布隆过滤器
本质上布隆过滤器是一种数据结构,可以用来告诉你 “某样东西一定不存在或者可能存在”。
如果我们平时常用的List,set,map ,tree 来实现同样的效果,set和map都是采用map的数据结构,时间复杂度是O1级别。但是map 需要保存所有存在的数据,当数据量非常大的时候,消耗的内存是非常大的。布隆过滤器可以极大减小这种内存消耗,但同样会造成部分不存在的数据,误判为存在。可以通过底层维护的bit数组的长度,来调整数据的误判率。
布隆过滤器是一个 bit 向量或者说 bit 数组:
当我们输入 “线性代数” ,通过计算3个不同的hash计算公式,将值映射到1,3,5这个几个数组上面去,当我们输入 “线性代数”这 个值,映射到1,3,5上面的时候,发现这几个位置都被映射过了,就可以判断 线性代数 代数可能存在。
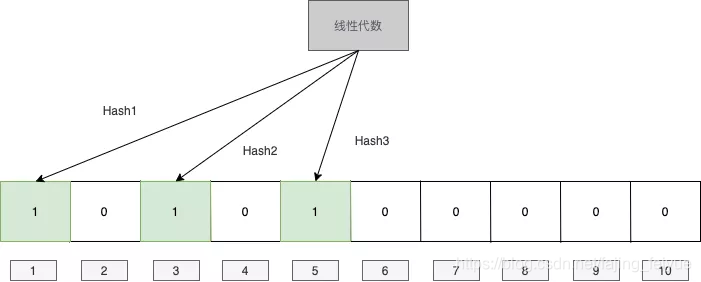
当我们再输入 “高等数学” ,通过计算3个不同的hash计算公式,将值映射到1,8,9这个几个数组上面去,这个时候 1,3,5,8,9这几个位置都有被映射过了。
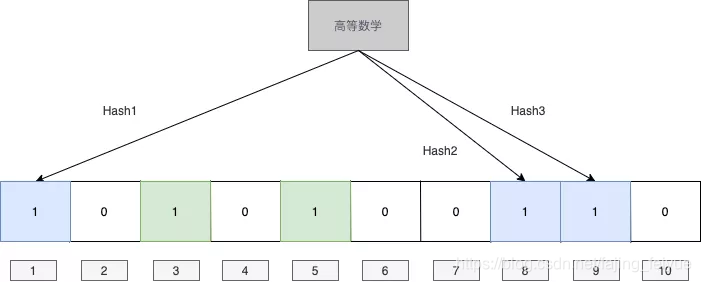
如果我们判断 “概率论” 是否存在的时候,将值进行三种hash运算映射到1,2,3 。发现2没有被映射过,所以可以判断 “概率论” 不存在。 但是也有可能当输入“线性代数” 到映射到1,5,8这三个位置都被映射过了,此时发生误判,认为 “线性代数” 可能存在。
利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。一般运用场景防止缓存穿透,对垃圾邮件、短信的过滤,推荐非重复消息。
布隆过滤器中的google过滤器相对于redis布隆过滤器有以下的缺点
基于JVM内存的一种布隆过滤器
重启即失效
本地内存无法用在分布式场景
不支持大数据量存储
redis布隆 也有相对于google过滤器,需要依赖redis,性能稍差的缺点。
redis布隆过滤器的安装
其中添加过滤器依赖于
redis单机部署redis集群(4.0.14版本)
1.下载redisbloom插件(redis官网下载即可)
https://github.com/RedisLabsModules/redisbloom/
这里使用v1.1.1版本
//新建目录
mkdir redisbloom
cd redisbloom
//下载redis 插件
wget https://github.com/RedisLabsModules/rebloom/archive/v1.1.1.tar.gz
//解压文件
tar -zxvf v1.1.1.tar.gz
//进入解压后的目录
cd RedisBloom-1.1.1/
//编译
make
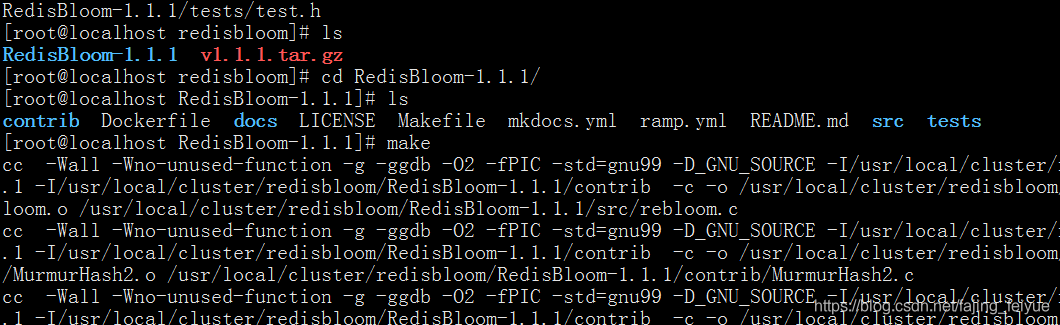
//进入集群目录,添加redis布隆过滤器的插件
cd /usr/local/cluster/7001/redis-4.0.14
vi redis.conf
cd /usr/local/cluster/7002/redis-4.0.14
vi redis.conf
.......
在redis中找到
################################## MODULES #####################################
# Load modules at startup. If the server is not able to load modules
# it will abort. It is possible to use multiple loadmodule directives.
#
# loadmodule /path/to/my_module.so
# loadmodule /path/to/other_module.so
#添加 布隆过滤插件
loadmodule /usr/local/cluster/redisbloom/RedisBloom-1.1.1/rebloom.so
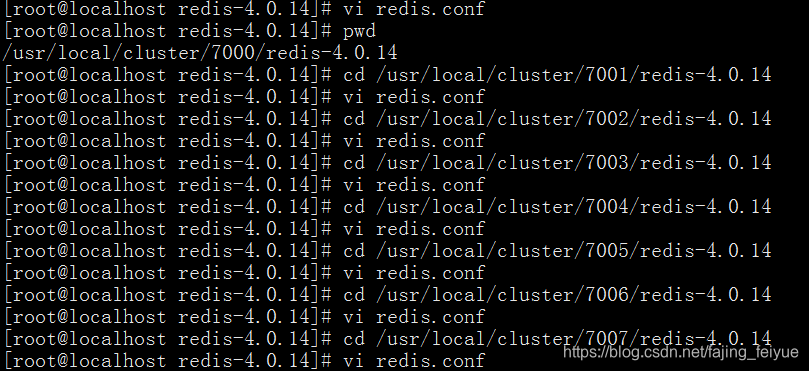
重启redis
./stop.sh
./start.sh
单机版直接启动
./redis-server ../redis.conf

//进入到redis 7000节点
./redis-cli -p 7000 -c
//添加过滤器值
192.168.25.128:7001> bf.add calvinBloom 111
(integer) 1
192.168.25.128:7001> bf.add calvinBloom 222
(integer) 1
192.168.25.128:7001> bf.add calvinBloom 333
(integer) 1
192.168.25.128:7001> bf.exists calvinBloom 111
(integer) 1
192.168.25.128:7001> bf.exists calvinBloom 222
(integer) 1
192.168.25.128:7001> bf.exists calvinBloom 333
三、布隆过滤器的使用
1、引入依赖
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jrebloom</artifactId>
<version>1.2.0</version>
</dependency>
2、加入redis.properties配置文件
#客户端超时时间单位是毫秒 默认是2000
redis.timeout=10000
#最大空闲数
redis.maxIdle=300
#连接池的最大数据库连接数。设为0表示无限制,如果是jedis 2.4以后用redis.maxTotal
#redis.maxActive=600
#控制一个pool可分配多少个jedis实例,用来替换上面的redis.maxActive,如果是jedis 2.4以后用该属性
redis.maxTotal=2000
#最大建立连接等待时间。如果超过此时间将接到异常。设为-1表示无限制。
redis.maxWaitMillis=1000
redis.nodes=192.168.25.128:7000,192.168.25.128:7001,192.168.25.128:7002,192.168.25.128:7003,192.168.25.128:7004,192.168.25.128:7005,192.168.25.128:7006,192.168.25.128:7007
3、引入redis的配置文件
@Configuration
@PropertySource("classpath:conf/redis.properties")
public class RedisConfig {
@Value("${redis.maxIdle}")
private Integer maxIdle;
@Value("${redis.timeout}")
private Integer timeout;
@Value("${redis.maxTotal}")
private Integer maxTotal;
@Value("${redis.maxWaitMillis}")
private Integer maxWaitMillis;
@Value("${redis.nodes}")
private String clusterNodes;
/**
* jedis的正常创建
* @return
*/
@Bean
public JedisCluster getJedisCluster(){
String[] cNodes = clusterNodes.split(",");
HashSet<HostAndPort> nodes = new HashSet<>();
//分割集群节点
for (String node : cNodes) {
String[] hp = node.split(":");
nodes.add(new HostAndPort(hp[0], Integer.parseInt(hp[1])));
}
JedisPoolConfig jedisPoolConfig=new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(maxIdle);
jedisPoolConfig.setMaxWaitMillis(maxWaitMillis);
jedisPoolConfig.setMaxTotal(maxTotal);
//创建集群对象
JedisCluster jedisCluster = new JedisCluster(nodes, timeout, jedisPoolConfig);
return jedisCluster;
}
/**
* bloom过滤器的创建
* @return
*/
@Bean
public ClusterClient initClusterClient() {
GenericObjectPoolConfig config = new GenericObjectPoolConfig();
// 最大连接数
config.setMaxTotal(300);
// 池中保留的最大空闲连接数
config.setMaxIdle(100);
// 池中保留的最小空闲连接数
config.setMinIdle(100);
// 最大等待时间
config.setMaxWaitMillis(5 * 1000);
config.setTestWhileIdle(true);
config.setTestOnBorrow(true);
String[] cNodes = clusterNodes.split(",");
HashSet<HostAndPort> nodes = new HashSet<>();
//分割集群节点
for (String node : cNodes) {
String[] hp = node.split(":");
nodes.add(new HostAndPort(hp[0], Integer.parseInt(hp[1])));
}
ClusterClient clusterClient = new ClusterClient(nodes, 300 * 1000, 300 * 1000, 10, config);// 创建REDIS集群
return clusterClient;
}
}
4、创建BloomJedisService 接口
public interface BloomJedisService {
public boolean createFilter(final String name, final long initCapacity, final double errorRate);
public boolean[] addMulti(final String name, final byte[]... values);
public boolean[] addMulti(final String name, final String... values);
public boolean add(final String name, final String value);
public boolean add(final String name, final byte[] value);
public boolean exists(final String name, final String value);
public boolean exists(final String name, final byte[] value);
public boolean delete(final String name) ;
public boolean[] existsMulti(final String name, final byte[] value);
public boolean[] existsMulti(final String name, final String... values);
public long expire(final String key, final int seconds);
public long expireAt(final String key, final long unixTime);
public long ttl(final String key) ;
/**
* key是否存在
*
* @param key
* @return
*/
public boolean exists(final String key);
}
5、创建BloomJedisServiceImpl 的具体实现
@Service
public class BloomJedisServiceImpl implements BloomJedisService {
public static String prefix = "1_BF_";
@Autowired
private ClusterClient clusterClient;
@Override
public boolean createFilter(final String name, final long initCapacity, final double errorRate) {
return clusterClient.createFilter(prefix + name, initCapacity, errorRate);
}
@Override
public boolean[] addMulti(final String name, final byte[]... values) {
return clusterClient.addMulti(prefix + name, values);
}
@Override
public boolean[] addMulti(final String name, final String... values) {
return clusterClient.addMulti(prefix + name, values);
}
@Override
public boolean add(final String name, final String value) {
return clusterClient.add(prefix + name, value);
}
@Override
public boolean add(final String name, final byte[] value) {
return clusterClient.add(prefix + name, value);
}
@Override
public boolean exists(final String name, final String value) {
return !clusterClient.add(prefix + name, value);
}
@Override
public boolean exists(final String name, final byte[] value) {
return clusterClient.add(prefix + name, value);
}
@Override
public boolean delete(final String name) {
return clusterClient.delete(prefix + name);
}
@Override
public boolean[] existsMulti(final String name, final byte[] value) {
return clusterClient.existsMulti(prefix + name, value);
}
@Override
public boolean[] existsMulti(final String name, final String... values) {
return clusterClient.existsMulti(prefix + name, values);
}
@Override
public long expire(final String key, final int seconds) {
return clusterClient.expire(prefix + key, seconds);
}
@Override
public long expireAt(final String key, final long unixTime) {
return clusterClient.expireAt(prefix + key, unixTime);
}
@Override
public long ttl(final String key) {
return clusterClient.ttl(prefix + key);
}
/**
* key是否存在
*
* @param key
* @return
*/
@Override
public boolean exists(final String key) {
return clusterClient.exists(prefix + key);
}
}
6、测试功能
private static final String testFilter = "test_filter2";
@Test
public void testBloom(){
//创建过滤器(,这里为了测试比较明显,将概率设置大一点)
bloomJedisService.createFilter(testFilter, 50, 0.01);
for (int i = 0; i < 1000; i++) {
bloomJedisService.add(testFilter, ""+i);
}
int j=0;
for (int i = 1001; i < 2000; i++) {
boolean exists = bloomJedisService.exists(testFilter, "" + i);
if(exists){
System.out.println("有误判"+(++j));
}
}
}
测试结果 1000/19=0.02 ,基本能接受
有误判1
有误判2
有误判3
有误判4
有误判5
有误判6
有误判7
有误判8
有误判9
有误判10
有误判11
有误判12
有误判13
有误判14
有误判15
有误判16
有误判17
有误判18
有误判19