转载:http://blog.163.com/dj_djd/blog/static/8397680201192105954868/
关解释:
1,
创建一个分区函数和创建一个普通的数据库对象(例如表)没什么区别。所以根据标准语法走就OK了。
2,
partition_function_name是分区函数的名称。分区函数名称在数据库内必须唯一,并且符合标识符的规则。
3,
input_parameter_type是用于分区的列的数据类型,习惯把它称为分区依据列。当用作分区列时,除text、ntext、image、xml、timestamp、varchar(max)、nvarchar(max)、varbinary(max)、别名数据类型或 CLR 用户定义数据类型外,其他所有数据类型均有效。分区依据列是在 CREATE TABLE 或CREATE INDEX 语句中指定的。
4,
boundary_value [ ,…n ]中的boundary_value是边界值(或边界点的值),n代表可以最多有n个边界值,即n指定 boundary_value 提供的值的数目,但n不能超过 999。所创建的分区数等于n + 1。不必按顺序列出各值。如果值未按顺序列出,则 Database Engine 将对这些边界值进行排序,创建分区函数并返回一个警告,说明未按顺序提供值。如果 n 包括任何重复的值,则数据库引擎将返回错误。边界值的取值一定是和分区依据列相关的,所以只能使用 CREATE TABLE 或 CREATE INDEX 语句中指定的一个分区列。
5,
LEFT | RIGHT
指定boundary_value [ ,…n ] 的每个boundary_value属于每个边界值间隔的哪一侧(左侧还是右侧)。如果未指定,则默认值为 LEFT。
例如我们可以依据某个表的int列来创建分区函数:
create
partition
function
MyPF1
(
int
)
range
left
—
默认是
left
,所以可以省略
left
for
values
(
500000
,
1000000
,
1500000
)
很明显,这个分区函数创建了
4
个分区,因为此时
n=3,
所以分区总数是
n+1=4
。而那个
int
分区依据列表明将要分区的那个表里面一定有一列是
int
类型,是分区依据列。这个分区函数我们用的是
range
left
,各个分区的取值范围如下表:
4
个分区,因为此时
n=3,
所以分区总数是
n+1=4
。而那个
int
分区依据列表明将要分区的那个表里面一定有一列是
int
类型,是分区依据列。这个分区函数我们用的是
range
left
,各个分区的取值范围如下表:
|
分区
|
取值范围
|
|
1
|
(
负无穷 ,500000] |
|
2
|
[500001,1000000]
|
|
3
|
[1000001,1500000]
|
|
4
|
[1500001,
正无穷 ) |
如果换成
range
right
,即创建分区函数时代码如下:
create
partition
function
MyPF1
(
int
)
range
right
for
values
(
500000
,
1000000
,
1500000
)
那么
各个分区的取值范围如下表:
|
分区
|
取值范围
|
|
1
|
(
负无穷 ,499999] |
|
2
|
[500000,999999]
|
|
3
|
[1000000,1499999]
|
|
4
|
[1500000,
正无穷 ) |
我们还可以根据日期列创建分区函数,例如:
create
partition
function
MyPF2
(
datetime
)
range
right
for
values
(
‘2008/01/01’
,
‘2009/01/01’
)
这个分区函数非常适合查询和归档某一年的数据。各个分区的取值范围如下表:
|
分区
|
取值范围
|
|
1
|
<=2007/12/31
|
|
2
|
[2008/01/01,2008/12/31]
|
|
3
|
>=2009/01/01
|
当然我们也可以根据月份分区,而分区依据列支持的数据类型非常多,参照项目的实际情况选择最能表示分区的列类型。
分区方案
对表和索引进行分区的第二步是创建分区方案。分区方案定义了一个特定的分区函数将使用的物理存储结构(其实就是文件组),或者说是分区方案将分区函数生成的分区映射到我们定义的一组文件组。所以分区方案解决的是Where的问题,即表的各个分区在哪里存储的问题。分区方案的创建语法如下:
CREATE
PARTITION
SCHEME
partition_scheme_name
AS
PARTITION
partition_function_name
[ ALL ]
TO
(
{
file_group_name
|
[ PRIMARY ]
}
[ ,…n ]
)
TO
(
{
file_group_name
|
[ PRIMARY ]
}
[ ,…n ]
)
[ ; ]
分区方案语法的相关解释:
1,
创建分区方案时,根据分区函数的参数,定义映射表分区的文件组。必须指定足够的文件组来容纳分区数。可以指定所有分区映射到不同文件组、某些分区映射到单个文件组或所有分区映射到单个文件组。如果您希望在以后添加更多分区,还可以指定其他“未分配的”文件组。在这种情况下,SQL Server 用 NEXT USED 属性标记其中一个文件组。这意味着该文件组将包含下一个添加的分区。一个分区方案仅可以使用一个分区函数。但是,一个分区函数可以参与多个分区方案。
2,
partition_scheme_name 是分区方案的名称。分区方案名称在数据库中必须是唯一的,并且符合标识符规则。
3,
partition_function_name 是使用当前分区方案的分区函数的名称。分区函数所创建的分区将映射到在分区方案中指定的文件组。partition_function_name 必须已经存在于数据库中。
4,
ALL 指定所有分区都映射到在 file_group_name 中提供的同一个文件组,或映射到主文件组(如果指定了 [PRIMARY])。如果指定了 ALL,则只能指定一个 file_group_name。
5,
file_group_name | [ PRIMARY ] [ ,…n] 代表n个文件组。和分区函数中的各个分区对应。文件组必须已经存在于数据库中。 如果指定了 [PRIMARY],则分区将存储于主文件组中。如果指定了ALL,则只能指定一个 file_group_name。分区分配到文件组的顺序是从分区 1 开始,按文件组在[,…n] 中列出的顺序进行分配。在 [,…n] 中,可以多次指定同一个文件组。如果 n 不足以拥有在分区函数中指定的分区数,则 CREATE PARTITION SCHEME 将失败,并返回错误。
6,
如果分区函数生成的分区数少于创建分区方案时提供的文件组数,则分区方案中第一个未分配的文件组将被标记为 NEXT USED,并且出现显示命名 NEXT USED 文件组的信息。如果指定了 ALL,则单独的文件组将为该分区函数保持它的NEXT USED 属性。如果在 ALTER PARTITION FUNCTION 语句中创建了一个分区,则 NEXT USED 文件组将再接收一个分区。若要再创建一个未分配的文件组来拥有新的分区,请使用 ALTER PARTITION SCHEME。
分区方案例子1:下面的代码先创建一个分区函数,然后再创建这个分区函数使用的分区方案,这个分区方案
将每个分区映射到不同文件组
。代码如下:
create
partition
function
MyPF1
(
int
)
as
range
left
for
values
(
500000
,
1000000
,
1500000
)
go
create
partition
scheme
MyPS1
as
partition
MyPF1
to
(
fg1
,
fg2
,
fg3
,
fg4
)
文件组、分区和分区边界值范围之间的关系如下表:
|
文件组
|
分区
|
取值范围
|
|
fg1
|
1
|
(
负无穷 ,500000] |
|
fg2
|
2
|
[500001,1000000]
|
|
fg3
|
3
|
[1000001,1500000]
|
|
fg4
|
4
|
[1500001,
正无穷 ) |
分区方案例子2:下面的代码先创建一个分区函数,然后再创建这个分区函数使用的分区方案,这个分区方案
将多个分区映射到同一个文件组
。代码如下:
create
partition
function
MyPF2
(
int
)
as
range
left
for
values
(
500000
,
1000000
,
1500000
)
go
create
partition
scheme
MyPS2
as
partition
MyPF2
to
(
fg1
,
fg1
,
fg1
,
fg2
)
文件组、分区和分区边界值范围之间的关系如下表:
|
文件组
|
分区
|
取值范围
|
|
fg1
|
1
|
(
负无穷 ,500000] |
|
Fg1
|
2
|
[500001,1000000]
|
|
Fg1
|
3
|
[1000001,1500000]
|
|
Fg2
|
4
|
[1500001,
正无穷 ) |
分区方案例子3:下面的代码先创建一个分区函数,然后再创建这个分区函数使用的分区方案,这个分区方案
将所有分区映射到同一个文件组
。代码如下:
create
partition
function
MyPF3
(
int
)
as
range
left
for
values
(
500000
,
1000000
,
1500000
)
go
create
partition
scheme
MyPS3
as
partition
MyPF3
all to
(
fg1
)
文件组、分区和分区边界值范围之间的关系如下表:
|
文件组
|
分区
|
取值范围
|
|
fg1
|
1
|
(
负无穷 ,500000] |
|
Fg1
|
2
|
[500001,1000000]
|
|
Fg1
|
3
|
[1000001,1500000]
|
|
Fg1
|
4
|
[1500001,
正无穷 ) |
分区方案例子4:下面的代码先创建一个分区函数,然后再创建这个分区函数使用的分区方案,这个分区方案
指定了“NEXT USED”
文件组。代码如下:
create
partition
function
MyPF4
(
int
)
as
range
left
for
values
(
500000
,
1000000
,
1500000
)
–4
个分区
go
create
partition
scheme
MyPS4
as
partition
MyPF4
to
(
fg1
,
fg2
,
fg3
,
fg4
,
fg5
)
–5
个文件组
那么文件组fg5将自动被标记为
“NEXT USED”
文件组
。
分区方案例子5:下面的代码先创建一个分区函数,然后再创建这个分区函数使用的分区方案,这个分区方案
指定了“
[primary]
”
文件组
。代码如下:
create
partition
function
MyPF5
(
datetime
)
range
right
for
values
(
‘2008/01/01’
,
‘2009/01/01’
)
go
create
partition
scheme
MyPS5
as
partition
MyPF5
to
(
[primary]
,
fg1
,
fg2
)
最后必须明白一点,一张表最多只能有
1000
个分区。
分区表
在分区函数和分区方案创建完成后,创建分区表的准备工作已经完成。我们看一个完整的例子,代码如下:
—
创建分区函数
create
partition
function
MyPF
(
datetime
)
range
right
for
values
(
‘2007-1-1’
,
‘2008-1-1’
)
go
—
创建分区方案
create
partition
scheme
MyPS
as
partition
MyPF
to
(
fg1
,
fg2
,
fg3
)
go
—
创建分区表
create
table
orders
(
OrderID
int
identity
(
1
,
1
)
primary
key
,
int
identity
(
1
,
1
)
primary
key
,
OrderDate
datetime
,
datetime
,
CustID
varchar
(
10
)
varchar
(
10
)
)
on
MyPS
(
OrderDate
)
更完整的例子请关注实战分区表,我会用一个完整的
Demo
来演示分区表这一技术。
Demo
来演示分区表这一技术。
下一节内容包裹:
1,
实战分区表
2,
查询某个分区
3,
增加分区
4,
删除分区
5,
归档数据
通过上2篇博文,我们了解了分区表的理论,这一节就开始实战。本篇博文的内容如下:
1,建立分区表
2,查询分区
3,归档数据
4,添加分区
5,删除分区
6,查看元数据
PS下:最近收到很多朋友的消息和邮件,大多是关于数据库的问题,没有一一答复,由于平时工作比较忙,博客更新的比较慢,在这里说声抱歉。
OK,我们以一个销售数据库场景开始分区表实战。
第一步:建立我们要使用的数据库,最重要的是建立多个文件组。
CREATE
DATABASE
Sales
ON
PRIMARY
(
NAME
= N
‘Sales’
,
FILENAME
= N
‘C:\Sales.mdf’
,
SIZE
= 3MB,
MAXSIZE = 100MB,
FILEGROWTH
= 10%
),
FILEGROUP FG1
(
NAME
= N
‘File1’
,
FILENAME
= N
‘C:\File1.ndf’
,
SIZE
= 1MB,
MAXSIZE = 100MB,
FILEGROWTH
= 10%
),
FILEGROUP FG2
(
NAME
= N
‘File2’
,
FILENAME
= N
‘C:\File2.ndf’
,
SIZE
= 1MB,
MAXSIZE = 100MB,
FILEGROWTH
= 10%
),
FILEGROUP FG3
(
NAME
= N
‘File3’
,
FILENAME
= N
‘C:\File3.ndf’
,
SIZE
= 1MB,
MAXSIZE = 100MB,
FILEGROWTH
= 10%
)
LOG
ON
(
NAME
= N
‘Sales_Log’
,
FILENAME
= N
‘C:\Sales_Log.ldf’
,
SIZE
= 1MB,
MAXSIZE = 100MB,
FILEGROWTH
= 10%
)
GO
第二步:建立分区函数,这里我们建立三个分区。 how(如何对数据进行分区)
USE
Sales
GO
CREATE
PARTITION FUNCTION pf_OrderDate (
datetime
)
AS
RANGE
RIGHT
FOR
VALUES
(
‘2003/01/01’
,
‘2004/01/01’
)
–n不能超过 999,创建的分区数等于 n + 1
GO
第三步:创建分区方案,关联到分区函数 。 where(在哪里对数据进行分区)
USE
Sales
GO
CREATE
PARTITION SCHEME ps_OrderDate
AS
PARTITION pf_OrderDate
TO
(FG1, FG2, FG3)
GO
第四步:创建分区表。创建表并将其绑定到分区方案。这里我们建立2个表,表的结构一样。其中OrdersHistory表用于保存归档数据。
USE
Sales
GO
CREATE
TABLE
dbo.Orders
(
OrderID
int
identity(10000,1),
OrderDate
datetime
NOT
NULL
,
CustomerID
int
NOT
NULL
,
CONSTRAINT
PK_Orders
PRIMARY
KEY
(OrderID, OrderDate)
)
ON
ps_OrderDate (OrderDate)
GO
CREATE
TABLE
dbo.OrdersHistory
(
OrderID
int
identity(10000,1),
OrderDate
datetime
NOT
NULL
,
CustomerID
int
NOT
NULL
,
CONSTRAINT
PK_OrdersHistory
PRIMARY
KEY
(OrderID, OrderDate)
)
ON
ps_OrderDate (OrderDate)
GO
通过以上四步,我们建立了分区表。接着我们要插入一些数据,来进行数据归档,分区查询等。
向数据表中写入2002年的范例数据
USE
Sales
GO
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2002/6/25’
, 1000)
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2002/8/13’
, 1000)
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2002/8/25’
, 1000)
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2002/9/23’
, 1000)
GO
向数据表中写入2003年的范例数据
USE
Sales
GO
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2003/6/25’
, 1000)
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2003/8/13’
, 1000)
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2003/8/25’
, 1000)
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2003/9/23’
, 1000)
GO
我们可以用下面的代码查询这2表:
SELECT
*
FROM
dbo.Orders
SELECT
*
FROM
dbo.OrdersHistory
查询的结果是Orders里面有8行数据,而OrdersHistory还没有数据。因为我们还没归档数据,所以OrdersHistory表还没有数据。
插入完数据后,我们来做如下实验:
1,查询某个分区
这里我们要用到$PARTITION 函数,这个函数可以帮助我们查询某个分区的数据,还可以检索某个值所隶属的分区号。$PARTITION 函数的进一步细节可以查看MSDN
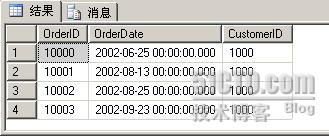
查询已分区表Order的第一个分区,代码如下:
SELECT
*
FROM
dbo.Orders
WHERE
$PARTITION.pf_OrderDate(OrderDate) = 1
查询结果只包含2002年的数据,如下图:
如果想获得2003年的数据,需要如下的代码:
SELECT
*
FROM
dbo.Orders
WHERE
$PARTITION.pf_OrderDate(OrderDate) = 2
我们还可以查询某个分区有多少行数据,代码如下:
SELECT
$PARTITION.pf_OrderDate(OrderDate)
AS
Partition,
COUNT
(*)
AS
[
COUNT
]
FROM
dbo.Orders
GROUP
BY
$PARTITION.pf_OrderDate(OrderDate)
ORDER
BY
Partition ;
我们还可以通过$PARTITION 函数获得一组分区标示列值的分区号,例如获得2002属于哪个分区,代码如下:
SELECT
Sales.$PARTITION.pf_OrderDate(
‘2002’
)
很明显,2002年隶属于第1个分区,因为我们建立分区函数时用了
RANGE
RIGHT,
所以返回1。你也可以把2002年换成2003,2004,2005,2009等等测试。你会发现,2003年属于第2个分区,2004年以后的都属于第3个分区。
RANGE
RIGHT,
所以返回1。你也可以把2002年换成2003,2004,2005,2009等等测试。你会发现,2003年属于第2个分区,2004年以后的都属于第3个分区。
2,归档数据
假如现在是2003年年初,那么我们就可以把2002年所有的交易记录归档到历史订单表HistoryOrder中。代码如下:
USE
Sales
GO
ALTER
TABLE
dbo.Orders SWITCH PARTITION 1
TO
dbo.OrdersHistory PARTITION 1
GO
此时如果我们再执行如下代码:
SELECT
*
FROM
dbo.Orders
SELECT
*
FROM
dbo.OrdersHistory
便会发现,Orders 表只剩2003年的数据,而OrdersHistory表中包含了2002年的数据。
当然如果到了2004年年初,我们也可以归档2003年的所有交易数据。代码如下:
USE
Sales
GO
ALTER
TABLE
dbo.Orders SWITCH PARTITION 2
TO
dbo.OrdersHistory PARTITION 2
GO
3,添加分区
由于目前我们只有三分分区,而这三个分区的区间如下:
|
文件组 |
分区 |
取值范围 |
|
FG1 |
1 |
( 过去某年 , 2003/01/01 ) |
|
Fg2 |
2 |
[ 2003/01/01 , 2004/01/01 ) |
|
Fg3 |
3 |
[ 2004/01/01 , 未来某年 ) |
所以假如到了2005年年初,我们需要为2005年的交易记录准备分区,代码如下:
USE
Sales
GO
ALTER
PARTITION SCHEME ps_OrderDate NEXT USED FG2
ALTER
PARTITION FUNCTION pf_OrderDate() SPLIT RANGE (
‘2005/01/01’
)
GO
ALTER
PARTITION SCHEME ps_OrderDate NEXT USED FG2 用来指定新分区的数据存储在那个文件。这里NEXT USED FG2 代表我们将新分区的数据保存在FG2文件组中,当然我们也可以在原有数据库上新建一个文件组,把新分区的数据保存在新文件组当中,这里我们直接用FG2文件组。
ALTER
PARTITION FUNCTION pf_OrderDate() SPLIT RANGE (
‘2005/01/01’
) 代表我们创建一个新分区,而这里SPLIT RANGE (
‘2005/01/01’
)正是创建新分区的关键语法。
执行完上面的代码之后,我们就有了4个分区,此时的区间如下:
|
文件组 |
分区 |
取值范围 |
|
FG1 |
1 |
( 过去某年 , 2003/01/01 ) |
|
Fg2 |
2 |
[ 2003/01/01 , 2004/01/01 ) |
|
Fg3 |
3 |
[ 2004/01/01 , 2005/01/01 ) |
|
Fg2 |
4 |
[ 2005/01/01 , 未来某年 ) |
4,
删除分区
删除分区
删除分区又称为合并分区,假如我们想合并2002年的分区和2003年的分区到一个分区,我们可以用如下的代码:
USE
Sales
GO
ALTER
PARTITION FUNCTION pf_OrderDate() MERGE RANGE (
‘2003/01/01’
)
GO
执行完上面的代码,此时分区区间如下:
|
文件组 |
分区 |
取值范围 |
|
Fg2 |
1 |
[ 过去某年 , 2004/01/01 ) |
|
Fg3 |
2 |
[ 2004/01/01 , 2005/01/01 ) |
|
Fg2 |
3 |
[ 2005/01/01 , 未来某年 ) |
合并2002和2003年的数据到2003年之后,我们执行如下代码:
SELECT
Sales.$PARTITION.pf_OrderDate(
‘2003’
)
你会发现返回的结果是1。而原来返回的是2,原因是2002年以前数据所在的那个分区合并到了2003年这个分区中了。
假如此时我们执行如下代码:
SELECT
*
FROM
dbo.OrdersHistory
WHERE
$PARTITION.pf_OrderDate(OrderDate) = 2
结果一行数据都没返回,事实就这样,因为OrdersHistory 表中只存储了2002和2003年的历史数据,在没有合并分区之前,执行上面的代码肯定会查询出2003年的数据,但是合并了分区之后,上面代码实际查询的是第二个分区中2004年的数据。
不过当我们改成如下的代码:
SELECT
*
FROM
dbo.OrdersHistory
WHERE
$PARTITION.pf_OrderDate(OrderDate) = 1
便会查询出8行数据,包括2002年和2003年的数据,因为合并分区后2002年和2003年的数据都成了第1个分区的数据了。
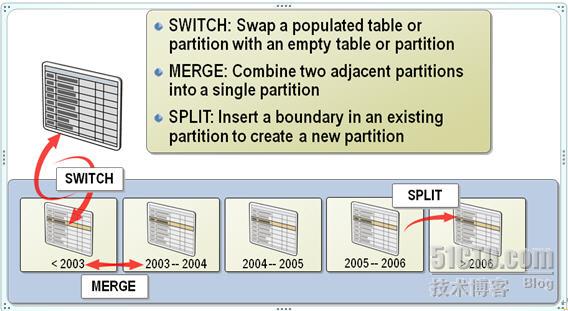
通过图形我们来回忆下归档数据、添加分区、合并分区。
5,查看元数据
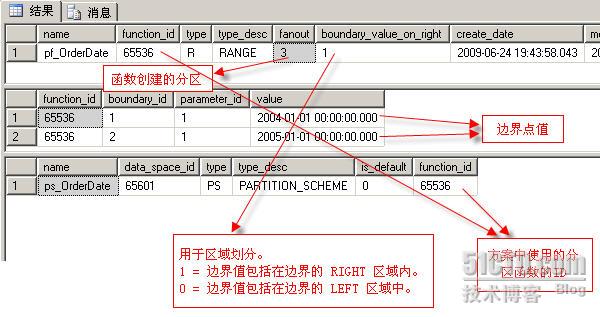
我们可以通过以下三个视图来观察我们创建的分区函数,分区方案,边界点值等。
select
*
from
sys.partition_functions
select
*
from
sys.partition_range_values
select
*
from
sys.partition_schemes
查询的结果如下图:
本文出自 “
李涛的技术专栏
” 博客,请务必保留此出处
http://terryli.blog.51cto.com/704315/169601
通过上2篇博文,我们了解了分区表的理论,这一节就开始实战。本篇博文的内容如下:
1,建立分区表
2,查询分区
3,归档数据
4,添加分区
5,删除分区
6,查看元数据
PS下:最近收到很多朋友的消息和邮件,大多是关于数据库的问题,没有一一答复,由于平时工作比较忙,博客更新的比较慢,在这里说声抱歉。
OK,我们以一个销售数据库场景开始分区表实战。
第一步:建立我们要使用的数据库,最重要的是建立多个文件组。
CREATE
DATABASE
Sales
ON
PRIMARY
(
NAME
= N
‘Sales’
,
FILENAME
= N
‘C:\Sales.mdf’
,
SIZE
= 3MB,
MAXSIZE = 100MB,
FILEGROWTH
= 10%
),
FILEGROUP FG1
(
NAME
= N
‘File1’
,
FILENAME
= N
‘C:\File1.ndf’
,
SIZE
= 1MB,
MAXSIZE = 100MB,
FILEGROWTH
= 10%
),
FILEGROUP FG2
(
NAME
= N
‘File2’
,
FILENAME
= N
‘C:\File2.ndf’
,
SIZE
= 1MB,
MAXSIZE = 100MB,
FILEGROWTH
= 10%
),
FILEGROUP FG3
(
NAME
= N
‘File3’
,
FILENAME
= N
‘C:\File3.ndf’
,
SIZE
= 1MB,
MAXSIZE = 100MB,
FILEGROWTH
= 10%
)
LOG
ON
(
NAME
= N
‘Sales_Log’
,
FILENAME
= N
‘C:\Sales_Log.ldf’
,
SIZE
= 1MB,
MAXSIZE = 100MB,
FILEGROWTH
= 10%
)
GO
第二步:建立分区函数,这里我们建立三个分区。 how(如何对数据进行分区)
USE
Sales
GO
CREATE
PARTITION FUNCTION pf_OrderDate (
datetime
)
AS
RANGE
RIGHT
FOR
VALUES
(
‘2003/01/01’
,
‘2004/01/01’
)
–n不能超过 999,创建的分区数等于 n + 1
GO
第三步:创建分区方案,关联到分区函数 。 where(在哪里对数据进行分区)
USE
Sales
GO
CREATE
PARTITION SCHEME ps_OrderDate
AS
PARTITION pf_OrderDate
TO
(FG1, FG2, FG3)
GO
第四步:创建分区表。创建表并将其绑定到分区方案。这里我们建立2个表,表的结构一样。其中OrdersHistory表用于保存归档数据。
USE
Sales
GO
CREATE
TABLE
dbo.Orders
(
OrderID
int
identity(10000,1),
OrderDate
datetime
NOT
NULL
,
CustomerID
int
NOT
NULL
,
CONSTRAINT
PK_Orders
PRIMARY
KEY
(OrderID, OrderDate)
)
ON
ps_OrderDate (OrderDate)
GO
CREATE
TABLE
dbo.OrdersHistory
(
OrderID
int
identity(10000,1),
OrderDate
datetime
NOT
NULL
,
CustomerID
int
NOT
NULL
,
CONSTRAINT
PK_OrdersHistory
PRIMARY
KEY
(OrderID, OrderDate)
)
ON
ps_OrderDate (OrderDate)
GO
通过以上四步,我们建立了分区表。接着我们要插入一些数据,来进行数据归档,分区查询等。
向数据表中写入2002年的范例数据
USE
Sales
GO
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2002/6/25’
, 1000)
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2002/8/13’
, 1000)
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2002/8/25’
, 1000)
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2002/9/23’
, 1000)
GO
向数据表中写入2003年的范例数据
USE
Sales
GO
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2003/6/25’
, 1000)
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2003/8/13’
, 1000)
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2003/8/25’
, 1000)
INSERT
INTO
dbo.Orders (OrderDate, CustomerID)
VALUES
(
‘2003/9/23’
, 1000)
GO
我们可以用下面的代码查询这2表:
SELECT
*
FROM
dbo.Orders
SELECT
*
FROM
dbo.OrdersHistory
查询的结果是Orders里面有8行数据,而OrdersHistory还没有数据。因为我们还没归档数据,所以OrdersHistory表还没有数据。
插入完数据后,我们来做如下实验:
1,查询某个分区
这里我们要用到$PARTITION 函数,这个函数可以帮助我们查询某个分区的数据,还可以检索某个值所隶属的分区号。$PARTITION 函数的进一步细节可以查看MSDN
查询已分区表Order的第一个分区,代码如下:
SELECT
*
FROM
dbo.Orders
WHERE
$PARTITION.pf_OrderDate(OrderDate) = 1
查询结果只包含2002年的数据,如下图:
如果想获得2003年的数据,需要如下的代码:
SELECT
*
FROM
dbo.Orders
WHERE
$PARTITION.pf_OrderDate(OrderDate) = 2
我们还可以查询某个分区有多少行数据,代码如下:
SELECT
$PARTITION.pf_OrderDate(OrderDate)
AS
Partition,
COUNT
(*)
AS
[
COUNT
]
FROM
dbo.Orders
GROUP
BY
$PARTITION.pf_OrderDate(OrderDate)
ORDER
BY
Partition ;
我们还可以通过$PARTITION 函数获得一组分区标示列值的分区号,例如获得2002属于哪个分区,代码如下:
SELECT
Sales.$PARTITION.pf_OrderDate(
‘2002’
)
很明显,2002年隶属于第1个分区,因为我们建立分区函数时用了
RANGE
RIGHT,
所以返回1。你也可以把2002年换成2003,2004,2005,2009等等测试。你会发现,2003年属于第2个分区,2004年以后的都属于第3个分区。
RANGE
RIGHT,
所以返回1。你也可以把2002年换成2003,2004,2005,2009等等测试。你会发现,2003年属于第2个分区,2004年以后的都属于第3个分区。
2,归档数据
假如现在是2003年年初,那么我们就可以把2002年所有的交易记录归档到历史订单表HistoryOrder中。代码如下:
USE
Sales
GO
ALTER
TABLE
dbo.Orders SWITCH PARTITION 1
TO
dbo.OrdersHistory PARTITION 1
GO
此时如果我们再执行如下代码:
SELECT
*
FROM
dbo.Orders
SELECT
*
FROM
dbo.OrdersHistory
便会发现,Orders 表只剩2003年的数据,而OrdersHistory表中包含了2002年的数据。
当然如果到了2004年年初,我们也可以归档2003年的所有交易数据。代码如下:
USE
Sales
GO
ALTER
TABLE
dbo.Orders SWITCH PARTITION 2
TO
dbo.OrdersHistory PARTITION 2
GO
3,添加分区
由于目前我们只有三分分区,而这三个分区的区间如下:
|
文件组 |
分区 |
取值范围 |
|
FG1 |
1 |
( 过去某年 , 2003/01/01 ) |
|
Fg2 |
2 |
[ 2003/01/01 , 2004/01/01 ) |
|
Fg3 |
3 |
[ 2004/01/01 , 未来某年 ) |
所以假如到了2005年年初,我们需要为2005年的交易记录准备分区,代码如下:
USE
Sales
GO
ALTER
PARTITION SCHEME ps_OrderDate NEXT USED FG2
ALTER
PARTITION FUNCTION pf_OrderDate() SPLIT RANGE (
‘2005/01/01’
)
GO
ALTER
PARTITION SCHEME ps_OrderDate NEXT USED FG2 用来指定新分区的数据存储在那个文件。这里NEXT USED FG2 代表我们将新分区的数据保存在FG2文件组中,当然我们也可以在原有数据库上新建一个文件组,把新分区的数据保存在新文件组当中,这里我们直接用FG2文件组。
ALTER
PARTITION FUNCTION pf_OrderDate() SPLIT RANGE (
‘2005/01/01’
) 代表我们创建一个新分区,而这里SPLIT RANGE (
‘2005/01/01’
)正是创建新分区的关键语法。
执行完上面的代码之后,我们就有了4个分区,此时的区间如下:
|
文件组 |
分区 |
取值范围 |
|
FG1 |
1 |
( 过去某年 , 2003/01/01 ) |
|
Fg2 |
2 |
[ 2003/01/01 , 2004/01/01 ) |
|
Fg3 |
3 |
[ 2004/01/01 , 2005/01/01 ) |
|
Fg2 |
4 |
[ 2005/01/01 , 未来某年 ) |
4,
删除分区
删除分区
删除分区又称为合并分区,假如我们想合并2002年的分区和2003年的分区到一个分区,我们可以用如下的代码:
USE
Sales
GO
ALTER
PARTITION FUNCTION pf_OrderDate() MERGE RANGE (
‘2003/01/01’
)
GO
执行完上面的代码,此时分区区间如下:
|
文件组 |
分区 |
取值范围 |
|
Fg2 |
1 |
[ 过去某年 , 2004/01/01 ) |
|
Fg3 |
2 |
[ 2004/01/01 , 2005/01/01 ) |
|
Fg2 |
3 |
[ 2005/01/01 , 未来某年 ) |
合并2002和2003年的数据到2003年之后,我们执行如下代码:
SELECT
Sales.$PARTITION.pf_OrderDate(
‘2003’
)
你会发现返回的结果是1。而原来返回的是2,原因是2002年以前数据所在的那个分区合并到了2003年这个分区中了。
假如此时我们执行如下代码:
SELECT
*
FROM
dbo.OrdersHistory
WHERE
$PARTITION.pf_OrderDate(OrderDate) = 2
结果一行数据都没返回,事实就这样,因为OrdersHistory 表中只存储了2002和2003年的历史数据,在没有合并分区之前,执行上面的代码肯定会查询出2003年的数据,但是合并了分区之后,上面代码实际查询的是第二个分区中2004年的数据。
不过当我们改成如下的代码:
SELECT
*
FROM
dbo.OrdersHistory
WHERE
$PARTITION.pf_OrderDate(OrderDate) = 1
便会查询出8行数据,包括2002年和2003年的数据,因为合并分区后2002年和2003年的数据都成了第1个分区的数据了。
通过图形我们来回忆下归档数据、添加分区、合并分区。
5,查看元数据
我们可以通过以下三个视图来观察我们创建的分区函数,分区方案,边界点值等。
select
*
from
sys.partition_functions
select
*
from
sys.partition_range_values
select
*
from
sys.partition_schemes
查询的结果如下图:
评论这张

转发至微博