具体问题
在爬取某个网站时遇到了一个奇怪的问题,就是只要是python爬取的数据得到的基本就是那么几种数据,无论我输入的是什么,返回的数据与浏览器得到返回的数据都不一样,这让我很郁闷,百度也找不到想要的答案。直到最后才发现是自己对python不够了解,不是网站问题,是自己的问题。
解决方法
在requests库中,requests.post()方法中构造参数data时,data里面非ASCII字符就会进行编码。而构造消息请求头headers时,headers里面的非ASCII字符不会自动的进行编码。也就是如果你爬虫的请求消息头和请求参数都与输入有关并且是非ASCII字符的话你需要用parse.quote()方法进行编码,headers用编码后的输入值,否则执行会报错。data直接使用输入值,否则二次编码会改变你的请求值导致爬取的数据与浏览器中得到的数据不一致。
示例代码
import requests
from urllib import parse
begin_put = input("输入:")
after_put = parse.quote(begin_put)
headers = {
"Host": "aaa.net",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"X-Requested-With": "XMLHttpRequest",
"Connection": "close",
"Referer": "http://aaa.net/?name=" + after_put + "&type=netease"
}
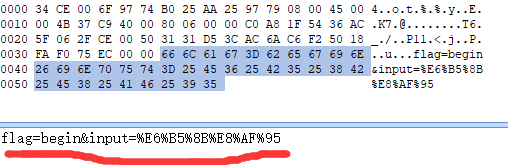
begin_data = {
"flag":"begin",
"input":begin_put
}
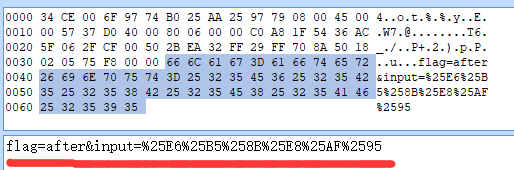
after_data = {
"flag":"after",
"input":after_put
}
r = requests.post("http://httpbin.org/post",data=begin_data,headers=headers)
req = requests.post("http://httpbin.org/post",data=after_data,headers=headers)
利用抓包工具可以看到第二次请求(也就是flag值为after的)里的input值进行了二次编码。%对应的编码是%25
版权声明:本文为XUchenmp原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。