项目场景:
论文名称:E2EC:An End-to-End Contour-based Method for High-quality High-Speed Instance Segmentation
代码地址:https://github.com/zhang-tao-whu/e2ec
因为是新发布的文章,在代码上存在一些问题,本文记录本人在运行过程中所遇到的难题及解决措施
问题描述
问题1:本人使用的服务器显卡为2080ti,CUDA版本为10.2,因此不能跟原作者一样安装pytorch1.7.1+cuda11.0的版本,下为作者原步骤
# Set up the python environment
conda create -n e2ec python=3.7
conda activate e2ec
# install pytorch, the cuda version is 11.1
# You can also install other versions of cuda and pytorch, but please make sure # that the pytorch cuda is consistent with the system cuda
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
pip install Cython==0.28.2
pip install -r requirements.txt
问题2:安装好虚拟环境以及相应的库之后,需要Compile cuda extensions,也在INSTALL.md中,这个步骤可能出现一堆问题,作者也有提到
ROOT=/path/to/e2ec
cd $ROOT/network/backbone/DCNv2-master
# please check your cuda version and modify the cuda version in the command
export CUDA_HOME="/usr/local/cuda-11.1"
bash ./make.sh
# Maybe you will encounter some build errors. You can choose a plan :
# 1、You can look for another implementation of DCN-V2 and compiled successfully.
# 2、You can set cfg.model.use_dcn as False. This may result in a slight drop in accuracy.
# 3、You can install mmcv, and replace 352 line of network/backbone/dla.py as from mmcv.ops import ModulatedDeformConv2dPack as DCN, replace the deformable_groups in 353 line as deform_groups.
问题3:/home/ubuntu/anaconda3/envs/e2ec/lib/python3.6/site-packages/torch/nn/functional.py:3226: UserWarning: Default grid_sample and affine_grid behavior has changed to align_corners=False since 1.3.0. Please specify align_corners=True if the old behavior is desired. See the documentation of grid_sample for details. warnings.warn("Default grid_sample and affine_grid behavior has changed"
问题4:UserWarning: indexing with dtype torch.uint8 is now deprecated, please use a dtype torch.bool instead
问题5:UserWarning: Integer division of tensors using div or / is deprecated, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead.
问题6:各种DCN_v2报错问题
问题7:使用cityscapes数据集时,出现Please install the module 'Pillow' for image processing, e.g.
问题8:使用kitti数据集时,出现RuntimeError: received 0 items of ancdata
问题9:使用kitti数据集时,出现RuntimeError: stack expects each tensor to be equal size, but got [3, 768, 2496] at entry 0 and [3, 768, 2496] at entry 1
问题10:使用cityscapes数据集时,出现RuntimeError: CUDA error: an illegal memory access was encountered
问题11:使用原作者的预训练模型去训练自己的数据集,出现模型参数不匹配的错误
解决方案:
针对问题1
conda create -n e2ec python=3.6.5
conda activate e2ec
conda install pytorch==1.5.1 torchvision==0.6.1 cudatoolkit=10.2 -c pytorch
pip3 install Cython==0.28.2
pip3 install -r requirements.txt
针对问题2
首先按照问题1的解决步骤去做,然后再按照下述步骤去做
cd /path/DCNv2-master
export CUDA_HOME="/usr/local/cuda-10.2"
bash ./make.sh
/path/就是DCNv2-master所在的路径,每个人都不同,例如我的

如果成功编译CUDA扩展,则会显示如下结果,否则其他情况,可尝试作者提供的思路去做
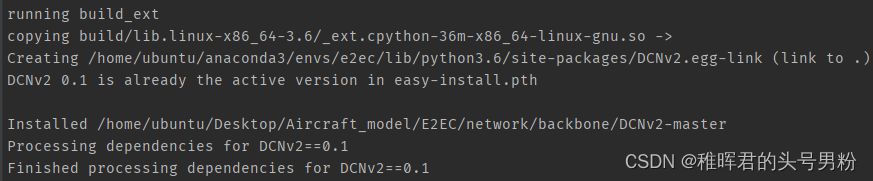
针对问题3
根据错误提示的路径找到相应的文件,比如我的是
/home/ubuntu/anaconda3/envs/e2ec/lib/python3.6/site-packages/torch/nn/functional.py
,找到
3226
行,上下翻动找到
def grid_sample
函数和
def affine_grid
函数,将
align_corners
由
False
改为
True
,如下所示


针对问题4
属于警告类错误,不理也没事,或者在训练时,往 train_net.py 中添加以下内容(用于忽略警告):
import warnings
warnings.filterwarnings("ignore", category = UserWarning)
针对问题5
“今天把pytorch升级到1.6.0,发现tensor和int之间的除法不能直接用’ / ‘,明明1.5.0都是可以用的”
这是网上找到的说法,当然,我试了1.5.0,还是报这个错误…无语,不过这也属于警告类错误
解决方法也是有的,不过要找出全部tensor和int相除的代码,再按如下所示去做
result = A / n # not supported in torch 1.6.0
result = torch.floor_divide(A, n) # 方法1得到的结果为整型
result = torch.true_divide(A, n) # 方法2得到带小数点的数值
针对问题6
我在一个新服务器上重新安装E2EC遇到的。我是/usr/local/cuda-11.7文件夹里没内容,不知道为啥。然后我就从安装过E2EC的服务器拷贝/usr/local/cuda-10.2,具体安装方法就和上面一致即可。需要注意的一点,需要root用户赋予/usr/local/cuda-10.2这个文件夹内全部文件的权限
sudo chmod -R 777 /usr/local/cuda-10.2
针对问题7
Pillow版本过高
pip uninstall pillow
pip install pillow==8.3.1
针对问题8
错误的原因:dataloader加载数据时,pytorch多线程共享tensor是通过打开文件的方式实现的,而打开文件的数量是有限制的,当需共享的tensor超过open files限制时,即会出现该错误。修改多线程的tensor方式为file_system(默认方式为file_descriptor,受限于open files数量):
#训练python脚本中import torch后,加上下面这句。
torch.multiprocessing.set_sharing_strategy('file_system')
针对问题9
也就是说,后面DataLoader()函数处理ImageFolde对象实例的时候,要求数据集中的全部图像的尺寸都是大小一致的,我测试发现,如果不一致,就报这个错误(维数不一致)
# 找到路径 ./e2ec/configs/kitti.py
将 test.test_rescale=0.5 注释掉(正在跑实验看会不会影响效果)
针对问题10
第一种可能你的程序涉及到并行计算,但你只有一张卡,因此只要将程序涉及到并行计算的部分改成单卡即可。也可能其实是某张卡有问题或被某个进程锁了,换块GPU试试看。最后发现是这个test_rescale作妖,无语!
# 找到路径 ./e2ec/configs/cityscapes.py
train.num_workers=2 # 调小点,怕CPU爆了
将 test.test_rescale=0.85 注释掉(正在跑实验看会不会影响效果)
针对问题11
找到./e2ec/train/model_utils/utils.py,将def load_network中的for key1, key2语句注释掉(记得测试时需要还原回来)
pretrained_model = pretrained_model['net']
net_weight = net.state_dict()
# for key1, key2 in zip(net_weight.keys(), pretrained_model.keys()):
# net_weight.update({key1: pretrained_model[key2]})
net.load_state_dict(net_weight, strict=strict)
return epoch