图等。今天咱们讲其中一种新的数据结构,那就是哈希表。
哈希表这个词,我相信学Java的小伙伴都并不会陌生。像咱们面试必问的HashMap、HashSet等等,我相信大家都或多或少会有一定的印象。相信不少同学在面试的时候都会被这个知识点折磨得痛不欲生,头疼不已。已经预想到很多同学在为面试做准备,咱们问一下自己,你是在没日没夜的copy那些就像厕所里的石头,又臭又硬,没有一点作用和效率的空泛理论?是在浪费自己的时间在循环那些背了又忘,忘了又背,狗都不背只为博得一点混进职场的运气呢?还是在研究逻辑,把最底层的知识一步一步融会贯通,成为那个不用再辛辛苦苦背理论,对所有知识不仅知其然,更能知其所以然呢?像咱们的HashMap,夺命四连问,什么是无序不可重复性?无序不可重复性的实现原理?怎么解决JDK1.7单链表死循环问题?HashMap的扩容机制等等。你又能清楚多少呢?
所以呢,为了帮助大家更好的理解集合框架,也或者是加深咱们对底层知识的理解,我们在今天使用哈希表简单的实现一个HashMap,让咱们以后面对这个知识点,就相当于常识一样,成为简单不能再简单的问题。
01 什么是哈希表?
哈希表是一种数据结构,但并不是像数组和链表一样是一种独立的结构,它是对链表和数组取长补短,复合而成的一种数据结构,也就是哈希表 = 数组 + 链表。说白了哈希表就是数组,只不过它里面的每一项元素放得是链表,即哈希表 = 链表数组。
说起哈希表的由来,我们不得不再来聊一下数组和链表这两种单体结构各自的优点。
NO.
1 数组
![]()
这是我们再熟悉不过的数组结构,我们都知道数组是连续的,也就是它存储的元素在内存分配是紧密相连的,我们访问某个元素,直接可以通过内存地址去访问,从而避免了 一次一次的去和数组里面的元素比对的过程。我们都知道比对的过程是极其不确定的,最好的情况要查找的元素就在数组索引为0的位置,时间复杂度为o(1),最坏的肯定就是目标元素在数组最后位置。假设数组长度为n,比对次数就是n,时间复杂度为o(n) 。所以直接能够通过内存去确定元素所在内存地址,是一种时间复杂度能够达到o(1)的高效方法,以下是数组的查询算法,进一步能够让我们理解数组的工作原理,让我们理解数组为什么访问效率那么高。

以上是一个长度为9的整数数组,数组的内存地址,也就是第一个元素的地址为1035。因为在Java中,一个int占四个字节,所以我们访问第二个元素时,它的内存地址为1035 + (4 * 1) = 1039,同理第八个元素的内存地址为1035 + (4 * 7) = 1063,时间复杂度为o(1)。
当然呢,这是访问确定元素,如果非确定元素,咱们的数组也提供了一些效率较高的查询算法,比如对有序数组,常见的二分查找就是一个查询效率很高的算法:

NO.2 链表
用最简单的单链表举例子,链表这种数据结构效率最高的就是新增和删除,时间复杂度能够达到最理想的o(1)。

无论是新增和删除,我们只需要找到目标结点的上一结点,修改该结点的next域即可。
NO.3 哈希表的由来
考虑到数组和链表都是两种极端的数据结构,一个查询修改快,一个新增删除极快。而哈希表则是结合两者的优点复合而来的的数据结构,无论是新增删除,还是查询修改,都能够达到很高的效率,下面我们来看一下哈希表的内存结构图:
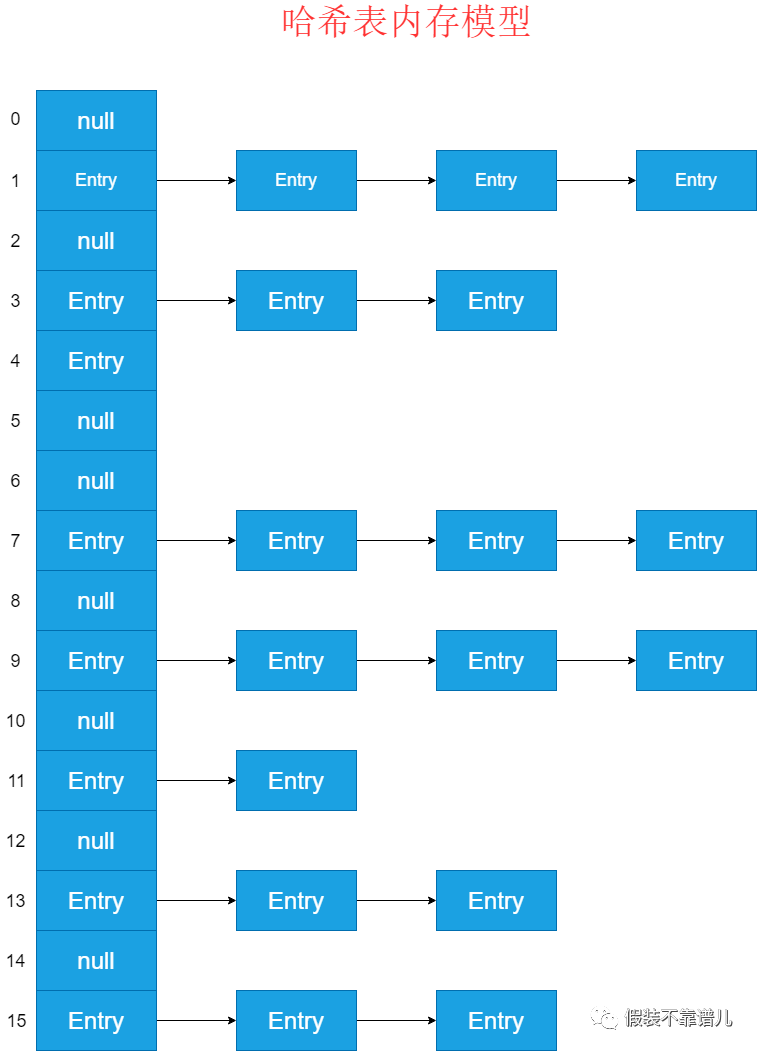
以上就是哈希表的内存模型,说到底就是一个链表数组,它的设计思路和数组的思路类似,希望我们操作结点时,能够绕过比对步骤,直接或者间接通过内存地址定位到该结点。元素所在内存地址跟目标元素存在一个函数关系。举个例子来说我们查询数组某个索引元素时,我们只需要通过首地址 + (n – 1) * 元素长度即可。而在哈希表中,这个映射关系提供了专门的Hash算法。为了进一步熟悉哈希表,我们来实现一个HashMap。
02 哈希表的实现
下面我们用最流行的Java语言完成哈希表的实现,通过手写一个JDK7对应的HashMap更进一步理解哈希表的实质,至于8以后的,我们放在将树讲完以后进行完善。
NO.1 结点的定义
哈希表最小的存储单元跟链表一样,叫做一个结点,使用一个Entry表示:
package com.ignorance.node;
import java.util.Objects;
/**
* @author :陈海江
* @descript:结点Entry
* @date:2022/07/29
* @param <K>
* @param <V>
*/
public class Entry<K,V> {
private int hash;
private K key;
private V value;
public Entry<K,V> next;
public Entry() {
}
public Entry(K key, V value) {
this.hash = key.hashCode();
this.key = key;
this.value = value;
}
public int getHash() {
return hash;
}
public void setHash(int hash) {
this.hash = hash;
}
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
@Override
public String toString() {
return “Entry{” +
“key=” + key +
“, value=” + value +
‘}’;
}
}
一个Entry对象表示咱们哈希表中的一个结点,hash表示当前Entry对象key所对应的hash码,主要用来计算咱们的结点在哈希表中的存储位置,key为键,主要模拟HashMap通过键来查找value,next为指针域,表示该结点在所属链表的下一个位置。
NO.2 HashTab类的定义
研究完哈希表的内存结构,可以发现底层就是链表数组。
对此,我们定义一个类型为Entry的链表数组,用于存储咱们的结点数据:
package com.ignorance.hash;
import com.ignorance.node.Entry;
/**
* @author :陈海江
* @descript:哈希表实现类
* @date:2022/07/29
* @param <K>
* @param <V>
*/
public class HashTab<K,V> {
//底层存储元素数组
private Entry[] tables;
//数组初始长度
private static final int DEFAULT_SIZE = 16;
//默认扩容因子
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
//数组实际长度
private int actualSize;
//实际扩容因子
private float actualLoadFactor;
//结点个数
private int size;
public HashTab() {
this.tables = new Entry[DEFAULT_SIZE];
this.actualSize = DEFAULT_SIZE;
this.actualLoadFactor = DEFAULT_LOAD_FACTOR;
}
}
HashTab对应咱们哈希表主要的实现类,其中tables为一个链表数组,是咱们哈希表的主要存储结构。DEFAULT_SIZE为咱们数组的初始长度,actualSize为底层数组的实际长度,size用来记录咱们哈希表中真正存储的有效结点个数。DEFAULT_LOAD_FACTOR为底层数组的默认扩容因子,actualLoadFactor为咱们哈希表的实际扩容因子,咱们等下再说这两个变量的作用。
NO.3 结点新增
要说起一种数据结构,增删改查必不可少,尤其对于哈希表来说,新增功能是哈希表最核心的功能,下面咱们来分析一下哈希表的新增过程。
当咱们调用HashTab的构造方法时,堆内存会创建一个长度为16的Entry数组,如下图所示:

当我们new HashTab()后,会将咱们的tables初始化为能够存16个Entry的数组。这时候数组的每个元素都为空,大家学过数组也都知道,我们的元素是以索引的方式加入到数组上面的。那现在tables有16个位置,我们第一个元素应该放在哪个位置呢?相信很多同学根据经验都会说放在索引为0的位置,但是答案是错的。这也是咱们哈希表最独特的地方。我们都说哈希表利用了数组通过计算元素地址值的方式去查找相应元素,从而让咱们的查询达到较高的效率。所以呢,咱们添加元素时需要定义一个规则,来计算出咱们当前元素放在哈希表的对应位置。
1.无序性的原理
那么这个规则,是什么呢?那就是咱们要添加的元素本身要重写hashcode()方法,这个方法有什么作用了,在咱们jdk设计时,专门提供了这个方法让咱们根据自己的需要来拓展它。它的目的是将咱们一个对象根据不同的内容映射出一个对应的整数,类似咱们学习字符时,一个字符对应一个数字表示的unicode编码一般。通俗一点,就是给我一个对象只要内容不同,他对应的hashcode()算出的整数也应该不同,当然也可能出现不同内容有hashcode相等的时候,但是一个好的hash算法,是不应该出现这种情况的。下面我们来研究一下这个方法,看看它表示的什么意思:
package com.ignorance.bean;
import java.util.HashMap;
import java.util.Objects;
/**
* @author :陈海江
* @descript:Student类
* @date:2022/07/29
*
*/
public class Student {
private Integer id;
private String name;
private String gender;
private Integer age;
public Student(Integer id, String name, String gender, Integer age) {
this.id = id;
this.name = name;
this.gender = gender;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return id.equals(student.id) &&
name.equals(student.name) &&
gender.equals(student.gender) &&
age.equals(student.age);
}
@Override
public int hashCode() {
return super.hashCode();
}
}
定义Student类,并且重写hashcode()以及equals()方法,咱们重点来测试hashcode()方法:
package com.ignorance.test;
import com.ignorance.bean.Student;
import org.junit.Test;
/**
* @author :陈海江
* @descript:hashcode()测试
* @date:2022/07/29
*
*/
public class HashCodeTest {
@Test
public void testHashCode(){
String str = “周芷若”;
System.out.println(str.hashCode());
Integer num = 118;
System.out.println(num.hashCode());
Student student = new Student(1001,”周芷若”,”女”,21);
Student student1 = new Student(1002,”张无忌”,”男”,22);
System.out.println(student.hashCode());
System.out.println(student1.hashCode());
}
}
在该测试类中,咱们定义了四个对象,一个String、一个Integer,还有两个属性值不同的Student对象student以及student1,咱们看一下它们所对应的hashcode值:

可以看出不同对象它们所对应的hash值都是一个整数,并且都不相等,那么这个东西有什么用呢?咱们再往下看。咱们上面说hashcode()方法是用来计算当前结点在哈希表中的位置,咱们哈希表既然是个长度为16的数组,这个时候又不是从0开始添加元素的,而这一串哈希码又是怎么决定它在数组中的位置呢?这样看肯定看不出,但是我将当前结点的哈希码&15呢?这个时候不管你的哈希码是多少,有多大,最终的结果是不是只能转换成0-15之间的数字了呢?那么0-15不正好是当前Entry数组的索引范围吗?
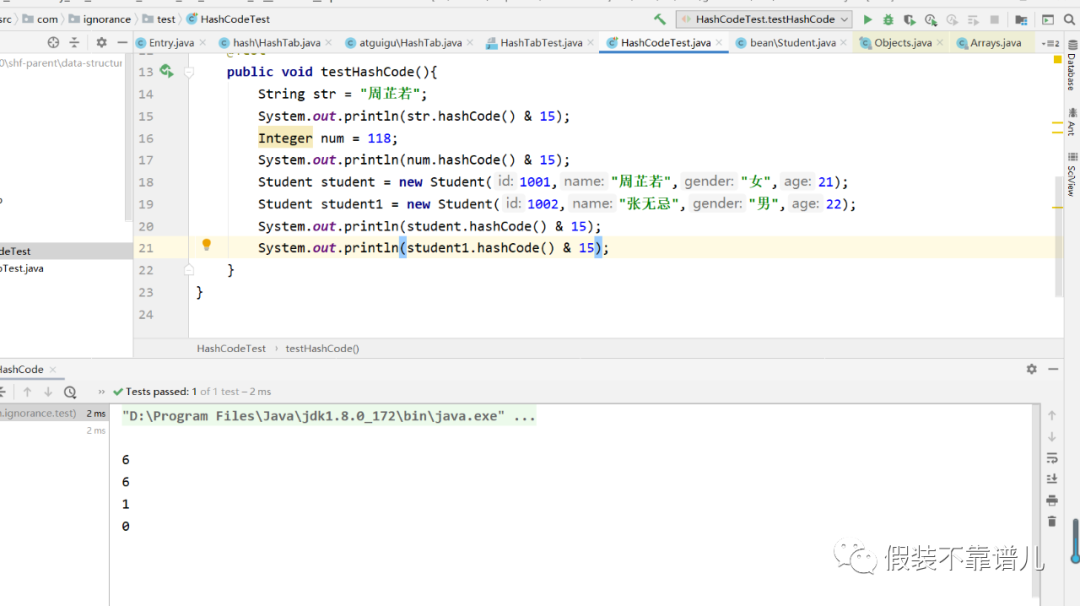
那么这时候我相信一些同学也就有一定思路了,那么第一个算出的是6,就放在数组第7个位置,第三个放在第2个位置,第四个放在第1个位置,那么第二个也是6,第7个位置明明已经有元素,被占用了,那我们应该怎么放呢?没关系,我们接下来一步一步看。
现在咱们写咱们最核心的添加,也就是put方法。
-
通过我们分析的,通过当前Entry的key计算出对应的hashcode;
-
将上一步的哈希值&数组长度 – 1,类似取余操作,这一步是把咱们的hashocode转换到数组的存值范围,如果不在0-15,那是不是就ArrayIndexOutOfBoundException了啊。当时要注意,只有数组长度为2^n时,&运算和取余才等效,其它方式需慎重。
/**
* @descript 通过当前key的hash码计算出在数组的存储位置
* @param hash
* @return
*/
private int calcStoreIndex(int hash){
return hash & actualSize – 1;
}
下一步,我们开始写咱们的put方法:
/**
* put 添加方法
* @param key 键
* @param value 值
* @return
*/
public V put(K key,V value){
//将当前键值对填充为一个Entry,因为咱们的tables数组只能存放Entry结点
Entry<K,V> entry = new Entry<>(key,value);
//计算出当前key对应的hash值
int currentIndex = calcStoreIndex(entry.getHash());
//将当前Entry结点存在table数组
tables[currentIndex] = entry;
return entry.getValue();
}
在put方法中,咱们通过当前Entry的key的hash值计算出咱们的Entry在哈希表中的存储位置,然后将其放在数组对应索引上,但是这样是不是会有很多问题啊,我们不妨来一个一个看:
package com.ignorance.test;
import com.ignorance.hash.HashTab;
import org.junit.Test;
/**
* @descript 哈希表测试类
* @author 陈海江
* @date 2022/7/29
*/
public class HashTabTest {
@Test
public void test01(){
HashTab<Integer,String> hashTab = new HashTab<>();
hashTab.put(20,”周芷若”);
hashTab.put(25,”张无忌”);
hashTab.put(36,”高圆圆”);
hashTab.put(16,”金莎”);
hashTab.put(19,”黄圣依”);
}
}
咱们再写一个最简单的遍历方法,看一下咱们现在哈希表的存储情况:
/**
* 哈希表遍历
*/
public void show(){
Arrays.stream(tables).forEach(System.out::println);
}
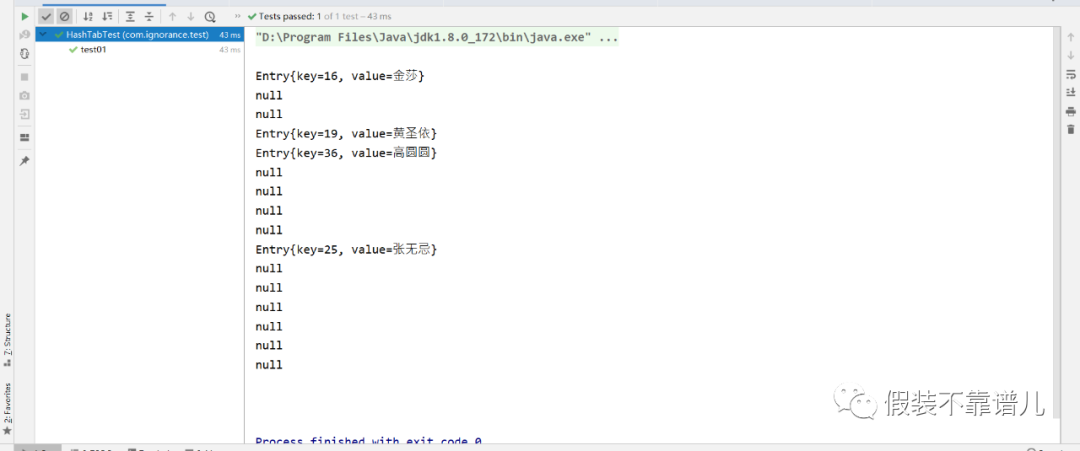
这个结果有没有跟自己想得一样呢?为什么我们put了5个结点,最终在哈希表中只存了4个结点了,有没有发现周芷若是不是不见了啊,那是因为周芷若所对应Entry的key和高圆圆所对应的key算出的索引是同一个,不信咱们看一看:
@Test
public void test01(){
// HashTab<Integer,String> hashTab = new HashTab<>();
// hashTab.put(20,”周芷若”);
// hashTab.put(25,”张无忌”);
// hashTab.put(36,”高圆圆”);
// hashTab.put(16,”金莎”);
// hashTab.put(19,”黄圣依”);
// hashTab.show();
System.out.println(new Integer(20).hashCode() & 15);
System.out.println(new Integer(36).hashCode() & 15);
}
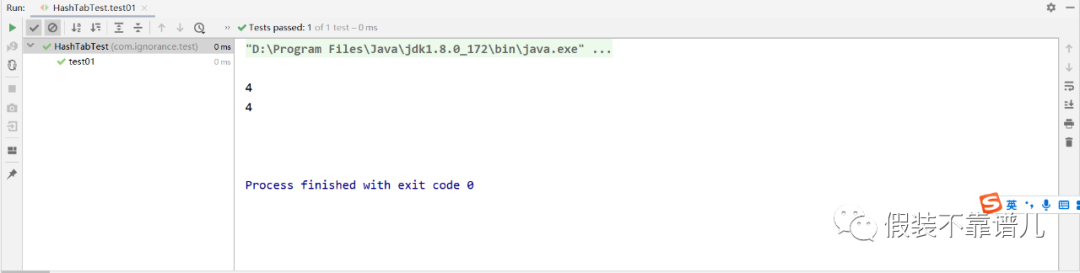
那么它计算出的下标为4,是不是放在咱们tables数组的第5个位置啊,只是咱们现在还没有链表,只要多个下标一样,后者就会把前者覆盖掉。存储过程如下图所示:
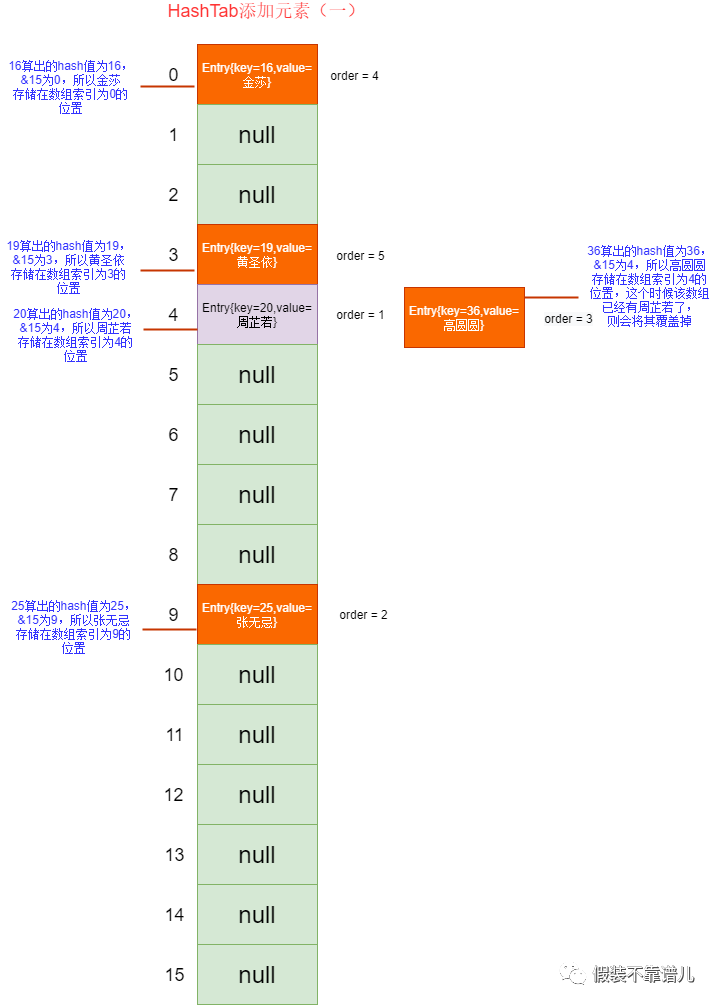
虽然离咱们的目标还远,但是这就是咱们哈希表无序性的原理。什么叫无序性?它指得是咱们向哈希表加入的顺序跟遍历的顺序不一致,比如咱们加的5个结点,加入的顺序是周芷若、张无忌、高圆圆、金莎、黄圣依,但是遍历出来的顺序为金莎、黄圣依、高圆圆、张无忌。我相信同学们都应该清楚其中的道理了,出现这样的结果是因为咱们向数组中加入的标准并不是从数组第一位开始计算的,而是通过咱们的结点的hashcode()方法决定的,每个结点所对应的hash值不一样,可能第一个hashcode & 15得出的下标为10,第二个为0,加入的顺序1->2,但是遍历出来的顺序是从数组前后遍历的,结果为2->1。这也就是HashMap以及hashSet无序性的底层原理,希望同学们一定要理解,无序性是由
hashcode()方法
决定的。
2.不可重复性
接下来咱们实现一下不可重复性。不可重复性的意思是哈希表中不能出现两个相同的结点,怎么判断两个结点是否重复,就像咱们面向对象一样,如果两个内存地址不一样,说明两个对象不相等,后面为了拓展重写equals方法,根据咱们的业务规则进行判断两个对象是否相等。而在哈希表中,不可重复性也是依据equals()方法进行判断的,如果两个结点比较返回true,则表示两个结点相同,后面的结点就不会添加,反之才添加。像咱们前面遇到的问题,如果两个结点通过hashcode()算出的下标值一样,此时数组所对应的链表上面已经存在至少一个结点,这种情况我们叫作哈希冲突或者哈希碰撞。
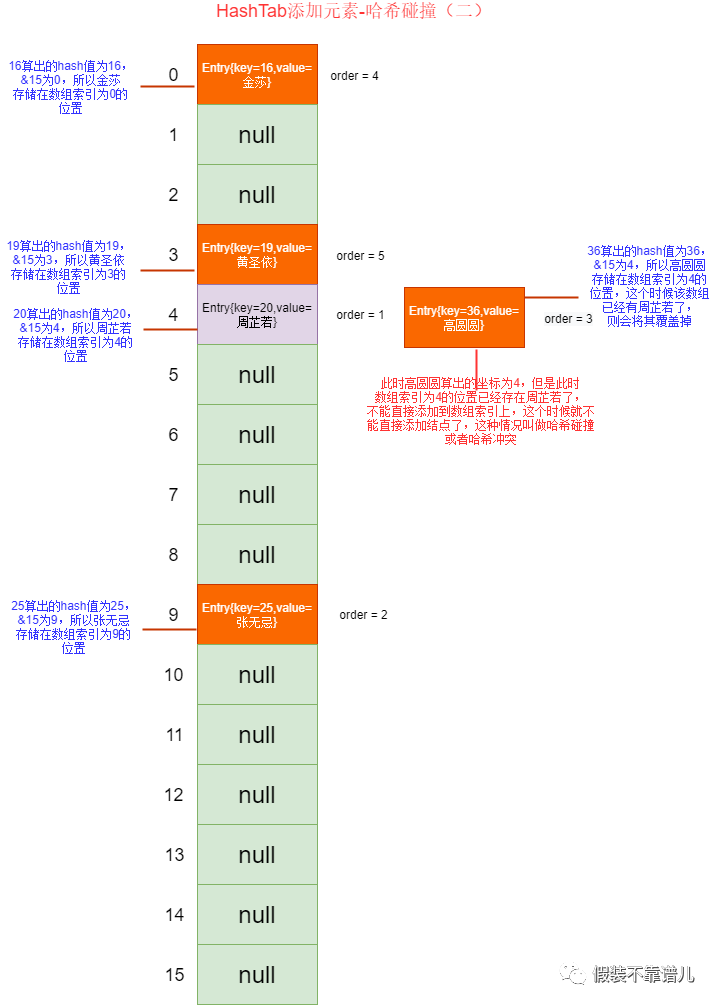
只有出现哈希冲突时,我们才需要考虑重复性的问题,也就是两个结点都落在了同一个位置,这时候发生冲突了,如果通过equals()方法比对返回的是true,则表示两个结点重复,此时不再加入新结点,反之则以链表的方式组织一个索引位置上的多个结点。
我们的哈希表的数组比较特殊,因为数组中的每一个元素又是一个链表,这时候数组的一个位置也叫作一个桶。
下一步,我们继续改造咱们的put方法:
/**
* put 添加方法
* @param key 键
* @param value 值
* @return
*/
public V put(K key,V value){
//将当前键值对填充为一个Entry,因为咱们的tables数组只能存放Entry结点
Entry<K,V> entry = new Entry<>(key,value);
//计算出当前key对应的hash值
int currentIndex = calcStoreIndex(entry.getHash());
//如果该桶为空,初始化咱们链表的头结点
if (tables[currentIndex] == null){
tables[currentIndex] = new Entry<K,V>();
}
//如果该桶没有一个结点,直接将该节点加入到桶里即可
if (tables[currentIndex].next == null){
System.out.println(“当前数组下标为:” + currentIndex +”,当前结点数量为0,” + entry + “直接加入”);
tables[currentIndex].next = entry;
size++;//当前结点数量增加
return entry.getValue();
}
/**
* 如果当前桶存在至少一个结点,则需要考虑哈希冲突
* 跟桶里的每个节点通过equals()方法进行对比
* 如果存在一个返回为true,则不添加,直接修改该结点对应的value即可
* 反之则追加结点到链表的最前面
* */
boolean flag = false;//是否找到结点标识
Entry<K,V> cur = null;
for (cur = tables[currentIndex].next;cur != null;cur = cur.next){
if (cur.getKey().equals(entry.getKey())){
flag = true;
break;
}
}
//通过equals方法如果找到,则修改对应结点的value值
if (flag){
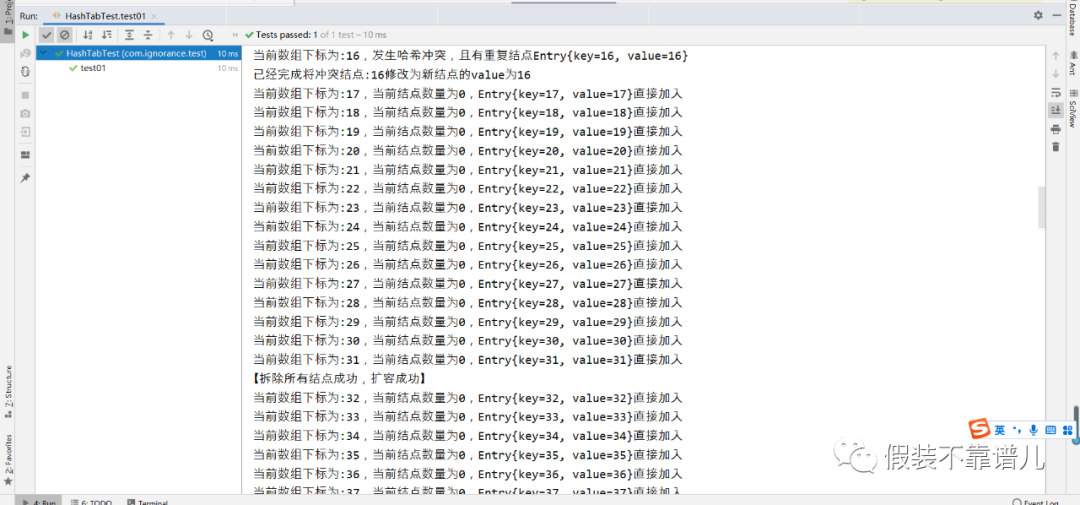
System.out.println(“当前数组下标为:” + currentIndex +”,发生哈希冲突,且有重复结点” + cur);
V oldVal = cur.getValue();
cur.setValue(entry.getValue());
System.out.println(“已经完成将冲突结点:” + oldVal + “修改为新结点的value为” + entry.getValue());
return oldVal;
}
/**
* 如果能走到这里,说明虽然发生了哈希冲突,但是没有相同节点
* 我们这时直接将结点加到当前链表最前面就可以了
*/
System.out.println(“当前数组下标为:” + currentIndex +”,发生哈希冲突,没有重复结点,” + entry + “添加完成”);
entry.next = tables[currentIndex].next;
tables[currentIndex].next = entry;
size++;//结点数量自增
return entry.getValue();
}
为了查看咱们此时哈希表的存储情况,咱们现在重新改造show方法:
/**
* 哈希表遍历
*/
public void show(){
for (int i = 0;i < tables.length;i++){
System.out.println(“开始遍历第” + (i + 1) +”个桶:”);
if (tables[i] == null){
System.out.println(“当前链表为空…”);
continue;
}
for (Entry<K,V> cur = tables[i].next;cur != null;cur = cur.next){
System.out.println(cur);
}
}
}
这时看一下咱们的执行结果:
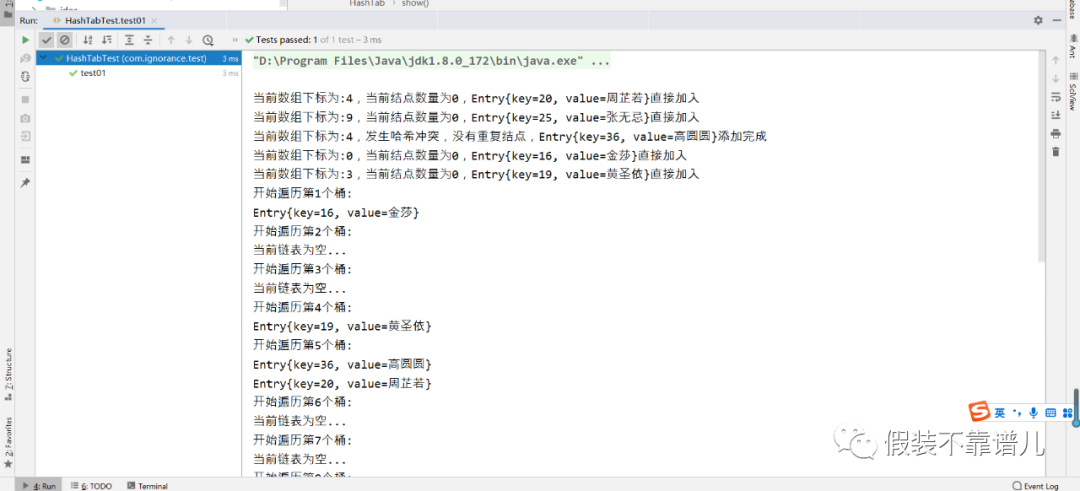
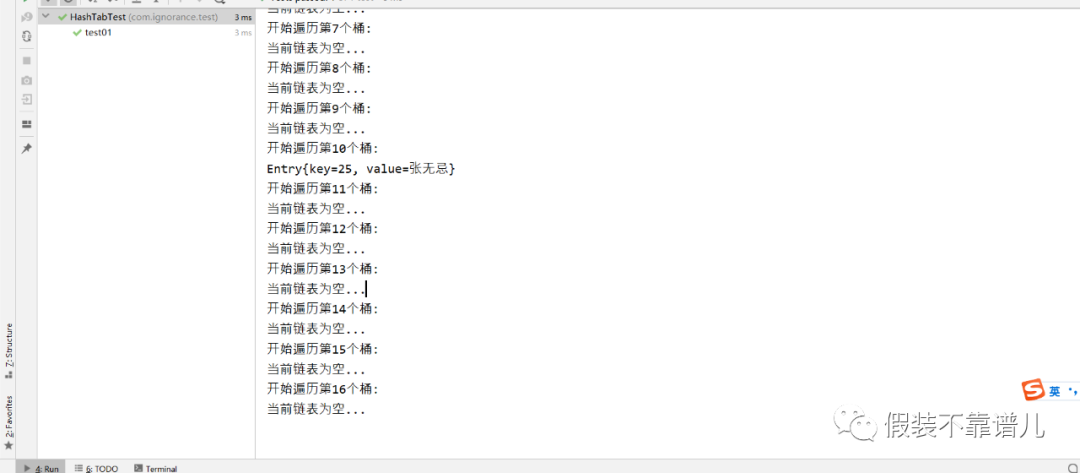
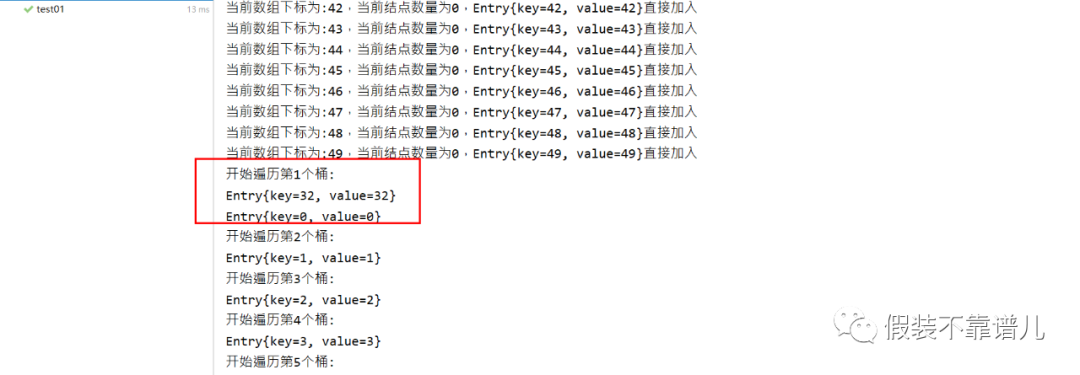
我们的测试结果是正确的,周芷若算出的索引值为4,所以挂到第5个桶了,张无忌、金莎、黄圣依算出的索引值分别挂到其对应的桶,像咱们的高圆圆,算出的索引值仍然是4,因为前面周芷若已经存在索引为4的位置了,所以这个时候就出现了哈希碰撞,我们需要将高圆圆与索引为4的所有节点的key调用equals()方法进行比较,结果高圆圆和周芷若所对应的key返回的为false,所以直接加在当前链表的最前面。也就是咱们的运行结果存储的样子。
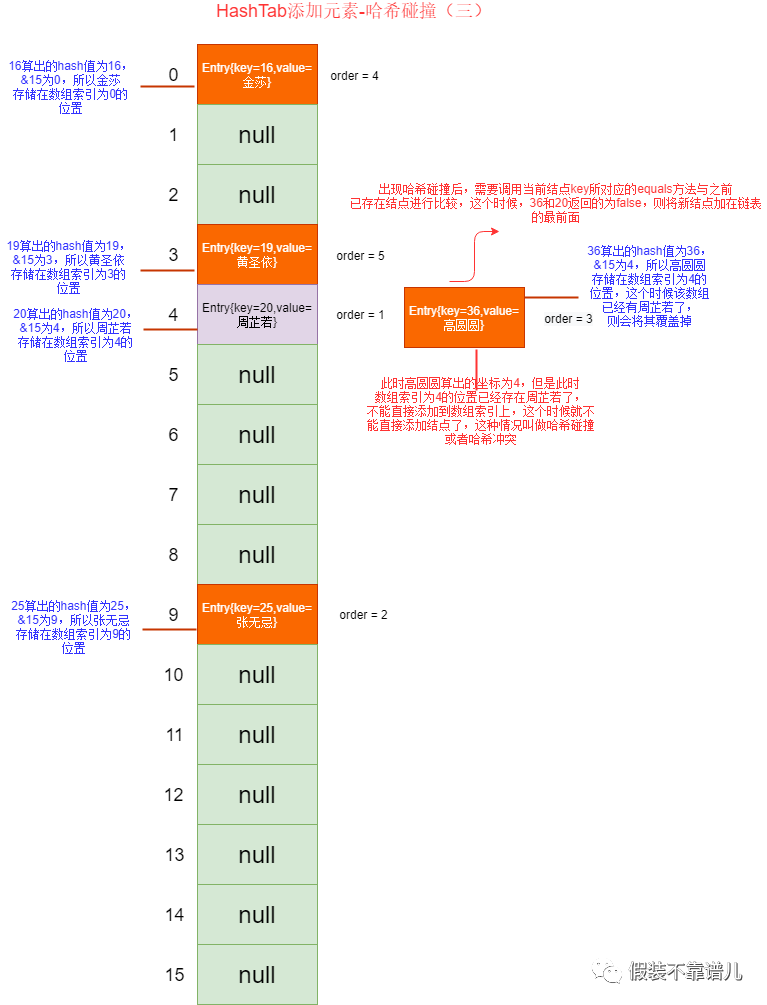
最终存储结果如下图:
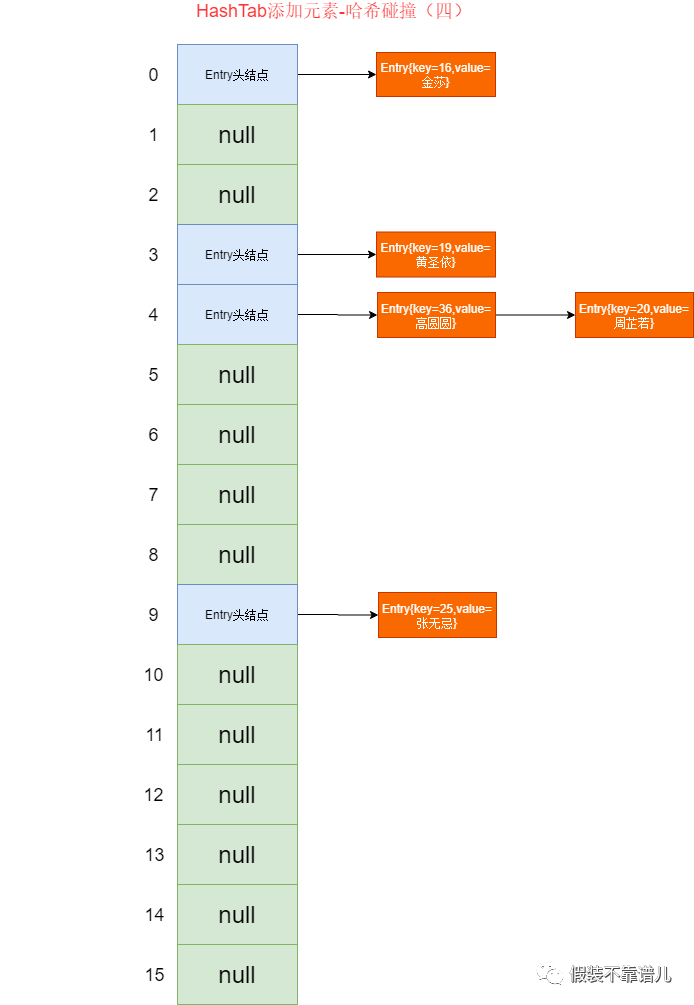
那么这个时候我们存储同样的key,看一下执行的结果:
package com.ignorance.test;
import com.ignorance.hash.HashTab;
import org.junit.Test;
/**
* @descript 哈希表测试类
* @author 陈海江
* @date 2022/7/29
*/
public class HashTabTest {
@Test
public void test01(){
HashTab<Integer,String> hashTab = new HashTab<>();
hashTab.put(20,”周芷若”);
hashTab.put(20,”高圆圆”);
hashTab.show();
}
}
在测试类中,我们添加两个key一样的结点,我们都知道20算出的hash值仍然为20,20 & 15 算出的索引值为4,所以这两个结点都会落在索引为4的位置上,但是这时候这两个key调用equals()方法返回的肯定为true,所以这时候会出现哈希碰撞,且为重复元素,此时我们新结点不能添加,只会将旧结点的value值周芷若修改为高圆圆。
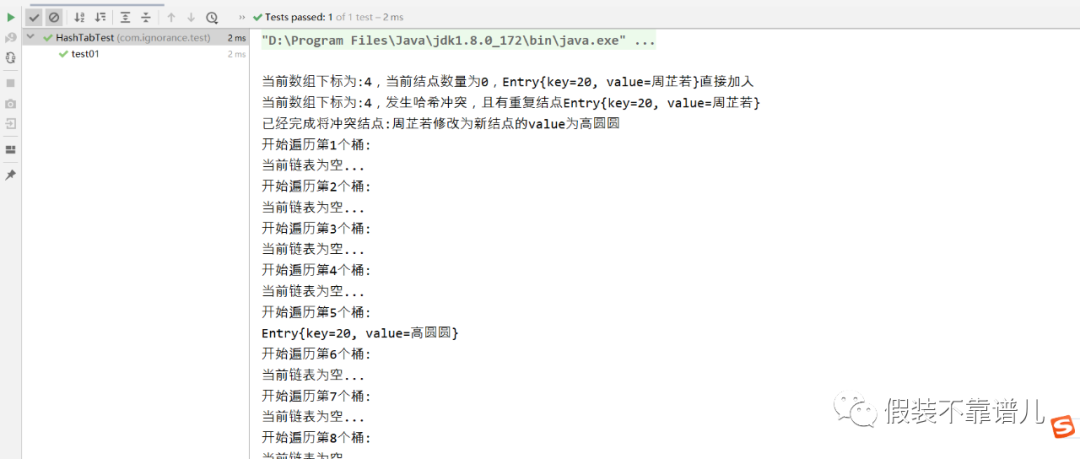
存储结果如下图所示:
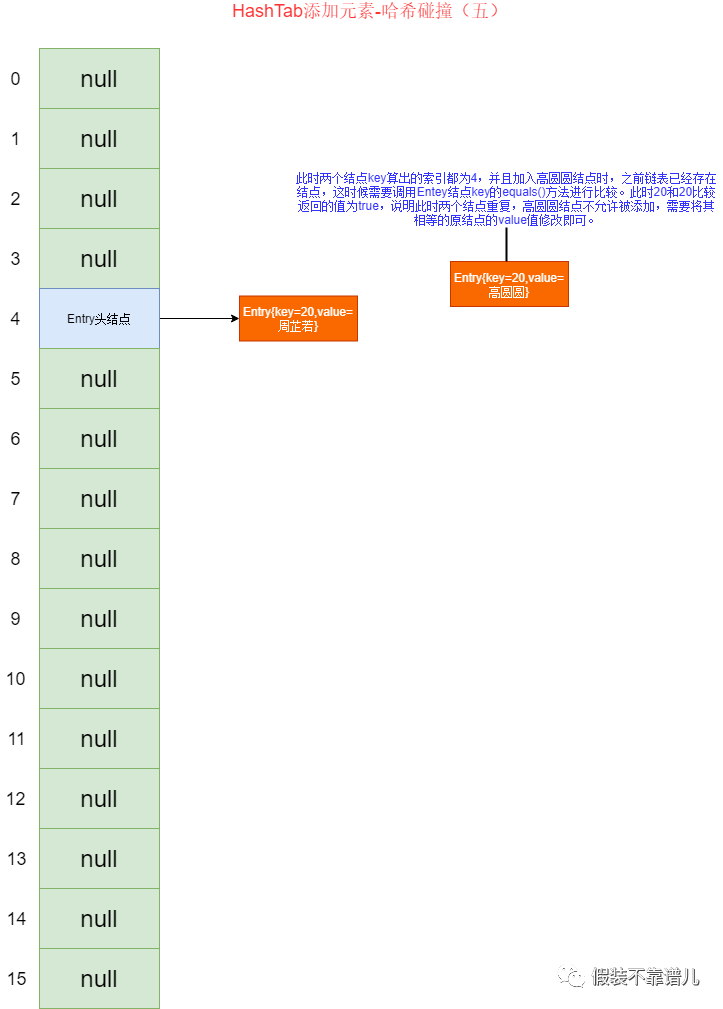
存储结果如下图所示:
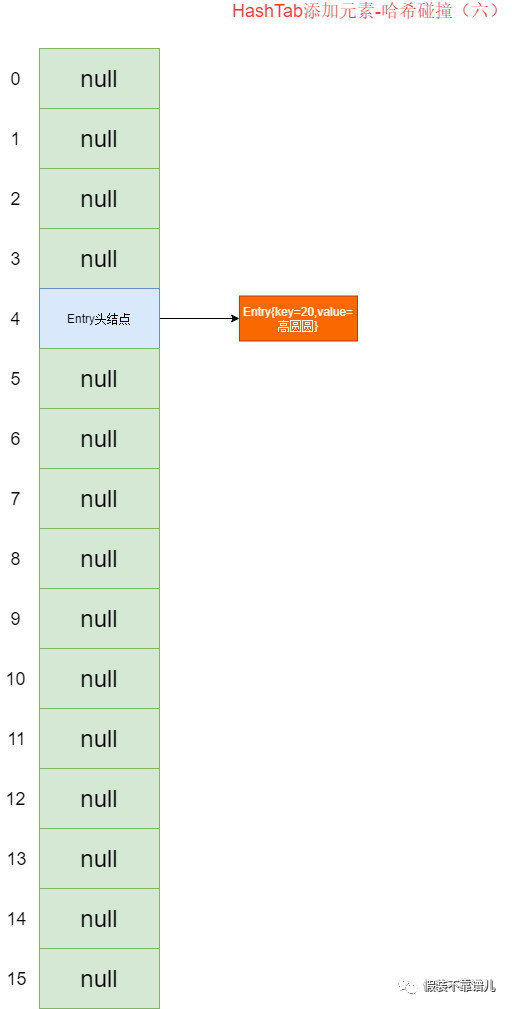
所以说呢,综合以上的知识,哈希表的不可重复性是通过咱们key所对应的equals方法确定的,如果两个对象通过hashcode()算出的坐标一致,则需要通过当前对象的equals()方法进行判断是否应该添加。
3.哈希表的扩容
理论上讲,咱们的数组初始长度为16,数据虽然有长度限制但是咱们的链表没有长度限制,初始的长度就足够存放无数多个结点。为什么还需要扩容呢?为了弄清楚这个问题,咱们不妨,向哈希表中加入多个结点,看一下最终的效果。
package com.ignorance.test;
import com.ignorance.hash.HashTab;
import org.junit.Test;
/**
* @descript 哈希表测试类
* @author 陈海江
* @date 2022/7/29
*/
public class HashTabTest {
@Test
public void test01(){
HashTab<Integer,String> hashTab = new HashTab<>();
for (int i = 0;i < 1000;i++){
hashTab.put(i,i + “”);
}
hashTab.show();
}
}
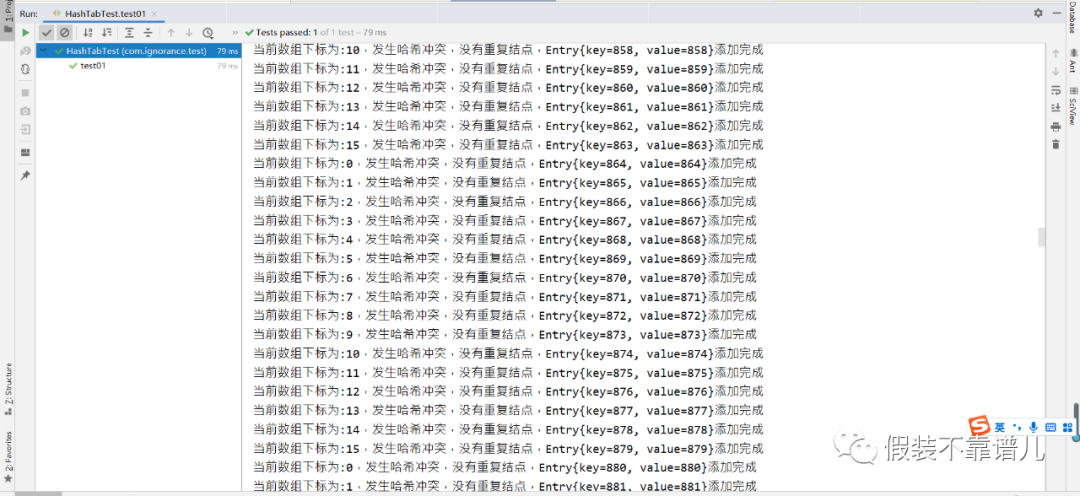
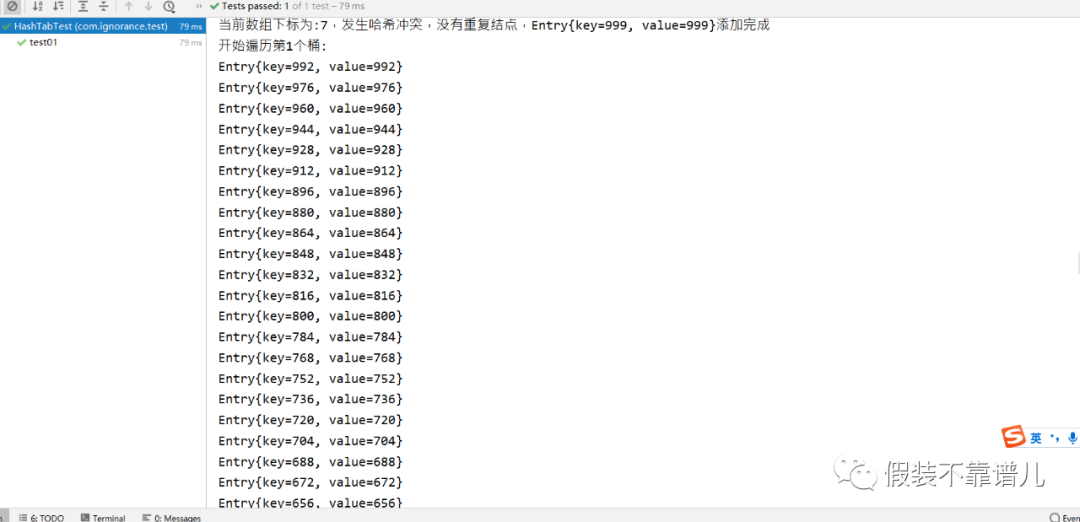
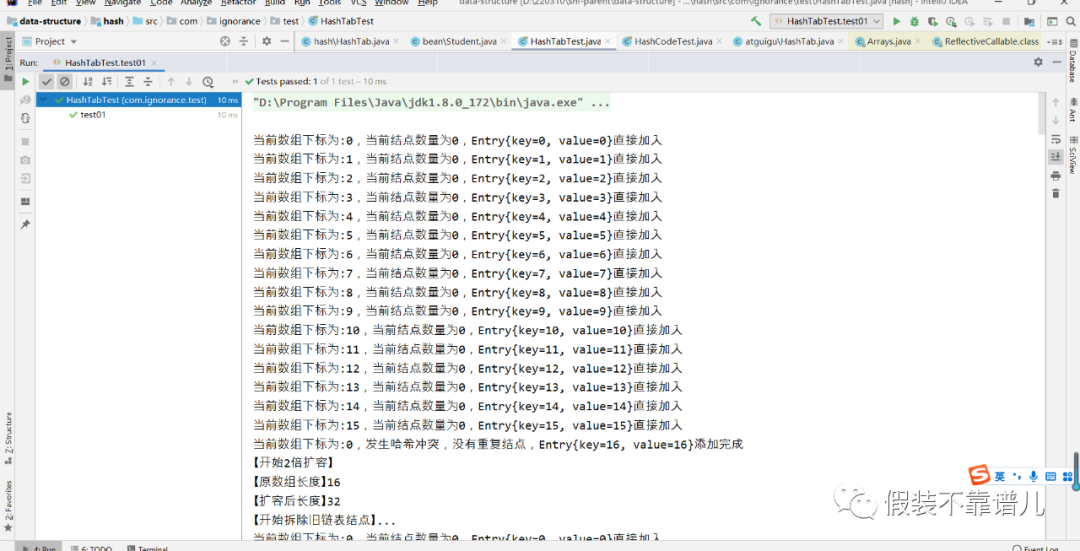
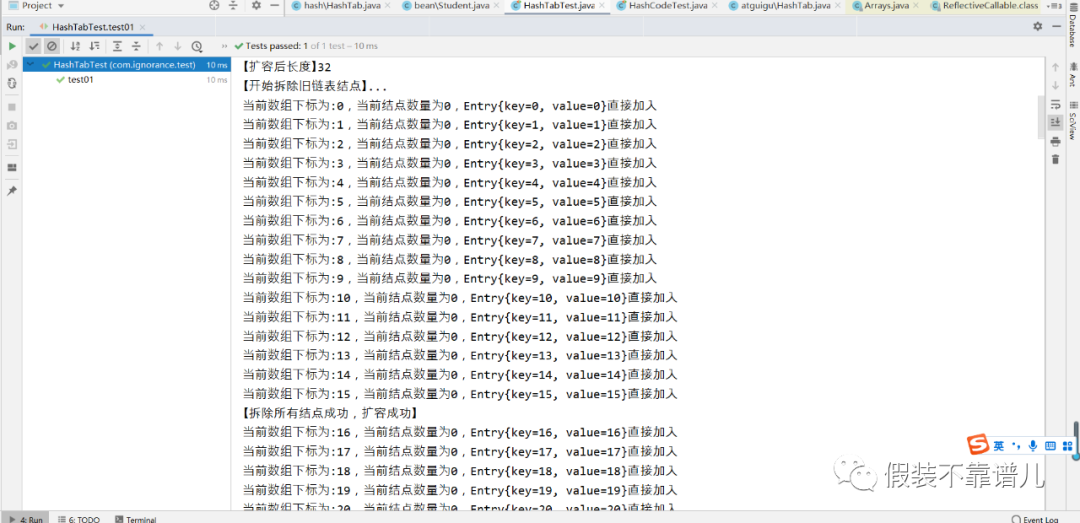
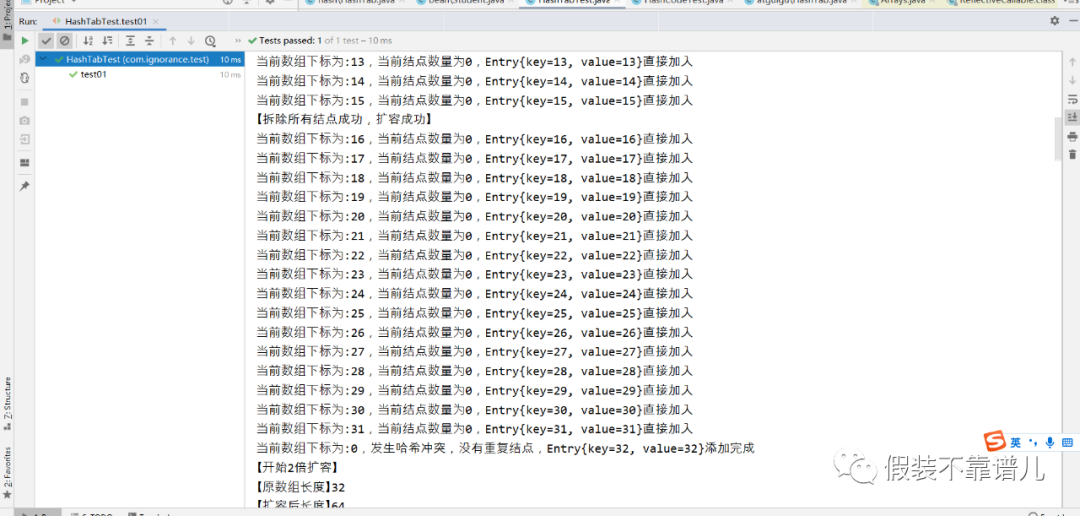
这个时候我1000个结点放在16个位置,肯定会出现一个链表会有很多个结点的情况,1000 / 16的平均值也差不多60多。通过上面的运行结果来看,几乎都是满屏的哈希冲突。换句话来说,咱们的哈希表主要是用来查询的,通过key快速查找value的,链表结点一多,咱们的查询效率是不是大打折扣了呢?所以说啊,即使能够存下,我们也需要通过扩容原数组的方式来让咱们数组有更多空间来摘取链表上的结点。所以说,当咱们结点数量达到16 * 0.75 = 12,也就是总长度 * 扩容因子且当前添加的桶上面存在结点时,我们哈希表底层的数组会进行2倍扩容,本来结点有18个结点,我们现在数组扩容了,就需要重新计算所有结点的哈希值,从&15变成&31,让咱们每个链表放更少的节点,从而进一步来提升咱们哈希表的查询效率。
扩容代码:满足当前长度 * 扩容因子且当前桶不为空进行扩容:
/**
* @descript 判断是否扩容
* 满足当前结点数量>=总长度 * 扩容因子 且 当前桶不为空才进行扩容
* @return
*/
private boolean ensureCapacityInternal(Entry<K,V> bucket){
if (size >= actualSize * actualLoadFactor && bucket != null){
return true;
}
return false;
}
扩容按照两倍扩容,且拆除链表结点到新的位置,进一步提高查询效率:
/**
* @descript 扩容按照两倍扩容,且拆除链表结点到新的位置,进一步提高查询效率
*/
private void ensize(){
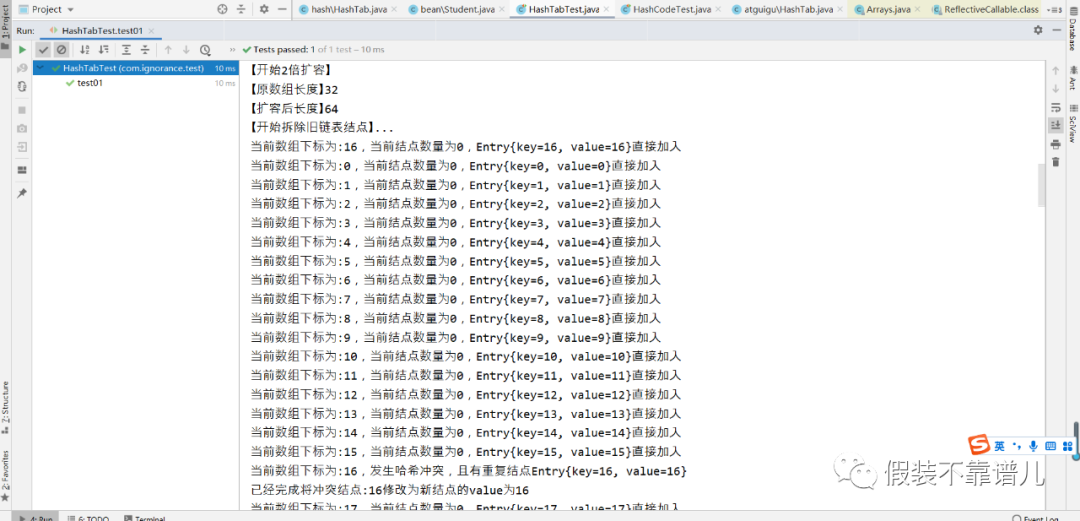
System.out.println(“【开始2倍扩容】”);
System.out.println(“【原数组长度】” + actualSize);
//保存旧结点
Entry<K,V>[] oldTables = tables;
//2倍扩容
actualSize = actualSize << 1;
System.out.println(“【扩容后长度】” + actualSize);
//初始化新的数组
tables = new Entry[actualSize];
//重新计算hash值,拆除链表结点到新数组中
System.out.println(“【开始拆除旧链表结点】…”);
int i = 0;
for (Entry<K,V> e : oldTables){
i++;
if (e == null || e.next == null){
System.out.println(“【当前第” + i +”条链表为空,无需拆除】”);
continue;
}
for (Entry<K,V> cur = e.next;cur != null;cur = cur.next){
put(cur.getKey(),cur.getValue());//重新加入新数组
}
}
System.out.println(“【拆除所有结点成功,扩容成功】”);
}
继续改造put方法:
/**
* put 添加方法
* @param key 键
* @param value 值
* @return
*/
public V put(K key,V value){
//将当前键值对填充为一个Entry,因为咱们的tables数组只能存放Entry结点
Entry<K,V> entry = new Entry<>(key,value);
//计算出当前key对应的hash值
int currentIndex = calcStoreIndex(entry.getHash());
//如果该桶为空,初始化咱们链表的头结点
if (tables[currentIndex] == null){
tables[currentIndex] = new Entry<K,V>();
}
//如果该桶没有一个结点,直接将该节点加入到桶里即可
if (tables[currentIndex].next == null){
System.out.println(“当前数组下标为:” + currentIndex +”,当前结点数量为0,” + entry + “直接加入”);
tables[currentIndex].next = entry;
size++;//当前结点数量增加
return entry.getValue();
}
/**
* 如果当前桶存在至少一个结点,则需要考虑哈希冲突
* 跟桶里的每个节点通过equals()方法进行对比
* 如果存在一个返回为true,则不添加,直接修改该结点对应的value即可
* 反之则追加结点到链表的最前面
* */
boolean flag = false;//是否找到结点标识
Entry<K,V> cur = null;
for (cur = tables[currentIndex].next;cur != null;cur = cur.next){
if (cur.getKey().equals(entry.getKey())){
flag = true;
break;
}
}
//通过equals方法如果找到,则修改对应结点的value值
if (flag){
System.out.println(“当前数组下标为:” + currentIndex +”,发生哈希冲突,且有重复结点” + cur);
V oldVal = cur.getValue();
cur.setValue(entry.getValue());
System.out.println(“已经完成将冲突结点:” + oldVal + “修改为新结点的value为” + entry.getValue());
return oldVal;
}
/**
* 如果能走到这里,说明虽然发生了哈希冲突,但是没有相同节点
* 我们此时需要判断是否需要扩容
* 我们这时直接将结点加到当前链表最前面就可以了
*/
System.out.println(“当前数组下标为:” + currentIndex +”,发生哈希冲突,没有重复结点,” + entry + “添加完成”);
//如果判断成功,则说明达到扩容条件,进行2倍扩容
if (ensureCapacityInternal(tables[currentIndex])){
ensize();
put(entry.getKey(),entry.getValue());//添加新结点
}
entry.next = tables[currentIndex].next;
tables[currentIndex].next = entry;
size++;//结点数量自增
return entry.getValue();
}
测试:我们想哈希表添加50个结点,看一下执行过程:
package com.ignorance.test;
import com.ignorance.hash.HashTab;
import org.junit.Test;
/**
* @descript 哈希表测试类
* @author 陈海江
* @date 2022/7/29
*/
public class HashTabTest {
@Test
public void test01(){
HashTab<Integer,String> hashTab = new HashTab<>();
for (int i = 0;i < 50;i++){
hashTab.put(i,i + “”);
}
hashTab.show();
}
}
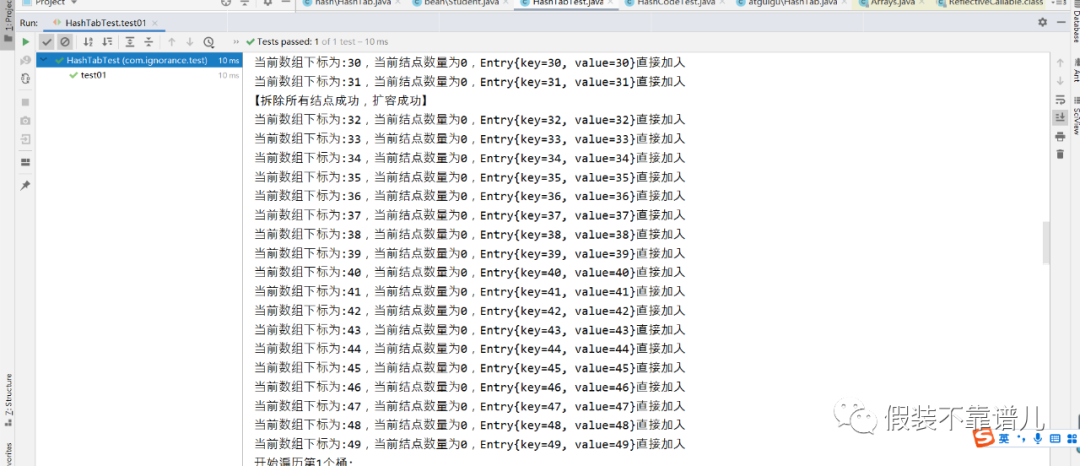
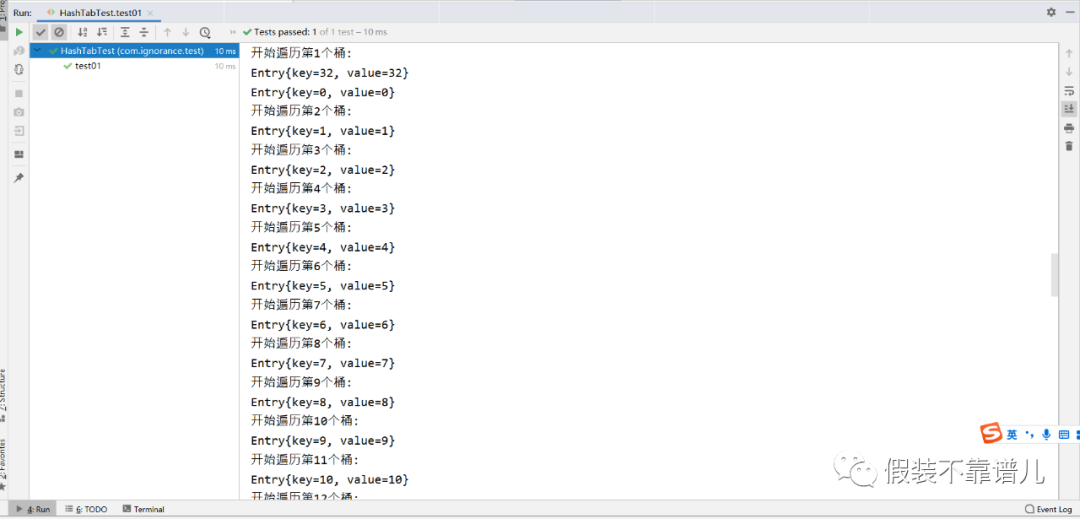
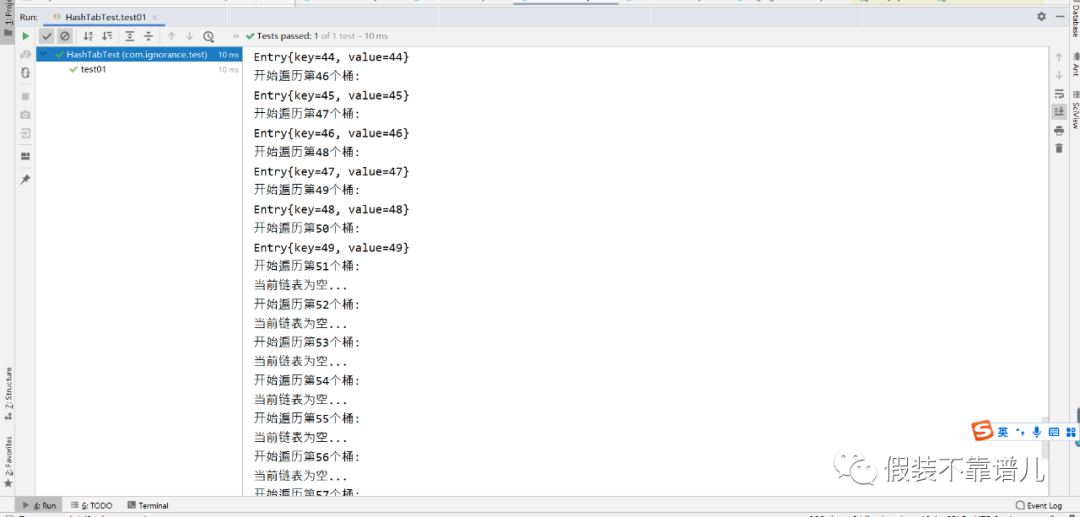
NO.4 结点查询
我们都知道在HashMap我们最常用的方法除了put()外,其次就是get()方法了,我们需要通过get方法来查询对应的value值。下面我们继续来完成get()方法的实现。
/**
* @descript 通过key查询value
* @param key
* @return
*/
public V get(K key){
//组装Entry
Entry<K,V> entry = new Entry<>(key,null);
//通过key的hash码计算出该结点在哈希表中的存储位置
int currentIndex = calcStoreIndex(entry.getHash());
//统计查询次数
int count = 0;
//如果当前链表为空或者没有结点,则表示没有该结点,直接返回Null即可
if (tables[currentIndex] == null || tables[currentIndex].next == null){
return null;
}
//查询标识
boolean flag = false;
Entry<K,V> cur = null;
for (cur = tables[currentIndex].next;cur != null;cur = cur.next){
count++;
if (cur.getKey().equals(key)){
flag = true;
break;
}
}
System.out.println(“【一共查询了” + count +”次】”);
if (true){
return cur.getValue();
}
return null;
}
测试查询效率:
package com.ignorance.test;
import com.ignorance.hash.HashTab;
import org.junit.Test;
/**
* @descript 哈希表测试类
* @author 陈海江
* @date 2022/7/29
*/
public class HashTabTest {
@Test
public void test01(){
HashTab<Integer,String> hashTab = new HashTab<>();
for (int i = 0;i < 50;i++){
hashTab.put(i,i + “”);
}
hashTab.show();
System.out.println(hashTab.get(18));
System.out.println(hashTab.get(26));
System.out.println(hashTab.get(51));
}
}
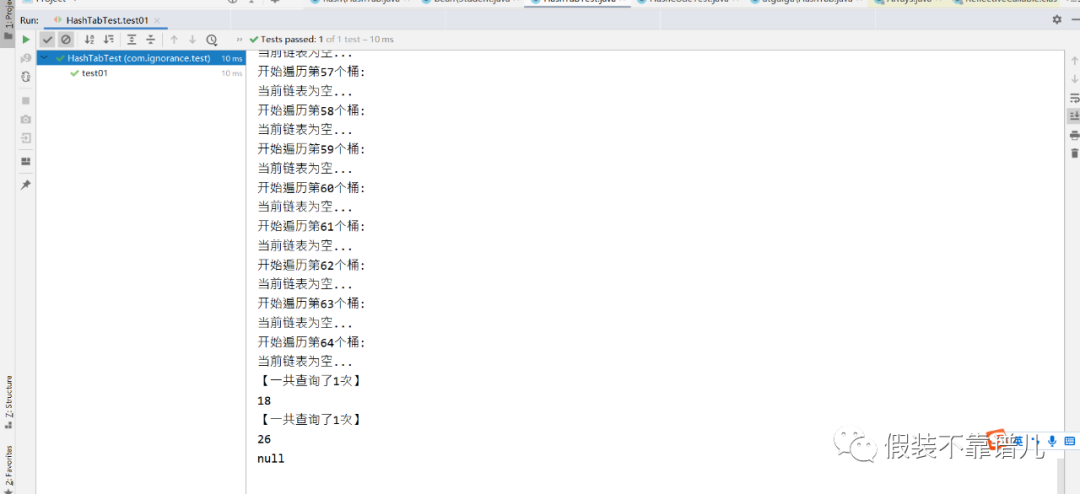
可以看出咱们的哈希表查询效率特别高,我们存了50个结点,如果按照无序数组需要最多查找50次,而我们哈希表的原理是通过当前Entry的key算出当前结点所存储的位置,进而排除了其余49条链表,在该链表进行查找,又因为当前链表只有一个结点,故而查询效率大幅度提升。
NO.5 结点删除
和查询一样,我们通过当前结点的key算出当前结点所在数组位置,然后遍历链表,删除掉对应结点。
/**
* 删除结点
* @param key
* @return
*/
public boolean remove(K key){
//组装成entry
Entry<K,V> entry = new Entry<>(key,null);
//计算当前结点所在索引
int currentIndex = calcStoreIndex(entry.getHash());
//统计执行次数
int count = 0;
//如果当前链表为空或者没有结点,则表示没有该结点,直接返回Null即可
if (tables[currentIndex] == null || tables[currentIndex].next == null){
return false;
}
//删除标识
boolean flag = false;
Entry<K,V> cur = null;
for (cur = tables[currentIndex];cur != null;cur = cur.next){
count++;
if (cur.next.getKey().equals(key)){
flag = true;
break;
}
}
System.out.println(“【一共执行了” + count +”次】”);
//如果flag为true,直接删除结点
if (flag){
cur.next = cur.next.next;
}
return flag;
}
测试删除效率:
package com.ignorance.test;
import com.ignorance.hash.HashTab;
import org.junit.Test;
/**
* @descript 哈希表测试类
* @author 陈海江
* @date 2022/7/29
*/
public class HashTabTest {
@Test
public void test01() {
HashTab<Integer, String> hashTab = new HashTab<>();
for (int i = 0; i < 50; i++) {
hashTab.put(i, i + “”);
}
hashTab.show();
// System.out.println(hashTab.get(18));
// System.out.println(hashTab.get(26));
// System.out.println(hashTab.get(51));
boolean isRemove = hashTab.remove(0);
System.out.println(isRemove);
hashTab.show();
}
}

04全部代码
NO.1 结点类
package com.ignorance.node;
import java.util.Objects;
/**
* @author :陈海江
* @descript:结点Entry
* @date:2022/07/29
* @param <K>
* @param <V>
*/
public class Entry<K,V> {
private int hash;
private K key;
private V value;
public Entry<K,V> next;
public Entry() {
}
public Entry(K key, V value) {
this.hash = key.hashCode();
this.key = key;
this.value = value;
}
public int getHash() {
return hash;
}
public void setHash(int hash) {
this.hash = hash;
}
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
@Override
public String toString() {
return “Entry{” +
“key=” + key +
“, value=” + value +
‘}’;
}
}
NO.2 哈希表核心类
package com.ignorance.hash;
import com.ignorance.node.Entry;
import com.sun.xml.internal.ws.api.model.wsdl.WSDLOutput;
import org.w3c.dom.ls.LSOutput;
import java.util.Arrays;
/**
* @author :陈海江
* @descript:哈希表主要实现类
* @date:2022/07/29
* @param <K>
* @param <V>
*/
public class HashTab<K,V> {
//底层存储元素数组
private Entry[] tables;
//数组初始长度
private static final int DEFAULT_SIZE = 16;
//默认扩容因子
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
//数组实际长度
private int actualSize;
//实际扩容因子
private float actualLoadFactor;
//结点个数
private int size;
public HashTab() {
this.tables = new Entry[DEFAULT_SIZE];
this.actualSize = DEFAULT_SIZE;
this.actualLoadFactor = DEFAULT_LOAD_FACTOR;
}
/**
* put 添加方法
* @param key 键
* @param value 值
* @return
*/
public V put(K key,V value){
//将当前键值对填充为一个Entry,因为咱们的tables数组只能存放Entry结点
Entry<K,V> entry = new Entry<>(key,value);
//计算出当前key对应的hash值
int currentIndex = calcStoreIndex(entry.getHash());
//如果该桶为空,初始化咱们链表的头结点
if (tables[currentIndex] == null){
tables[currentIndex] = new Entry<K,V>();
}
//如果该桶没有一个结点,直接将该节点加入到桶里即可
if (tables[currentIndex].next == null){
System.out.println(“当前数组下标为:” + currentIndex +”,当前结点数量为0,” + entry + “直接加入”);
tables[currentIndex].next = entry;
size++;//当前结点数量增加
return entry.getValue();
}
/**
* 如果当前桶存在至少一个结点,则需要考虑哈希冲突
* 跟桶里的每个节点通过equals()方法进行对比
* 如果存在一个返回为true,则不添加,直接修改该结点对应的value即可
* 反之则追加结点到链表的最前面
* */
boolean flag = false;//是否找到结点标识
Entry<K,V> cur = null;
for (cur = tables[currentIndex].next;cur != null;cur = cur.next){
if (cur.getKey().equals(entry.getKey())){
flag = true;
break;
}
}
//通过equals方法如果找到,则修改对应结点的value值
if (flag){
System.out.println(“当前数组下标为:” + currentIndex +”,发生哈希冲突,且有重复结点” + cur);
V oldVal = cur.getValue();
cur.setValue(entry.getValue());
System.out.println(“已经完成将冲突结点:” + oldVal + “修改为新结点的value为” + entry.getValue());
return oldVal;
}
/**
* 如果能走到这里,说明虽然发生了哈希冲突,但是没有相同节点
* 我们此时需要判断是否需要扩容
* 我们这时直接将结点加到当前链表最前面就可以了
*/
System.out.println(“当前数组下标为:” + currentIndex +”,发生哈希冲突,没有重复结点,” + entry + “添加完成”);
//如果判断成功,则说明达到扩容条件,进行2倍扩容
if (ensureCapacityInternal(tables[currentIndex])){
ensize();
put(entry.getKey(),entry.getValue());//添加新结点
}
entry.next = tables[currentIndex].next;
tables[currentIndex].next = entry;
size++;//结点数量自增
return entry.getValue();
}
/**
* @descript 通过key查询value
* @param key
* @return
*/
public V get(K key){
//组装Entry
Entry<K,V> entry = new Entry<>(key,null);
//通过key的hash码计算出该结点在哈希表中的存储位置
int currentIndex = calcStoreIndex(entry.getHash());
//统计查询次数
int count = 0;
//如果当前链表为空或者没有结点,则表示没有该结点,直接返回Null即可
if (tables[currentIndex] == null || tables[currentIndex].next == null){
return null;
}
//查询标识
boolean flag = false;
Entry<K,V> cur = null;
for (cur = tables[currentIndex].next;cur != null;cur = cur.next){
count++;
if (cur.getKey().equals(key)){
flag = true;
break;
}
}
System.out.println(“【一共查询了” + count +”次】”);
if (true){
return cur.getValue();
}
return null;
}
/**
* 删除结点
* @param key
* @return
*/
public boolean remove(K key){
//组装成entry
Entry<K,V> entry = new Entry<>(key,null);
//计算当前结点所在索引
int currentIndex = calcStoreIndex(entry.getHash());
//统计执行次数
int count = 0;
//如果当前链表为空或者没有结点,则表示没有该结点,直接返回Null即可
if (tables[currentIndex] == null || tables[currentIndex].next == null){
return false;
}
//删除标识
boolean flag = false;
Entry<K,V> cur = null;
for (cur = tables[currentIndex];cur != null;cur = cur.next){
count++;
if (cur.next.getKey().equals(key)){
flag = true;
break;
}
}
System.out.println(“【一共执行了” + count +”次】”);
//如果flag为true,直接删除结点
if (flag){
cur.next = cur.next.next;
}
return flag;
}
/**
* 哈希表遍历
*/
public void show(){
for (int i = 0;i < tables.length;i++){
System.out.println(“开始遍历第” + (i + 1) +”个桶:”);
if (tables[i] == null){
System.out.println(“当前链表为空…”);
continue;
}
for (Entry<K,V> cur = tables[i].next;cur != null;cur = cur.next){
System.out.println(cur);
}
}
}
/**
* @descript 通过当前key的hash码计算出在数组的存储位置
* @param hash
* @return
*/
private int calcStoreIndex(int hash){
return hash & actualSize – 1;
}
/**
* @descript 判断是否扩容
* 满足当前结点数量>=总长度 * 扩容因子 且 当前桶不为空才进行扩容
* @return
*/
private boolean ensureCapacityInternal(Entry<K,V> bucket){
if (size >= actualSize * actualLoadFactor && bucket != null){
return true;
}
return false;
}
/**
* @descript 扩容按照两倍扩容,且拆除链表结点到新的位置,进一步提高查询效率
*/
private void ensize(){
System.out.println(“【开始2倍扩容】”);
System.out.println(“【原数组长度】” + actualSize);
//保存旧结点
Entry<K,V>[] oldTables = tables;
//2倍扩容
actualSize = actualSize << 1;
System.out.println(“【扩容后长度】” + actualSize);
//初始化新的数组
tables = new Entry[actualSize];
//重新计算hash值,拆除链表结点到新数组中
System.out.println(“【开始拆除旧链表结点】…”);
int i = 0;
for (Entry<K,V> e : oldTables){
i++;
if (e == null || e.next == null){
System.out.println(“【当前第” + i +”条链表为空,无需拆除】”);
continue;
}
for (Entry<K,V> cur = e.next;cur != null;cur = cur.next){
put(cur.getKey(),cur.getValue());//重新加入新数组
}
}
System.out.println(“【拆除所有结点成功,扩容成功】”);
}
}
NO.3 测试类
package com.ignorance.test;
import com.ignorance.hash.HashTab;
import org.junit.Test;
/**
* @descript 哈希表测试类
* @author 陈海江
* @date 2022/7/29
*/
public class HashTabTest {
@Test
public void test01() {
HashTab<Integer, String> hashTab = new HashTab<>();
for (int i = 0; i < 50; i++) {
hashTab.put(i, i + “”);
}
hashTab.show();
// System.out.println(hashTab.get(18));
// System.out.println(hashTab.get(26));
// System.out.println(hashTab.get(51));
boolean isRemove = hashTab.remove(0);
System.out.println(isRemove);
hashTab.show();
}
}
05总结
以上是上述过程所有可执行代码,在此过程中,咱们使用哈希表这种数据结构,模拟实现了一个简单的HashMap,希望对同学们理解咱们的集合框架会有一些学习上或者面试上的帮助。
宝剑锋出磨砺出,梅花香自苦寒来。从咱们选择IT这个行业开始,就注定这是一个不断学习不断进步的长期过程,计算机是理科性的知识,需要我们大家去掌握到每个知识点的实质,而不是一昧的去靠背,去靠蒙。既折磨自己,又浪费咱们宝贵的精力与时间。所以呢,希望能通过这篇文章,让大家一方面对HashMap有全新的认识,把它的核心数据结构搞懂,另一方面通过手写这个简单的案例,希望同学们养成一种良好的,能够举一反三的学习方法。也希望对正在面试,对集合框架有困扰的同学给予一点帮助,把这些知识当作咱们技能的常识,轻轻松松吊打面试官,不再被面试官牵着鼻子走。
所以呢,加油吧,学好技术,达到人生巅峰!未来的生活一定不会辜负同样努力的你!