达梦数据库的并行设置生效与查看
首先,使用 PARALLEL_POLICY 参数来设置并行策略。取值范围: 0、 1 和 2,默认值0。其中, 0 表示不支持并行; 1 表示自动并行模式; 2 表示手动并行模式。
当开启本地并行(PARALLEL_POLICY>0)时,使用 PARALLEL_THRD_NUM 指定本地
并行查询使用的线程数,取值范围为 1~1024,缺省值为 10。需要注意的是,若
PARALLEL_POLICY=1,如果 PARALLEL_THRD_NUM=1, 则按照 CPU 个数创建并行线程。
使用自动并行模式时,需要设置MAX_PARALLEL_DEGREE 参数,同时确保PARALLEL_POLICY=1
,
不过从我使用数据库的经验来看,一般避免使用自动并行。另外,并行机制关闭也不见的合适,还是建议默认开启,手工设置并行更合适一些。
服务器[localhost:5237]:处于普通打开状态
登录使用时间: 6.248(毫秒)
disql V7.6.0.96-Build(2018.09.19-97292)ENT
Connected to: DM 7.1.6.96
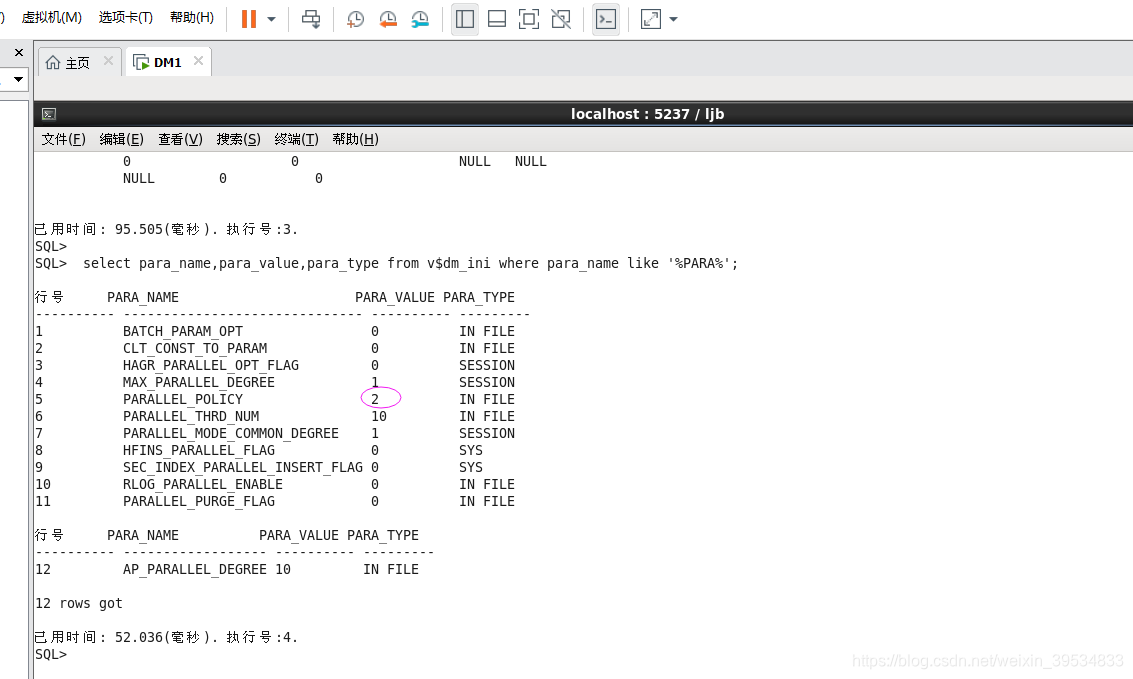
SQL> select para_name,para_value,para_type from v$dm_ini where para_name like ‘%PARA%’;
行号 PARA_NAME PARA_VALUE PARA_TYPE
1 BATCH_PARAM_OPT 0 IN FILE
2 CLT_CONST_TO_PARAM 0 IN FILE
3 HAGR_PARALLEL_OPT_FLAG 0 SESSION
4 MAX_PARALLEL_DEGREE 1 SESSION
5 PARALLEL_POLICY 0 IN FILE
6 PARALLEL_THRD_NUM 10 IN FILE
7 PARALLEL_MODE_COMMON_DEGREE 1 SESSION
8 HFINS_PARALLEL_FLAG 0 SYS
9 SEC_INDEX_PARALLEL_INSERT_FLAG 0 SYS
10 RLOG_PARALLEL_ENABLE 0 IN FILE
11 PARALLEL_PURGE_FLAG 0 IN FILE
12 AP_PARALLEL_DEGREE 10 IN FILE
12 rows got
已用时间: 2.509(毫秒). 执行号:24.
通过vm.ini的修改将
PARALLEL_POLICY改成了2
果然用到了并行
SQL> explain select
/
+PARALLEL(4)
/
DEPARTMENT_ID,COUNT(*) FROM EMPLOYEES GROUP BY DEPARTMENT_ID;
1 #NSET2: [1, 1, 30]
2 #PRJT2: [1, 1, 30]; exp_num(2), is_atom(FALSE)
3 #HAGR2: [1, 1, 30]; grp_num(1), sfun_num(1);
4
#LOCAL COLLECT: [1, 1, 30]; op_id(1) n_grp_by (0) n_cols(0) n_keys(0) for_sync(FALSE)
5 #HAGR2: [1, 1, 30]; grp_num(1), sfun_num(1);
6 #CSCN2: [0, 3, 30]; INDEX33555497(EMPLOYEES)
已用时间: 33.629(毫秒). 执行号:0.
通过去掉HINT,很容易看出来差异
SQL> explain select DEPARTMENT_ID,COUNT(*) FROM EMPLOYEES GROUP BY DEPARTMENT_ID;
1 #NSET2: [1, 1, 30]
2 #PRJT2: [1, 1, 30]; exp_num(2), is_atom(FALSE)
3 #HAGR2: [1, 1, 30]; grp_num(1), sfun_num(1);
4 #CSCN2: [0, 3, 30]; INDEX33555497(EMPLOYEES)
已用时间: 0.609(毫秒). 执行号:0.