背景
一个服务突然所有机器开始频繁full gc。而服务本身没有任何改动和发布记录。上线查看gc log日志,日志如下:
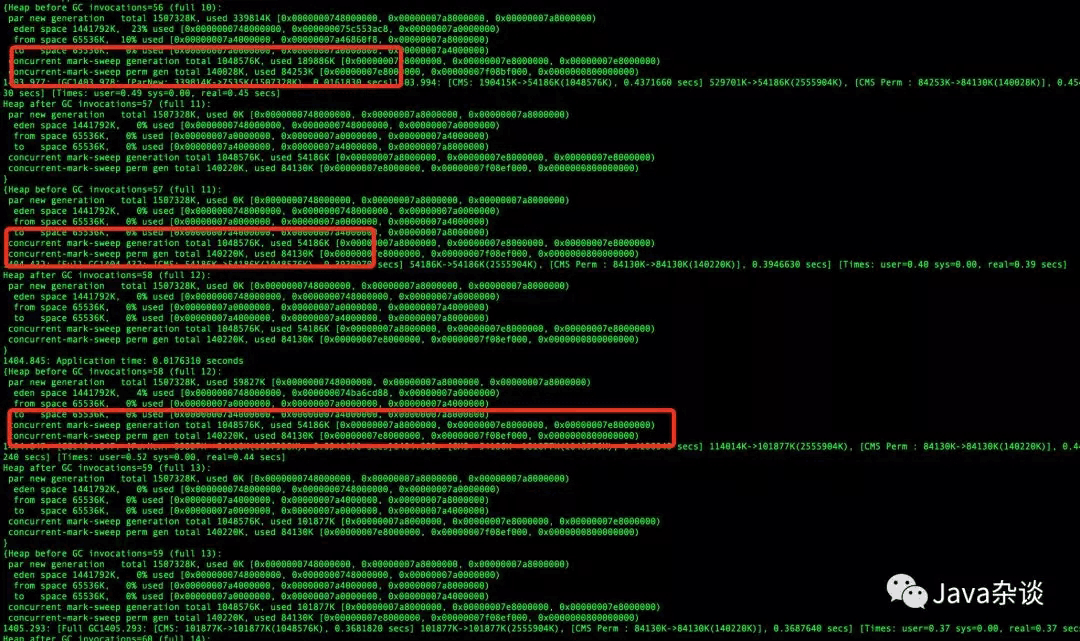
从日志来看,每次发生full gc的时候都比较奇怪,主要有两点,第一、old区域和perm的区域使用率很低,没有到达触发full gc的条件,第二、项目中配置的是CMS,为什么没有进行 CMS GC,直接进行了full gc呢。
查找过程
第一、代码会不会是调用了System.gc()
考虑在使用direct memory的时候,先判断direct memory是否足够,要是不足的话会使用System.gc()尝试释放内存。于是直接使用反射去监控direct memory。发现direct memory的使用率始终在10%左右,不可能去调用System.gc()。
而且此时去查看jvm参数已经禁止显示调用了System.gc()了。
第二、使用 jstat -gccause查看gc原因
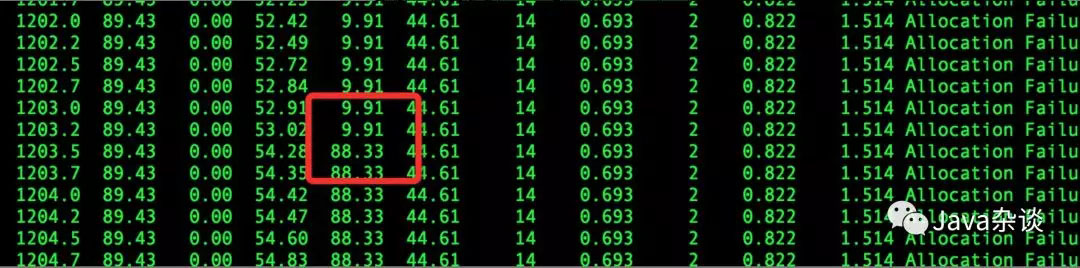
想着要是能找到gc的原因就好了。于是使用 jstat -gccause实时监控gc原因,但是发现始终是Allocation Failure。但是在监控中发现old区域中有突然增加800M,通过我司的监控平台也发现了old区域暴涨的现象。监控如下:
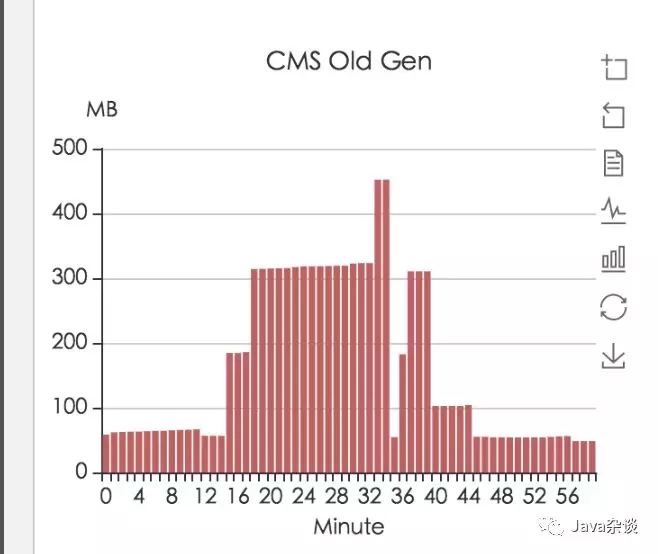
并且通过jmap -histo pid查看old Gen 突变前后内存增加值,发现增加的800M全部是byte[],并且dump内存下来使用MAT查看内存,然后并没有什么收获。
第三、找到有问题开始时候的改动点
因为项目在发生问题的时候并没有改动和上线,基本上就排除代码本身的原因。联系运维告知那个时间点,我们所在的服务节点上部署了log_agent。
log_agent的作用就是把本地日志上报到日志中心存储起来,其架构示意图demo如下:
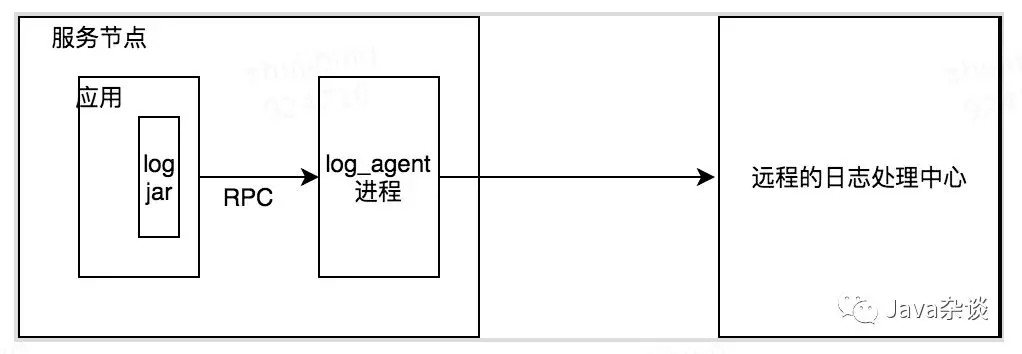
猜着肯定是和log_agent通信的时候有bug导致的,于是让运维帮忙把其中一台机器上的log_agent给删除了,删除之后full gc恢复正常。
到此基本上确定了是日志上报导致的问题。
第四、定位日志上报的jar具体有问题的代码
定位到是日志上报的jar导致的问题之后,就把这个问题反馈给了相关负责人。但是他们追踪了很久之后并没有发现什么问题。
之后有时间之后,我就把他们相关代码看了一下,发现其中有段代码有点问题。有问题代码如下:
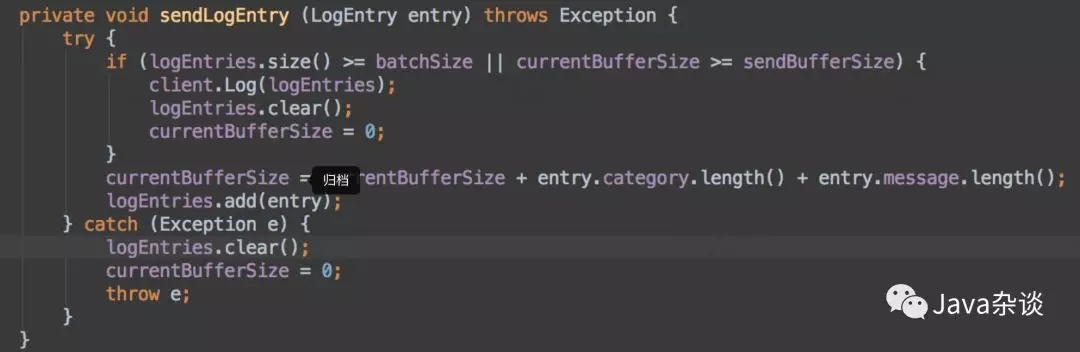
在出入log的的时候在append中会调用sendLogEntry这个方法,而logEntries本身是个list对象,非线程安全的。这样的话,在多个线程中同时输出日志就有安全问题。于是就在sendLogEntry这个方法上加上线程安全(synchronized),上线问题解决,没有发生频繁full gc了。
但是多线程下同时调用list也不应该频繁full gc啊,这个地方有bug,但是不应该导致频繁 full gc。我怀疑是client.Log(logEntries); 这个方法本身不是线程安全的。以为我把线程同步块锁在了client.Log(logEntries);这个代码块上。发现问题也得以解决。
client.Log的代码就是一个发送相关日志、并接收返回值进行确认,使用的是thrift框架进行通信的。于是在接收返回值的地方,给加了点log。代码如下:

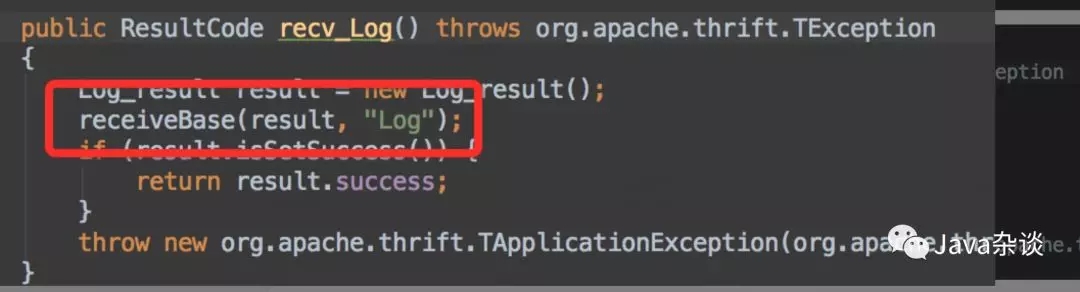
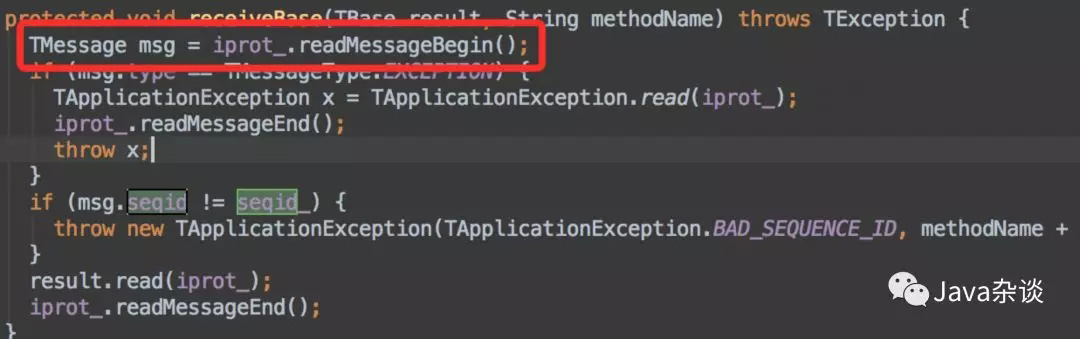
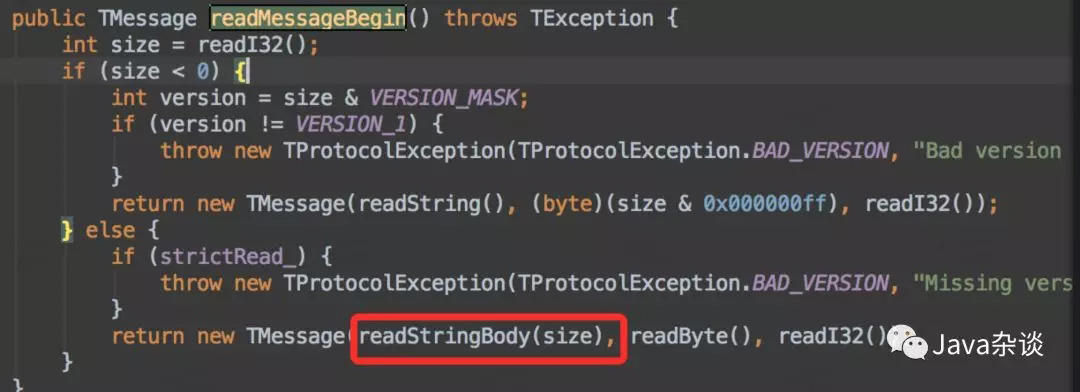
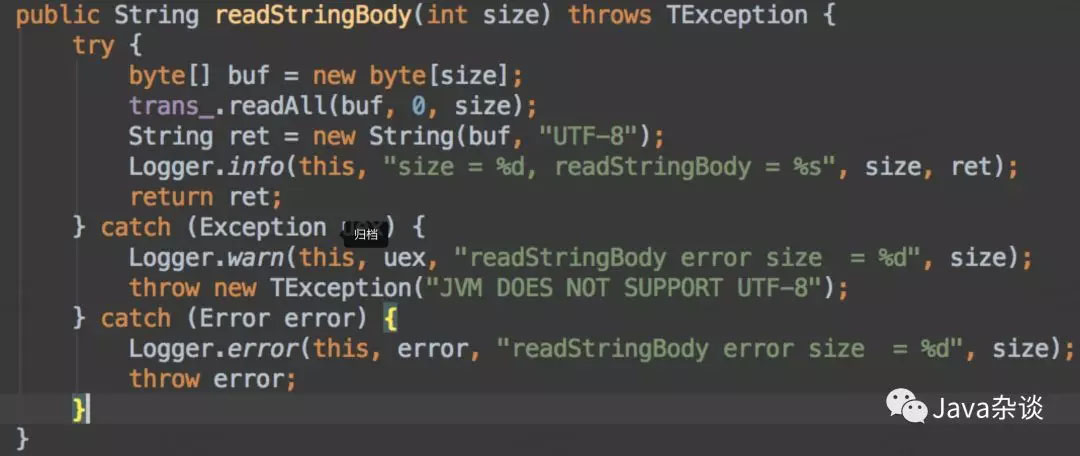

从日志中我们可以看到,从返回值中读取的字节流大小最大达1.2G甚至1.8G,这很明显不正常啊。因为young Gen 1.5G,old Gen 1G,必定会抛OOM。而在最上层捕获了error,但是默认情况下却没有log,导致log中看不出任何问题。
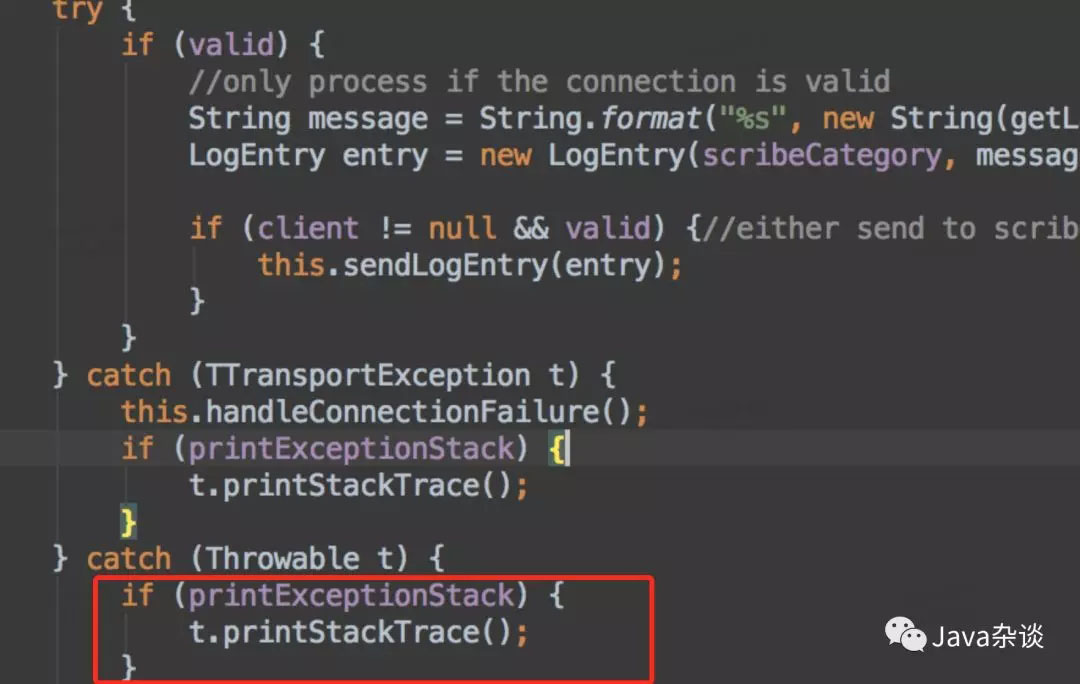
回想起我司RPC服务也是用的thrift是用的连接池的方式,所以client肯定是非线程安全的。
问题定位到之后,准备反馈给那个人。发现那个人已经离职了。于是尝试升级到最新的jar之后,发现他们在sendLogEntry这个方法上加上了synchronized。
总结
上面给出了总结后应该遵循的定位问题步骤。真实的查找过程绝不是按照上面的那个过程来的,这个问题的追查持续了大概两周(每天投入1-2个小时左右吧?)。
主要有两个坑:
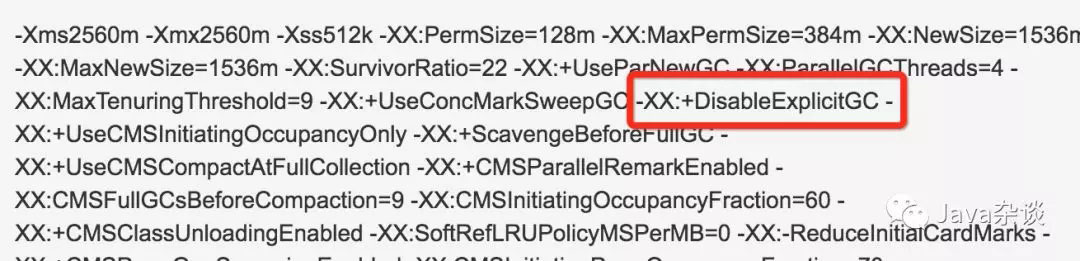
gc log。开始的时候关注点一直在gc log上。从gc log来看根本不满足发生full gc的条件。于是专注点在认为引入的jar有在调System.gc()并没有注意到这个-XX:+DisableExplicitGC参数
对Error的处理。我司日志中心提供的jar居然直接忽略了Error导致了OOM日志一直没有显示出来,不然问题发生时肯定就能直接定位到了。
JVM抛出OOM之后,就算配置的是CMS,JVM仍旧是使用的Full GC来回收内存。因为CMS会有内存碎片化问题,已经发生了OOM,可能是因为没有连续内存存放新申请的对象,Full GC没有内存碎片的问题,所以直接使用Full GC回收的策略是合理的。
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。