Hive 有很多join,这里主要讲述常用的三种join。
0 Map Reduce
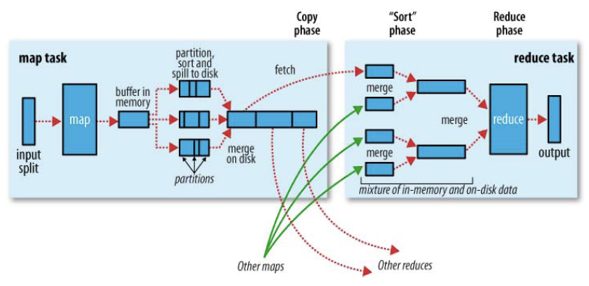
1 Common Join
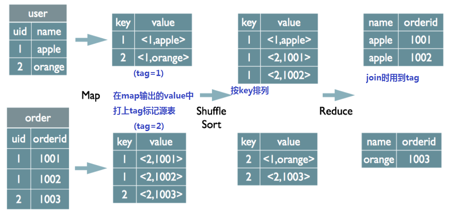
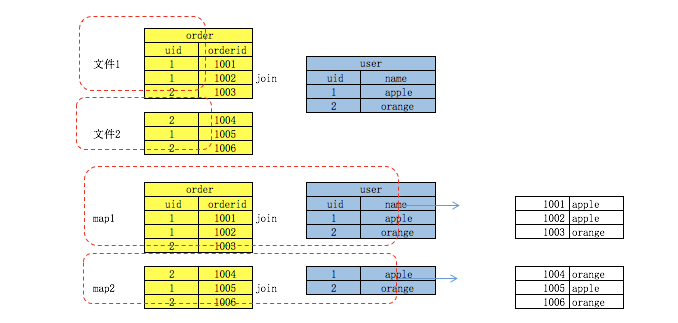
最为普通的join策略,不受数据量的大小影响,也可以叫做reduce side join ,最没效率的一种join 方式. 它由一个mapreduce job 完成.
首先将大表和小表分别进行map 操作, 在map shuffle 的阶段每一个map output key 变成了table_name_tag_prefix + join_column_value , 但是在进行partition 的时候它仍然只使用join_column_value 进行hash.
每一个reduce 接受所有的map 传过来的split , 在reducce 的shuffle 阶段,它将map output key 前面的table_name_tag_prefix 给舍弃掉进行比较.
In every map/reduce stage of the join, the last table in the sequence is streamed through the reducers where as the others are buffered. Therefore, it helps to reduce the memory needed in the reducer for buffering the rows for a particular value of the join key by organizing the tables such that the largest tables appear last in the sequence.
2 Map Join
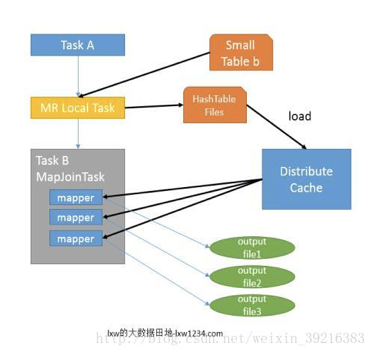
MAPJOINs are processed by loading the smaller table into an in-memory hash map and matching keys with the larger table as they are streamed through. The prior implementation has this division of labor:
- Local work:
- read records via standard table scan (including filters and projections) from source on local machine
- build hashtable in memory
- write hashtable to local disk
- upload hashtable to dfs
- add hashtable to distributed cache
- Map task
- read hashtable from local disk (distributed cache) into memory
- match records’ keys against hashtable
- combine matches and write to output
- No reduce task
常见的优化就是,把关联的小表加载到内存中,去除reducer操作减少网络传输时间。参数如下:
SET hive.auto.convert.join=true;
SET hive.auto.convert.join.noconditionaltask=true;
SET hive.auto.convert.join.noconditionaltask.size=10000000000;
If
hive.auto.convert.join
is set to true the optimizer not only converts joins to mapjoins but also merges MJ* patterns as much as possible.Optimize Auto Join Conversion
When auto join is enabled, there is no longer a need to provide the map-join hints in the query. The auto join option can be enabled with two configuration parameters:
set hive.auto.convert.join.noconditionaltask = true; set hive.auto.convert.join.noconditionaltask.size = 10000000;The default for
hive.auto.convert.join.noconditionaltask
is true which means auto conversion is enabled. (Originally the default was false – see
HIVE-3784
– but it was changed to true by
HIVE-4146
before Hive 0.11.0 was released.)The
size configuration
enables the user to control what size table can fit in memory. This value represents the sum of the sizes of tables that can be converted to hashmaps that fit in memory. Currently, n-1 tables of the join have to fit in memory for the map-join optimization to take effect. There is no check to see if the table is a compressed one or not and what the potential size of the table can be. The effect of this assumption on the results is discussed in the next section.
注:当hash table分发相同key的value时,所有的value会在一个list里。便于生成所有的关联,这点和left semi join不同。
3 Left Semi Join
LEFT SEMI JOIN implements the uncorrelated IN/EXISTS subquery semantics in an efficient way. As of Hive 0.13 the IN/NOT IN/EXISTS/NOT EXISTS operators are supported using
subqueries
so most of these JOINs don’t have to be performed manually anymore. The restrictions of using LEFT SEMI JOIN are that the right-hand-side table should only be referenced in the join condition (ON-clause), but not in WHERE- or SELECT-clauses etc.
SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM B);
can be rewritten to:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b ON (a.key = b.key)
left semi join 实现的是 hive in的功能,具体实现和map join类似。区别在于小表hashtable会进行key value的去重,同时不在hash table里的key会被丢弃,从而实现in的功能。
参考文件:
https://www.cnblogs.com/zzhangyuhang/p/9792800.html
http://shiyanjun.cn/archives/588.html
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Joins
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+JoinOptimization