点击“计算机视觉life”关注,置顶更快接收消息!
本文经知乎作者原野寻踪授权转载
原文:https://zhuanlan.zhihu.com/p/62059382
近期在调研关于RGBD在室内移动机器人下的语义导航的研究。目前帝国理工的Andrew Davison在这边有两个团队在研究,目前最新的分别是Fusion++ 和 这篇 MaskFusion( 还有MID-Fusion, 之前的SemanticFusion 以及各类Fusion属于这俩分支) 。这篇是我阅读文章时的笔记,整理一下发上来和大家一起分享。文章末尾有关于到移动机器人应用rgbd语义slam的一些小想法,有想法欢迎在评论区一起探讨.
这篇文章在上传到axiv的时候即被Fusion++引用,并被其做了一些苍白的比较:”虽然其能支持动态环境,但该文章并没有完成精细的物体重建,未来二者融合会是不错的方向。”
这句话也可以表述为,支持动态环境的定位系统,毕竟重建不是slam的目的,所以这篇或许更适合来做室内rgbd语义导航。
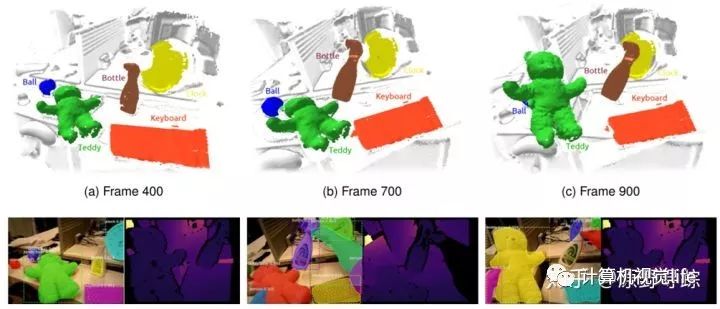
发表在ISMAR2018. 帝国理工.
本文之前作者还有一篇 《Co-fusion》在ICRA2017. (本文提到带分割的co-fusion无法实时)
Abstract
输出纯几何的静态场景地图。
前端使用了image-based的instance-level语义分割。
与之前的recoginition-based slam系统不同,它不需要任何已知模型,而且可以处理多个独立运动。
代码开源:(https://github.com/martinruenz/maskfusion)
Introduction
还处于幼儿期的两个slam方向:
-
slam的静态假设。能够处理任意动态运动和非刚体场景的鲁棒slam系统仍然remain open challege.
-
大部分slam系统输出纯几何地图。语义信息的添加大部分限制于少数已知物体的实例,需要提前建好它们的3D模型。或者将3D地图点聚类成固定的语义类别,而不区分实例。
本文贡献
提出一种实时的SLAM系统,能够提供物体级的场景描述。
整合了两个输出:
-
Mask-RCNN. image-based的实例分割算法,能够预测80多种物体类别。
-
一种基于几何的分割算法[ yeah!], 通过深度和表面法向量线索来生成物体边界地图(object edge map) 增加物体边界的准确性。
注意这里用的分割是实例级的,要比pixel-level还高一级。
与其他实时slam系统的比较:
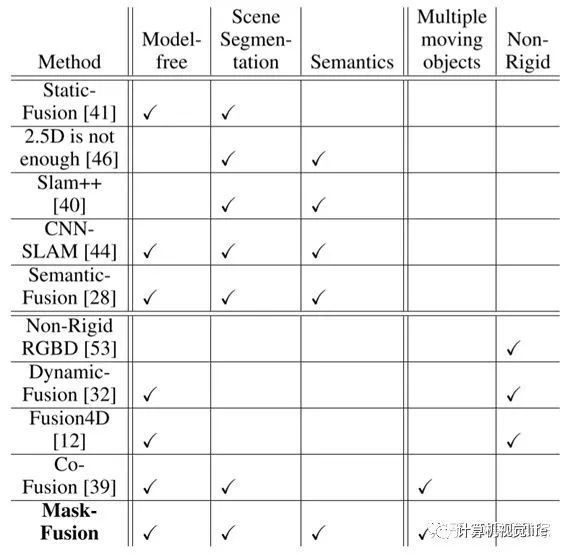
[ related works的笔记,找一些系统特性然后从已有提出的系统中筛选一下即可。比如light-weight localization可以挑选地图大小、定位精度、实时性等.]
Related Works
Dense RGB-D SLAM
KinectFusion中提出 TSDF 模型。然而该模型在建图和跟踪之间转换时需要开销。而surfel-based的RGBD系统,每个element存储了局部表面特征,即半径和法向量,具有高效运算。
…
Semantic SLAM
融合标记的图像数据到分割的3D地图中。由于没有考虑物体实例,所以无法单独跟踪多个物体。
Dynamic SLAM
动态SLAM中有两个主要的场景:非刚体表面重建和多独立运动刚体。
值得注意的文献:
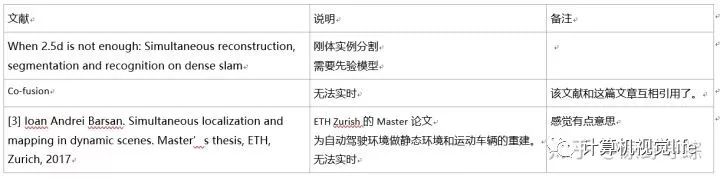
(表格居然无法粘过来..只好放图)
3 System Overview
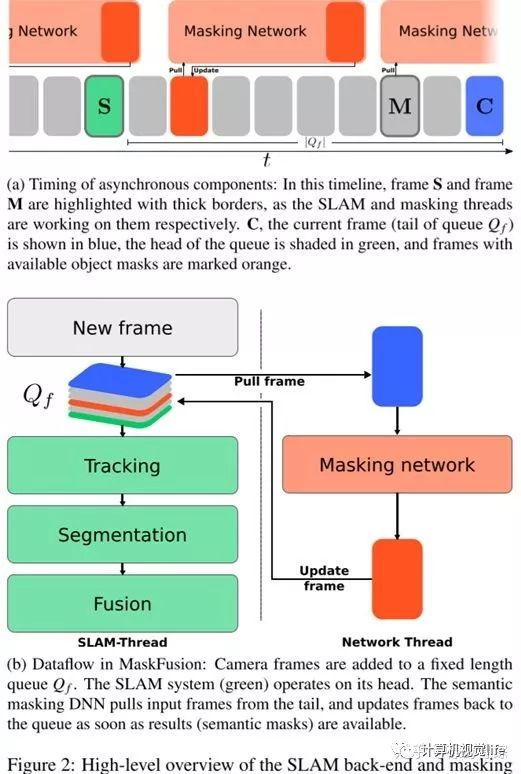
【图片解析:即说明用一个队列来解决mask network耗时较长的问题。让整体系统相对实际世界的时间牺牲一定的延时来等待第一帧mask 产生】 ( 5hz说明200ms一帧 )
每一帧获取之后,执行下列步骤:
跟踪
以surfels表示每个物体的3D几何。最小化一个energy,包括帧内物体和存储的3D模型之间的ICP error,以及考虑光度一致性(类似直接法?),与前一帧的位姿联合。为了高效运算,仅跟踪非静态物体。用两个不同策略判断是否为静态:
-
基于运动一致性,参考[39] Co-fusion.
-
认为被人碰触的物体为动态.
分割
综合了语义和几何信息来做分割。Mask-RCNN有两个缺点:
-
无法实时:5Hz.
-
物体边界不完美,容易渗透到背景去
用几何分割来弥补,基于深度不连续和法向量。几何分割可以实时,而且提供准确的物体边界。
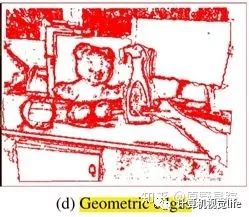

几何边界和几何成分图。
说说几何分割缺点:它倾向于过分割物体。联合两个方法:每一帧进行几何分割,而语义分割则尽量often,于是实现:
-
完整系统实现实时。几何分割用于没有语义物体mask的帧,有语义mask的帧两者都用。
-
有了几何分割,语义物体边界更好了。
融合
surfels会不断随时间融合。类似之前提出的几套三维重建方法。如[23, 50 ElasticFusion]
正文来了!
4 Multi-object SLAM
3d模型的表示用surfel模型。
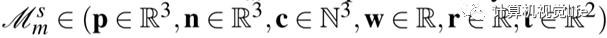
对于每个物体,即如上的u,其中包括位置,法向量,颜色,权重,半径和两个时间戳。此外,每个模型赋予一个类别ID( 0..80 ),以及一个物体标签。对于每个时间戳,给定是否静态的标签,以及存储刚体位姿R和t。
4.1 Tracking
帧间位姿跟踪纯粹基于Intensity以及ICP的几何深度点云匹配。
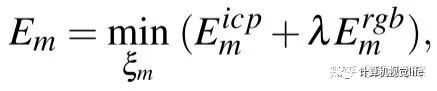
其中各误差项的具体表述为:
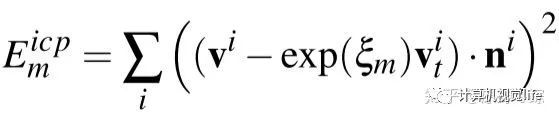
v表示各个节点,如何理解将上一帧的节点转换到当前帧做空间差并投影到法向量位置呢。从目的上理解是不是要让同一个物体的观测距离尽量小?
v应该是surfel模型中的v,对于每一个面尽量重叠,而重叠的方式则是让面间距离最小。因此该公式就比较直观了。
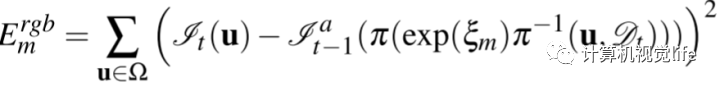
即将上一帧对应位置的强度通过变换投影到当前帧,构造一个基于intensity的BA。(为何当前的BA过程都只考虑intensity呢。颜色都被压缩为一个通道)
CUDA加速的应用基于开源的codes of [ElasticFusion 和 Co-Fusion]
4.2 Fusion
该部分目的是更新surfels。通过与当前帧进行投影的数据关联。该步骤来自[23],但基于分割的模具用于物体边界。因而每个新增加的surfel属于确定的一个模型。同时,对于模具之外的surfels我们引入了一个置信惩罚,对于不完美的分割是必须的。
5 SEGMENTATION
该部分是最重要的部分了。跟踪是一板一眼毫无创新地解决了,即融合已有的ElasticFusion面元,结合surfel的表达和intensity构造优化。重建也可以按照elasticfusion和[23]的框架来做更新surfels。那么本文的重点,分割是如何实现的呢。
数据关联的构建 基于Co-Fusion,不是在3D完成数据关联,而是在2D下进行model-to-segment的关联。给定这些关联后,新的帧被masked,仅仅数据的子集被fused到已有的模型中,
pipeline的设计基于以下观测:.. 复读机了上面内容。
RGBD的分割是基于object convexity假设的。
双线程的工程实现。由于分割平行与tracking和fusion线程,于是需要有同步机制。
设计了一个队列。最终有一个400ms delay。实现30fps。
对于没有语义分割的帧,用mask-less 帧的边界与已有的模型做关联,将在Section 5.3中讨论。
5.1 Semantic Instance segmentation
Mask-rcnn等提供了专注于实例级别的物体分割算法。(非常好奇这类算法如何实现的分割,真实效果如何,以及背后理论的限制和前景如何,当前发展方向如何。——并不深入去工程细节,而是从数学宏观上来理解这些东西,一定要不陷入天坑中去。)
5.2 Geometric Segmentation
基于几何的分割感觉也很有前景。对于人类来说大部分的分割实际是几何完成的。在人类知道该物体是独立的物体之前,并不需要该物体的语义信息。相反,语义信息是建立在分割的基础上的。
[13, 22, 42, 45, 47] 专门研究了 RGBD帧的几何分割问题。基本上在2013-2015年的文章。该部分已经成熟。
即它与语义的结合才是现在比较好的方向,同时结合上动态过程。
分割参考的论文
[45] K. Tateno, F. Tombari, and N. Navab. Real-time and scalable incremental segmentation on dense slam. In
IEEE/RSJ International Conference
on Intelligent Robots and Systems
, 2015
分割过程如下,定义两个参数分别考虑深度的连通和凹的程度,定义一个阈值和它们两的权重:
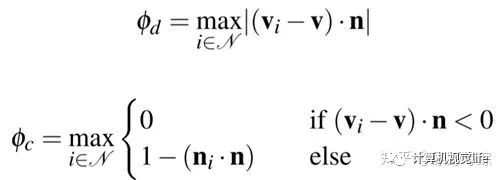
示例分割结果提出的边界:
然后对其去除back-ground得到

5.3 Merged segmentation【该部分整体有点迷】
当没有语义masks的时候,几何标签直接与存在的模型做关联,于是下面讨论的会被跳过。
5.3.1 Mapping geometric labels to masks
即判断二者重叠区域最高的作为关联。在实验里设定 65%的重复度。
多个components可以被mapped到同一个mask,然而一个component只map到一个mask。
5.3.2 Mapping masks to models
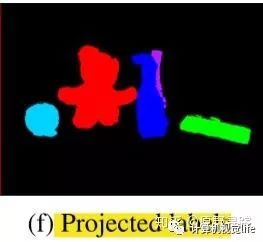
将物体labels投影到相机视野中,如f)图所示。然后将其与几何分割的components之间做5.3.1中同样的重合度比较。上图通过OpenGL渲染所有模型来生成。( 如何渲染? ) 然后选取一个 5%的阈值( 为何这么小) ,验证了物体模型的类别ID和mask是一致的。
对于没有成功匹配上的剩余的components,如5.3.1中直接与labels做overlap.
此处特意设定了一个值255来去除如手臂一样不想考虑的区域。
(这里两者分开考虑,很类似我的ob-map, map-ob的 pole data association, 所以我也应该分别考虑二者。)
6 Evaluation
评估部分。建图和跟踪部分都基于 co-fusion和elasticfusion. 专门挑选了动态环境,使用AT[全局]、RP[忽略drift] RMSE来评估。
首先对比人多的环境。由于MaskFusion无法处理可变形部分,所以我们忽略掉有人的关联。
Co-Fusion的介绍是一种通过运动来分割物体的SLAM系统。
可以仔细看看。
基于rgbd的benchmark,提出文献:
[43] Jurgen Sturm, Nikolas Engelhard, Felix Endres, Wolfram Burgard, ¨
and Daniel Cremers. A benchmark for the evaluation of rgb-d slam
systems. In
Intelligent Robots and Systems (IROS), 2012 IEEE/RSJ
International Conference on
, pages 573–580. IEEE, 2012.
实验数据
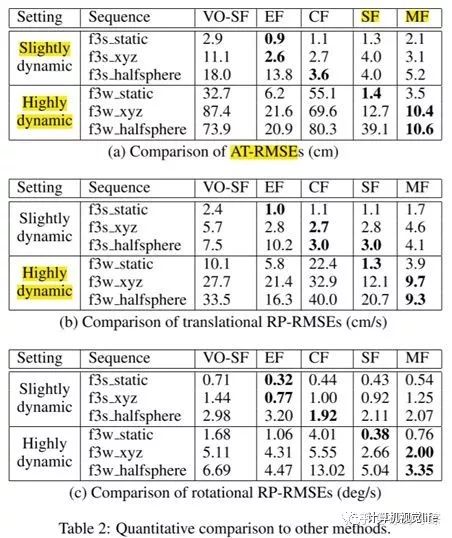
其实挑了三段 TUM数据集,用5个系统跑了一下,同时将其中部分人为拆成 slightly dynamic和highly dynamic。(这里是实验者自己来规定的部分吗?)
6.1.2 Reconstruction
感觉该文献的核心还是重建。
YCB Object and Model Set [4]里面提供了常用物体的数据库,可以用来做重建的评估。(厉害了还有这种东西。或许可以3d打印再重建?)
就找了个瓶子跑了一下试试,也没有跟其他的比。
6.1.3 Segmentation
将重建的3D模型投回来作为groundtruth去与联合方法得到的区域做IoU的比较。
这里出现了一个ours和 geometry+semantic的两个,不知道区别。
6.2 Qualitative results
这里三维重建能够为机械手臂的抓持提供抓持点的分析。
6.3 Performance
2块GPU Titan X+cpu core i7 3.5GHz!1块做实时分割,一块做slam。( 实际测试的时候可以先分割好然后跑数据集.. )
Conclusion
三个限制:recognition, reconstruction and tracking.
-
限制于mask-rcnn识别物体的种类。
-
限制于刚体的跟踪
-
过小的物体提供不了足够的几何信息。
资源
Mask-RCNN : https://github.com/matterport/Mask_RCNN
思考
整个系统某种程度上更专注于三维重建。它对多物体的跟踪,不过是融合了icp和强度的增加误差项的方式。
这里将地图中的物体存放了位置信息,那么跟踪的时候若物体也在动,如何保证优化得到正确的相机和物体位姿?
该系统在结果中在高动态环境下效果比较好,而在低动态环境下反而没有staticFusion效果好,为何会有这种状况出现?
实验部分考虑了多个应用:AR环境的示意、与人手的交互(显示卡路里)、以及动态晃动瓶子状态下对其的重建。而我认为更有用的定位部分评估不是很多,它并不是一个很合格的为移动机器人准备的动态语义slam系统。
关于移动机器人与物体级语义SLAM的应用思路
对于移动机器人来说,分割是很必要的东西,当在环境中发现了某种物体,应该附有基本属性 ( static/not static ),若是 not static的,应该能对其运动进行跟踪和预测。该部分的核心是能够定位自身( 过滤掉动态之后 ), 然后对其进行跟踪。作为机器人并不在乎其重建效果。所以机器人能够在动态环境下在动态物体潜在运动轨迹上添加costfunction完成路径规划。
对于室内环境,先完成分割。语义分割+几何分割的点子是很好的。然后将该信息融合到已有的静态地图中去,辅助机器人完成路径规划。
思考有没有相关最新文章研究。语义级的slam(检测人即可, 包括一些不在类别内的移动物体(球、机器人等) ),同时路径规划,路径规划的同时完成对动态物体的分割和追踪。
即该slam系统的目的,不再仅仅停留于剔除掉动态物体完成定位。而是将动态物体作为地图的一个layer,即动态层。
传统静态层用于定位,而动态层用于估计动态物体相对自身位置,并辅助路径规划。
第一步、完成动态层的构建(即多物体跟踪 – 深入,更多物体的跟踪。(尽量收缩室内的定位要求,如天花板、线面等几何信息)
第二步、基于该系统完成路径规划(根据第一步地图来高帧率预测动态物体的潜在路径,建立路径规划模型)
第三步、彻底意义的主动探索(挑选合适的下一步主动slam位置,并在高动态环境完成主动探索!)
这三步完成之后,一个彻底的室内物流机器人就完成了,它可以在室内动态环境运动到任何地方去。
认为这里准确的物体边界非常重要。应用考虑目前2d图像的检
测无法做到很准确的边界提取,而3d下来做边界提取则变得异常简单。
这也是传感器融合的一个点。slam辅助语义识别。
目前语义slam的点不是那么好找了,想在室内移动机器人上做一做,抛砖引玉吧。
其他资料
论文链接:
MaskFusion
: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects(http://visual.cs.ucl.ac.uk/pubs/maskfusion/)
我之前写的SemanticFusion的解析
原野寻踪:(https://zhuanlan.zhihu.com/p/42713034)[论文]SemanticFusion CNN稠密3D语义建图
推荐阅读
如何从零开始系统化学习视觉SLAM?
从零开始一起学习SLAM | 为什么要学SLAM?
从零开始一起学习SLAM | 学习SLAM到底需要学什么?
从零开始一起学习SLAM | SLAM有什么用?
从零开始一起学习SLAM | C++新特性要不要学?
从零开始一起学习SLAM | 为什么要用齐次坐标?
从零开始一起学习SLAM | 三维空间刚体的旋转
从零开始一起学习SLAM | 为啥需要李群与李代数?
从零开始一起学习SLAM | 相机成像模型
从零开始一起学习SLAM | 不推公式,如何真正理解对极约束?
从零开始一起学习SLAM | 神奇的单应矩阵
从零开始一起学习SLAM | 你好,点云
从零开始一起学习SLAM | 给点云加个滤网
从零开始一起学习SLAM | 点云平滑法线估计
从零开始一起学习SLAM | 点云到网格的进化
从零开始一起学习SLAM | 理解图优化,一步步带你看懂g2o代码
从零开始一起学习SLAM | 掌握g2o顶点编程套路
从零开始一起学习SLAM | 掌握g2o边的代码套路
SLAM初识
SLAM技术框架
惯性导航系统简介
视觉里程计:起源、优势、对比、应用
视觉里程计:特征点法之全面梳理
SLAM领域牛人、牛实验室、牛研究成果梳理
我用MATLAB撸了一个2D LiDAR SLAM
可视化理解四元数,愿你不再掉头发
IMU标定 | 工业界和学术界有什么不同?
汇总 | VIO、激光SLAM相关论文分类集锦
最近一年语义SLAM有哪些代表性工作?
视觉SLAM技术综述
研究SLAM,对编程的要求有多高?
深度学习遇到SLAM | 如何评价基于深度学习的DeepVO,VINet,VidLoc?
2018年SLAM、三维视觉方向求职经验分享
新型相机DVS/Event-based camera的发展及应用
最近三年开源「语义SLAM/分割/建模」方案介绍
超详细干货 | 三维语义分割概述及总结
高翔:
谈谈语义SLAM/地图

觉得有用,给个好看啦~
