tcmalloc源码分析
说明
从
TCMalloc解密
处转载,方便日后复习
其他摘自参考文章:
TCMalloc源码阅读(二)–线程局部缓存ClassSize分析
tcmalloc源码阅读(三)—ThreadCache分析之线程局部缓存
TCMalloc内存分配器如何减少内存碎片?
tcmalloc内存分配器分析笔记:基于gperftools-2.4
介绍
TCMalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc、free,new,new[]等)
TCMalloc是gperftools的一部分,除TCMalloc外,gperftools还包括heap-checker、heap-profiler和cpu-profiler。本文只讨论gperftools的TCMalloc部分
git仓库
官方介绍
(里面有些内容已经过时了)
1)如何使用TCMalloc
安装
以下是比较常规的安装步骤,详细可参考gperftools中的
INSTALL
从git仓库clone版本的gperftools的安装依赖autoconf、automake、libtool,以Debian为例
# apt install autoconf automake libtool
生成configure等一系列文件
$ ./autogen.sh
生成Makefile
$ ./configure
编译
$ make
安装
# make install
默认安装在/usr/local/下的相关路径(bin、lib、share),可在configure时以–prefix=PATH指定其他路径
64位Linux系统需要注意
在64位Linux环境下,gperftools使用glibc内置的stack-unwinder可能会引发死锁,因此官方推荐在配置和安装gperftools之前,先安装libunwind-0.99-beta,最好就用这个版本,版本太新或太旧都可能会有问题
。
即便使用libunwind,在64位系统上还是会有问题,但只影响heap-checker、heap-profiler和cpu-profiler,TCMalloc不受影响,因此不再赘述,感兴趣的读者可参阅gperftools的INSTALL
。
如果不希望安装libunwind,也可以用gperftools内置的stack unwinder,但需要应用程序、TCMalloc库、系统库(比如libc)在编译时开启帧指针(frame pointer)选项
。
在x86-64下,编译时开启帧指针选项并不是默认行为。因此需要指定-fno-omit-frame-pointer编译所有应用程序,然后在configure时通过–enable-frame-pointers选项使用内置的gperftools stack unwinder
使用
以动态库的方式
以动态库的方式
安装之后,通过-ltcmalloc或-ltcmalloc_minimal将TCMalloc链接到应用程序即可
#include <stdlib.h> int main( int argc, char *argv[] ) { malloc(1); }$ g++ -O0 -g -ltcmalloc test.cc && gdb a.out(gdb) b test.cc:5 Breakpoint 1 at 0x7af: file test.cc, line 5. (gdb) r Starting program: /home/wanglong/test/tcmalloc/a.out [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1". Breakpoint 1, main (argc=1, argv=0x7fffffffddd8) at test.cc:5 5 malloc(1); (gdb) s tc_malloc (size=1) at src/tcmalloc.cc:1892 1892 return malloc_fast_path<tcmalloc::malloc_oom>(size); (gdb)
通过gdb断点可以看到对malloc()的调用已经替换为TCMalloc的实现
以静态库的方式
以静态库的方式
gperftools的README中说静态库应该使用libtcmalloc_and_profiler.a库而不是libprofiler.a和libtcmalloc.a,但简单测试后者也是OK的,而且在实际项目中也是用的后者,不知道是不是文档太过老旧了
$ g++ -O0 -g -pthread test.cc /usr/local/lib/libtcmalloc_and_profiler.a
如果使用了libunwind,需要指定-Wl,–eh-frame-hdr选项,以确保libunwind可以找到编译器生成的信息来进行栈回溯。
eh-frame(exception handling frame)参考资料:
2)TCMalloc是如何生效的
为什么指定-ltcmalloc或者与libtcmalloc_and_profiler.a连接之后,对malloc、free、new、delete等的调用就由默认的libc中的函数调用变为TCMalloc中相应的函数调用了呢?答案在libc_override.h中,下面只讨论常见的两种情况:使用了glibc,或者使用了GCC编译器。其余情况可自行查看相应的libc_override头文件
使用glibc(但没有使用GCC编译器)
在glibc中,内存分配相关的函数都是弱符号
weak symbol
,因此TCMalloc只需要定义自己的函数将其覆盖即可,以malloc和free为例:
libc_override_redefine.h
extern "C" { void* malloc(size_t s) { return tc_malloc(s); } void free(void* p) { tc_free(p); } } // extern "C"
可以看到,TCMalloc将malloc()和free()分别定义为对tc_malloc()和tc_free()的调用,并在tc_malloc()和tc_free()中实现具体的内存分配和回收逻辑。
new和delete也类似
void* operator new(size_t size) { return tc_new(size); } void operator delete(void* p) CPP_NOTHROW { tc_delete(p); }
使用GCC编译器
如果使用了GCC编译器,则使用其支持的函数属性:
alias
。
libc_override_gcc_and_weak.h:
#define ALIAS(tc_fn) __attribute__ ((alias (#tc_fn), used)) extern "C" { void* malloc(size_t size) __THROW ALIAS(tc_malloc); void free(void* ptr) __THROW ALIAS(tc_free); } // extern "C"
将宏展开,
__attribute__ ((alias ("tc_malloc"), used))
表明tc_malloc是malloc的别名
。
具体可参阅GCC相关文档:
alias (“target”)
The alias attribute causes the declaration to be emitted as an alias for another symbol, which must be specified. For instance,
void __f () { /* Do something. */; }
void f ()
attribute
((weak, alias (“__f”)));
defines f to be a weak alias for __f. In C++, the mangled name for the target must be used. It is an error if __f is not defined in the same translation unit.
Not all target machines support this attribute.
used
This attribute, attached to a function, means that code must be emitted for the function even if it appears that the function is not referenced. This is useful, for example, when the function is referenced only in inline assembly.
When applied to a member function of a C++ class template, the attribute also means that the function will be instantiated if the class itself is instantiated.
3)TCMalloc是什么
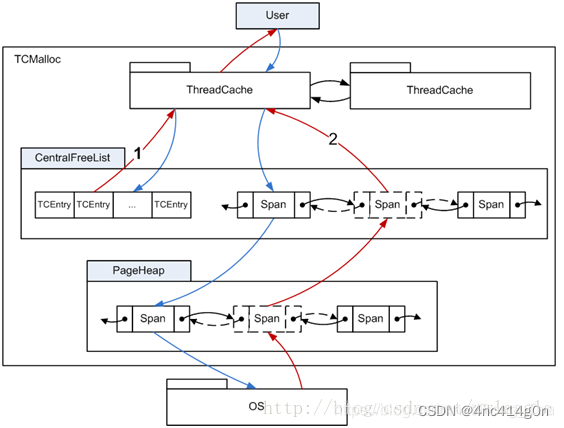
TCMalloc是专门对多线并发的内存管理而设计的,TCMalloc主要是在线程级实现了缓存,使得用户在申请内存时大多情况下是无锁内存分配
整个 TCMalloc对小内存(小于等于256k)的管理实现了三级缓存,分别是
ThreadCache(线程级缓存),
Central Cache(中央缓存:CentralFreeeList),
PageHeap(页缓存)
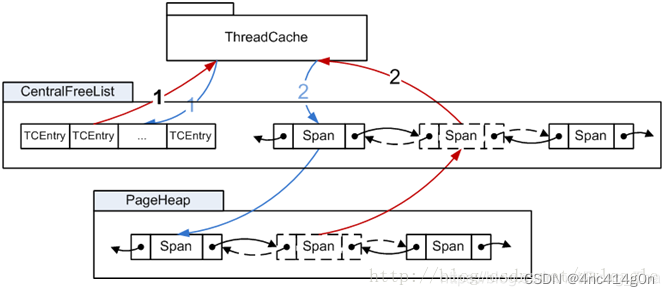
小内存的分配和释放流程如下图所示,红线表示内存的申请,蓝线表示内存的释放过程。
4)TCMalloc的初始化
何时初始化
TCMalloc定义了一个类TCMallocGuard,并在文件tcmalloc.cc中定义了该类型的静态变量module_enter_exit_hook,在其构造函数中执行TCMalloc的初始化逻辑,以确保TCMalloc在main()函数之前完成初始化,防止在初始化之前就有多个线程
。
tcmalloc.cc:
static TCMallocGuard module_enter_exit_hook;
如果需要确保TCMalloc在某些全局构造函数运行之前就初始化完成,则需要在文件顶部创建一个静态TCMallocGuard实例
。
如何初始化
TCMallocGuard的构造函数实现
static int tcmallocguard_refcount = 0; // no lock needed: runs before main() TCMallocGuard::TCMallocGuard() { if (tcmallocguard_refcount++ == 0) { ReplaceSystemAlloc(); // defined in libc_override_*.h tc_free(tc_malloc(1)); ThreadCache::InitTSD(); tc_free(tc_malloc(1)); // Either we, or debugallocation.cc, or valgrind will control memory // management. We register our extension if we're the winner. #ifdef TCMALLOC_USING_DEBUGALLOCATION // Let debugallocation register its extension. #else if (RunningOnValgrind()) { // Let Valgrind uses its own malloc (so don't register our extension). } else { MallocExtension::Register(new TCMallocImplementation); } #endif } }
可以看到,TCMalloc初始化的方式是调用tc_malloc()申请一字节内存并随后调用tc_free()将其释放。至于为什么在InitTSD前后各申请释放一次,不太清楚,猜测是为了测试在TSD(Thread Specific Data,详见后文)初始化之前也能正常工作
初始化内容
那么TCMalloc在初始化时都执行了哪些操作呢?这里先简单列一下,后续讨论TCMalloc的实现细节时再逐一详细讨论:
初始化SizeMap(Size Class)
初始化各种Allocator
初始化CentralCache
创建PageHeap
总之一句话,创建TCMalloc自身的一些元数据,比如划分小对象的大小等等
5)TCMalloc的内存分配算法概览
TCMalloc的官方介绍中将内存分配称为Object Allocation,本文也沿用这种叫法,并将object翻译为对象,可以将其理解为具有一定大小的内存
按照所分配内存的大小,TCMalloc将内存分配分为三类:
小对象分配,(0, 256KB]
中对象分配,(256KB, 1MB]
大对象分配,(1MB, +∞)
简要介绍几个概念,Page,Span,PageHeap:
与操作系统管理内存的方式类似,TCMalloc将整个虚拟内存空间划分为n个同等大小的Page,每个page默认8KB。又将连续的n个page称为一个Span
。
TCMalloc定义了PageHeap类来处理向OS申请内存相关的操作,并提供了一层缓存。可以认为,PageHeap就是整个可供应用程序动态分配的内存的抽象
。
PageHeap以span为单位向系统申请内存,申请到的span可能只有一个page,也可能包含n个page。可能会被划分为一系列的小对象,供小对象分配使用,也可能当做一整块当做中对象或大对象分配
小对象分配
Size Class
对于256KB以内的小对象分配,TCMalloc按大小划分了85个类别(官方介绍中说是88个左右,但我个人实际测试是85个,不包括0字节大小),称为Size Class,每个size class都对应一个大小,比如8字节,16字节,32字节。应用程序申请内存时,TCMalloc会首先将所申请的内存大小向上取整到size class的大小,比如1~ 8字节之间的内存申请都会分配8字节,9~16字节之间都会分配16字节,以此类推。因此这里会产生内部碎片。TCMalloc将这里的内部碎片控制在12.5%以内,具体的做法在讨论size class的实现细节时再详细分析
。
ThreadCache
对于每个线程
TCMalloc都为其保存了一份单独的缓存,称之为ThreadCache,这也是TCMalloc名字的由来(Thread-Caching Malloc)。每个ThreadCache中对于每个size class都有一个单独的FreeList,缓存了n个还未被应用程序使用的空闲对象
。
小对象的分配直接从ThreadCache的FreeList中返回一个空闲对象,相应的,小对象的回收也是将其重新放回ThreadCache中对应的FreeList中
。
由于每线程一个ThreadCache,因此从ThreadCache中取用或回收内存是不需要加锁的,速度很快
。
为了方便统计数据,各线程的ThreadCache连接成一个双向链表。ThreadCache的结构示大致如下
:

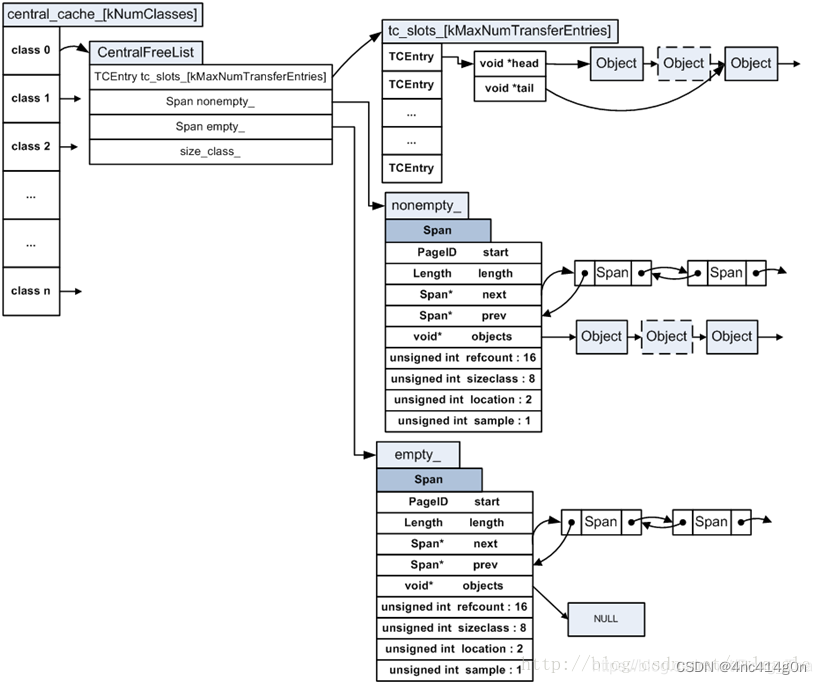
CentralCache
那么ThreadCache中的空闲对象从何而来呢?答案是CentralCache——一个所有线程公用的缓存
。
与ThreadCache类似,CentralCache中对于每个size class也都有一个单独的链表来缓存空闲对象,称之为CentralFreeList,供各线程的ThreadCache从中取用空闲对象
。
由于是所有线程公用的,因此从CentralCache中取用或回收对象,是需要加锁的。为了平摊锁操作的开销,ThreadCache一般从CentralCache中一次性取用或回收多个空闲对象
。
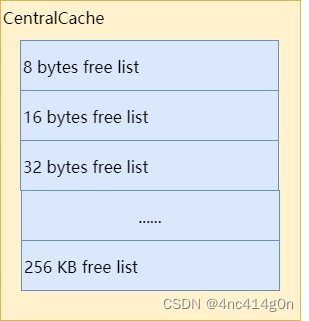
CentralCache在TCMalloc中并不是一个类,只是一个逻辑上的概念,其本质是CentralFreeList类型的数组。后文会详细讨论CentralCache的内部结构,现在暂且认为CentralCache的简化结构如下
:
PageHeap
CentralCache中的空闲对象又是从何而来呢?答案是之前提到的PageHeap——TCMalloc对可动态分配的内存的抽象
。
当CentralCache中的空闲对象不够用时,CentralCache会向PageHeap申请一块内存(可能来自PageHeap的缓存,也可能向系统申请新的内存),并将其拆分成一系列空闲对象,添加到对应size class的CentralFreeList中
。
PageHeap内部根据内存块(span)的大小采取了两种不同的缓存策略。128个page以内的span,每个大小都用一个链表来缓存,超过128个page的span,存储于一个有序set(std::set)。讨论TCMalloc的实现细节时再具体分析,现在可以认为PageHeap的简化结构如下
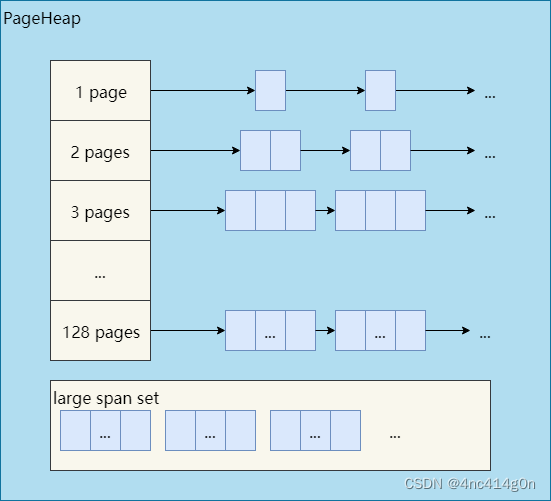
内存回收
上面说的都是内存分配,内存回收的情况是怎样的?
应用程序调用free()或delete一个小对象时,仅仅是将其插入到ThreadCache中其size class对应的FreeList中而已,不需要加锁,因此速度也是非常快的
。
只有当满足一定的条件时,ThreadCache中的空闲对象才会重新放回CentralCache中,以供其他线程取用。同样的,当满足一定条件时,CentralCache中的空闲对象也会还给PageHeap,PageHeap再还给系统
。
内存在这些组件之间的移动会在后文详细讨论,现在先忽略这些细节
。
小结
总结一下,小对象分配流程大致如下:
将要分配的内存大小映射到对应的size class。
查看ThreadCache中该size class对应的FreeList。
如果FreeList非空,则移除FreeList的第一个空闲对象并将其返回,分配结束。
如果FreeList是空的:
从CentralCache中size class对应的CentralFreeList获取一堆空闲对象。
如果CentralFreeList也是空的,则:
向PageHeap申请一个span
。
拆分成size class对应大小的空闲对象,放入CentralFreeList中。
将这堆对象放置到ThreadCache中size class对应的FreeList中(第一个对象除外)
。
返回从CentralCache获取的第一个对象,分配结束
中对象分配
超过256KB但不超过1MB(128个page)的内存分配被认为是中对象分配,采取了与小对象不同的分配策略
。
首先,TCMalloc会将应用程序所要申请的内存大小向上取整到整数个page(因此,这里会产生1B~8KB的内部碎片)。之后的操作表面上非常简单,向PageHeap申请一个指定page数量的span并返回其起始地址即可
:Span* span = Static::pageheap()->New(num_pages); result = (PREDICT_FALSE(span == NULL) ? NULL : SpanToMallocResult(span)); return result;
问题在于,PageHeap是如何管理这些span的?即PageHeap::New()是如何实现的
。
前文说到,PageHeap提供了一层缓存,因此PageHeap::New()并非每次都向系统申请内存,也可能直接从缓存中分配
。
对128个page以内的span和超过128个page的span,PageHeap采取的缓存策略不一样。为了描述方便,以下将128个page以内的span称为小span,大于128个page的span称为大span
。
先来看小span是如何管理的,大span的管理放在大对象分配一节介绍
。
PageHeap中有128个小span的链表,分别对应1~128个page的span
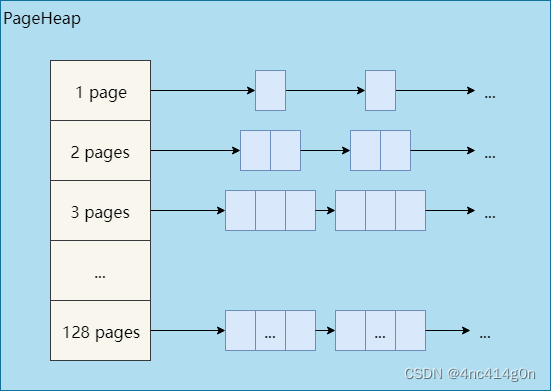
假设要分配一块内存,其大小经过向上取整之后对应k个page,因此需要从PageHeap取一个大小为k个page的span,过程如下:
从k个page的span链表开始,到128个page的span链表,按顺序找到第一个非空链表
。
取出这个非空链表中的一个span,假设有n个page,将这个span拆分成两个span:
一个span大小为k个page,作为分配结果返回
。
另一个span大小为n – k个page,重新插入到n – k个page的span链表中。
如果找不到非空链表,则将这次分配看做是大对象分配,分配过程详见下文。
大对象分配
超过1MB(128个page)的内存分配被认为是大对象分配,与中对象分配类似,也是先将所要分配的内存大小向上取整到整数个page,假设是k个page,然后向PageHeap申请一个k个page大小的span
。
对于中对象的分配,如果上述的span链表无法满足,也会被当做是大对象来处理。也就是说,TCMalloc在源码层面其实并没有区分中对象和大对象,只是对于不同大小的span的缓存方式不一样罢了。
大对象分配用到的span都是超过128个page的span,其缓存方式不是链表,而是一个按span大小排序的有序set(std::set),以便按大小进行搜索
。
假设要分配一块超过1MB的内存,其大小经过向上取整之后对应k个page(k>128),或者是要分配一块1MB以内的内存,但无法由中对象分配逻辑来满足,此时k <= 128。不管哪种情况,都是要从PageHeap的span set中取一个大小为k个page的span,其过程如下:
搜索set,找到不小于k个page的最小的span(best-fit),假设该span有n个page。
将这个span拆分为两个span
:
一个span大小为k个page,作为结果返回。
另一个span大小为n – k个page,如果n – k > 128,则将其插入到大span的set中,否则,将其插入到对应的小span链表中
。
如果找不到合适的span,则使用sbrk或mmap向系统申请新的内存以生成新的span,并重新执行中对象或大对象的分配算法
小结
以上讨论忽略了很多实现上的细节,比如PageHeap对span的管理还区分了normal状态的span和returned状态的span,接下来会详细分析这些细节
。
在此之前,画张图概括下TCMalloc的管理内存的策略
:
可以看到,不超过256KB的小对象分配,在应用程序和内存之间其实有三层缓存:PageHeap、CentralCache、ThreadCache。而中对象和大对象分配,则只有PageHeap一层缓存
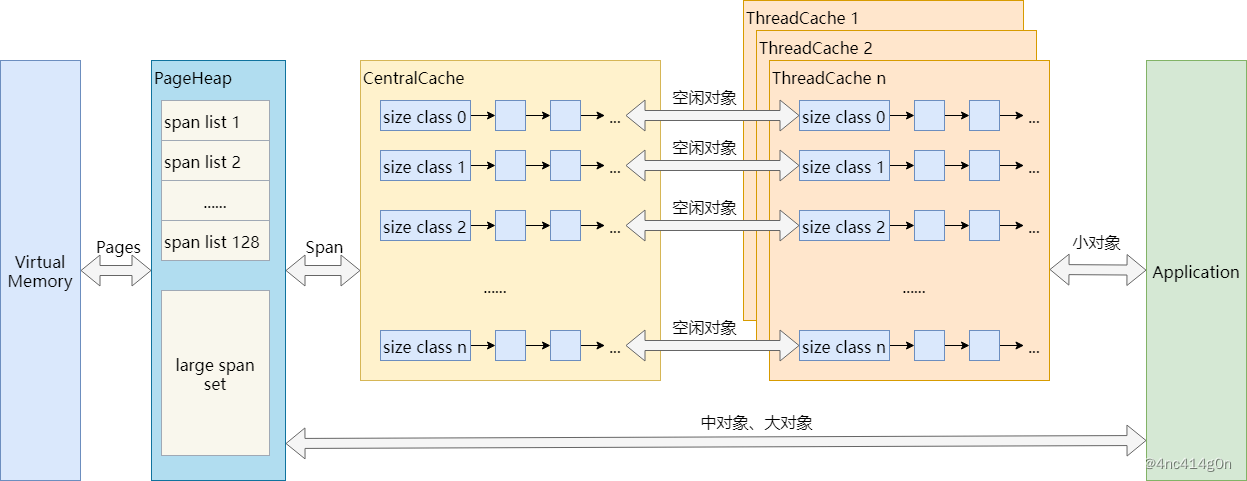
6)TCMalloc的实现细节
算法概览一节涉及到了很多概念,比如Page,Span,Size Class,PageHeap,ThreadCache等,但只是粗略的一提,本节将详细讨论这些概念所涉及的实现细节
① Page
Page是TCMalloc管理内存的基本单位(这里的page要区分于操作系统管理虚拟内存的page),page的默认大小为8KB,可在configure时通过选项调整为32KB或64KB。
./configure <other flags> --with-tcmalloc-pagesize=32 (or 64)
page越大,TCMalloc的速度相对越快,但其占用的内存也会越高。简单说,就是空间换时间的道理。默认的page大小通过减少内存碎片来最小化内存使用,但跟踪这些page会花费更多的时间。使用更大的page则会带来更多的内存碎片,但速度上会有所提升。官方文档给出的数据是在某些google应用上有3%~5%的速度提升
。
② PageID
TCMalloc并非只将堆内存看做是一个个的page,而是将整个虚拟内存空间都看做是page的集合。从内存地址0x0开始,每个page对应一个递增的PageID,如下图(以32位系统为例)
:
对于任意内存地址ptr,都可通过简单的移位操作来计算其所在page的PageID:
static const size_t kPageShift = 13; // page大小:1 << 13 = 8KB const PageID p = reinterpret_cast<uintptr_t>(ptr) >> kPageShift;
即,ptr所属page的PageID为ptr / page_size。

③ Span
一个或多个连续的Page组成一个Span(a contiguous run of pages)。TCMalloc以Span为单位向系统申请内存
。
如图,第一个span包含2个page,第二个和第四个span包含3个page,第三个span包含5个page
。
一个span记录了起始page的PageID(start),以及所包含page的数量(length)
。
一个span要么被拆分成多个相同size class的小对象用于小对象分配,要么作为一个整体用于中对象或大对象分配。当作用作小对象分配时,span的sizeclass成员变量记录了其对应的size class。
span中还包含两个Span类型的指针(prev, next),用于将多个span以链表的形式存储。

span的三种状态
一个span处于以下三种状态中的一种:
IN_USE
ON_NORMAL_FREELIST
ON_RETURNED_FREELIST
I
N_USE比较好理解,正在使用中的意思,要么被拆分成小对象分配给CentralCache或者ThreadCache了,要么已经分配给应用程序了。因为span是由PageHeap来管理的,因此即使只是分配给了CentralCache,还没有被应用程序所申请,在PageHeap看来,也是IN_USE了
。
ON_NORMAL_FREELIST和ON_RETURNED_FREELIST都可以认为是空闲状态,区别在于,ON_RETURNED_FREELIST是指span对应的内存已经被PageHeap释放给系统了(在Linux中,对于MAP_PRIVATE|MAP_ANONYMOUS的内存使用madvise来实现)。需要注意的是,即使归还给系统,其虚拟内存地址依然是可访问的,只是对这些内存的修改丢失了而已,在下一次访问时会导致page fault以用0来重新初始化
空闲对象链表
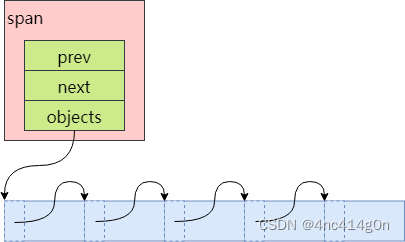
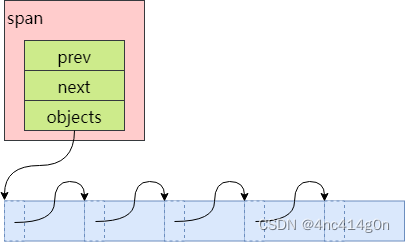
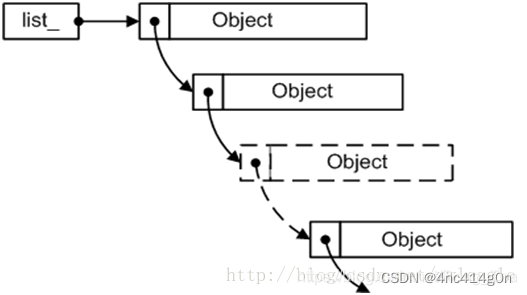
被拆分成多个小对象的span还包含了一个记录空闲对象的链表objects,由CentralFreeList来维护。
对于新创建的span,将其对应的内存按size class的大小均分成若干小对象,在每一个小对象的起始位置处存储下一个小对象的地址,首首相连
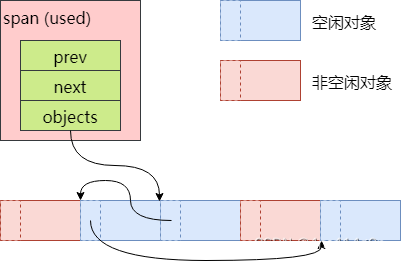
但当span中的小对象经过一系列申请和回收之后,其顺序就不确定了:
可以看到,有些小对象已经不再空闲对象链表objects中了,链表中的元素顺序也已经被打乱
。
空闲对象链表中的元素乱序没什么影响,因为只有当一个span的所有小对象都被释放之后,CentralFreeList才会将其还给PageHeap
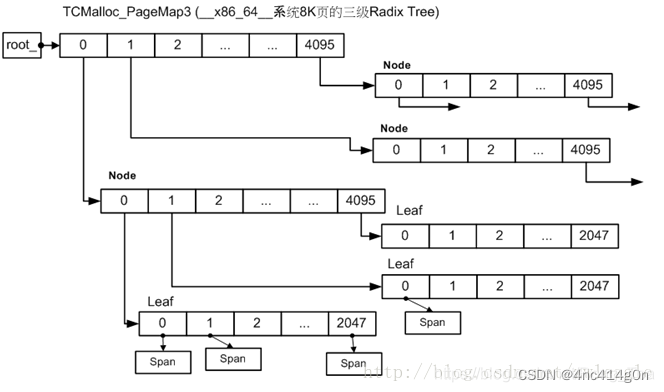
④ PageMap
PageMap之前没有提到过,它主要用于解决这么一个问题:给定一个page,如何确定这个page属于哪个span?
即,PageMap缓存了PageID到Span的对应关系。
32位系统、x86-64、arm64使用两级PageMap,以32位系统为例
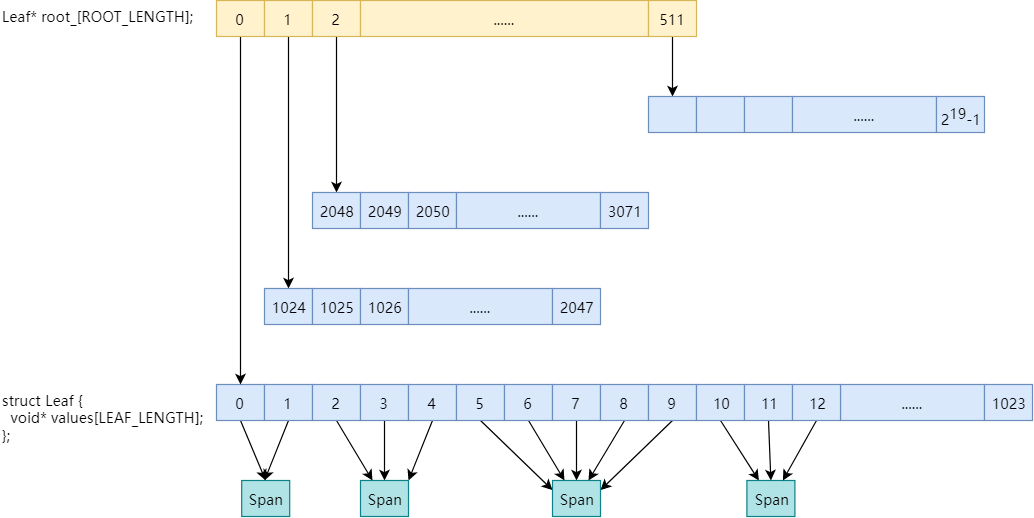
在root_数组中包含512个指向Leaf的指针,每个Leaf又是1024个void*的数组,数组索引为PageID,数组元素为page所属Span的指针。一共2
19
个数组元素,对应32位系统的2
19
个page。
使用两级map可以减少TCMalloc元数据的内存占用,因为初始只会给第一层(即root_数组)分配内存(2KB),第二层只有在实际用到时才会实际分配内存。而如果初始就给2
19
个page都分配内存的话,则会占用2
19
* 4 bytes = 2MB的内存
底层使用的基数树:
详细参考:
复用tcmalloc源码中的基数树进行优化
⑤ Size Class
TCMalloc将每个小对象的大小(1B~256KB)分为85个类别(官方介绍中说是88个左右,但我个人实际测试是85个,不包括0字节大小),称之为Size Class,每个size class一个编号,从0开始递增(实际编号为0的size class是对应0字节,是没有实际意义的)
。
举个例子,896字节对应编号为30的size class,下一个size class 31大小为1024字节,那么897字节到1024字节之间所有的分配都会向上舍入到1024字节
。
SizeMap::Init()实现了对size class的划分,规则如下
划分跨度
TCMalloc为了提高内存分配效率和减少内存的浪费,对小内存进行了细化分类,在默认的情况下:
16字节以内,每8字节划分一个size class。
满足这种情况的size class只有两个:8字节、16字节
。
16~128字节,每16字节划分一个size class
。
满足这种情况的size class有7个:32, 48, 64, 80, 96,
112, 128字节。 128B~256KB,按照每次步进(size / 8)字节((2
(n+1)-2
n)/8)的长度划分(n的值为log2(size)取整),并且步长需要向下对齐到2的整数次幂(见函数
AlignmentForSize()
),比如:
144字节:128 + 128 / 8 = 128 + 16 = 144
160字节:144 + 144 / 8 = 144 + 18 = 144 + 16 = 160
176字节:160 + 160 / 8 = 160 + 20 = 160 + 16 = 176 以此类推
一次移动多个空闲对象
ThreadCache会从CentralCache中获取空闲对象,也会将超出限制的空闲对象放回CentralCache。ThreadCache和CentralCache之间的对象移动是批量进行的,即一次移动多个空闲对象。CentralCache由于是所有线程公用,因此对其进行操作时需要加锁,一次移动多个对象可以均摊锁操作的开销,提升效率
。
那么一次批量移动多少呢?每次移动64KB大小的内存,即因size class而异,但至少2个,至多32个(可通过环境变量TCMALLOC_TRANSFER_NUM_OBJ调整)
。
移动数量的计算也是在size class初始化的过程中计算得出的
。
一次申请多个page
对于每个size class,TCMalloc向系统申请内存时一次性申请n个page(一个span),然后均分成多个小对象进行缓存,以此来均摊系统调用的开销
。
不同的size class对应的page数量是不同的,如何决定n的大小呢?从1个page开始递增,一直到均分成若干小对象后所剩的空间小于span总大小的1/8为止,因此,浪费的内存被控制在12.5%以内。这是TCMalloc减少内部碎片的一种措施
。
另外,所分配的page数量还需满足一次移动多个空闲对象的数量要求(源码中的注释是这样说的,不过实际代码是满足1/4即可,原因不明)
合并操作
在上述规则之上,还有一个合并操作:TCMalloc会将相同page数量,相同对象数量的相邻的size class合并为一个size class。比如
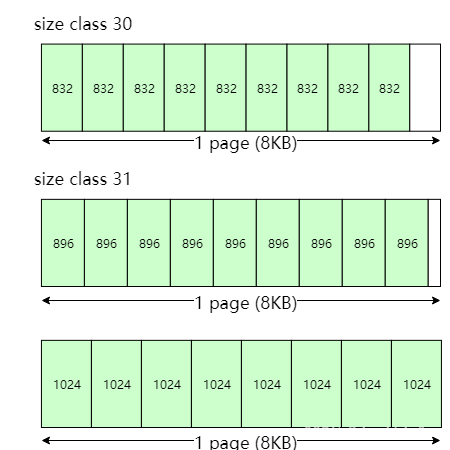
第30个size class的对象大小是832字节,page数量为1个,因此包含8192 / 832 = 9个小对象
。
第31个size class对应的page数量(1个)和对象数量(9个)跟第30个size class完全一样,因此第30个size class和第31个size class合并,所以第30个size class对应的对象大小为896字节
。
下一个size class对应的对象大小为1024字节,page数量为1个,因此对象数量是8个,跟第30个size class的对象数量不一样,无法合并
。
最终,第30个size class对应的对象大小为896字节
记录映射关系
由以上划分规则可以看到,一个size class对应:
一个对象大小
一个申请page的数量
一个批量移动对象的数量
TCMalloc将size class与这些信息的映射关系分别记录在三个以size class的编号为索引的数组中(
class_to_size_ , num_objects_to_move_, class_to_pages_)
还有一项非常重要的映射关系:小对象大小到size class编号的映射。TCMalloc将其记录在一个一维数组
class_array_
中
。
256KB以内都是小对象,而size class的编号用一个字节就可以表示,因此存储小对象大小对应的size class编号需要256K个unsigned char,即256KB的内存。但由于size class之间是有间隔的(1024字节以内间隔至少8字节,1024以上间隔至少128字节),因此可以通过简单的计算对class_array_的索引进行压缩,以减少内存占用
。
给定大小s,其对应的class_array_索引计算方式如下:(位运算)
// s <= 1024 static inline size_t SmallSizeClass(size_t s) { return (static_cast<uint32_t>(s) + 7) >> 3; } // s > 1024 static inline size_t LargeSizeClass(size_t s) { return (static_cast<uint32_t>(s) + 127 + (120 << 7)) >> 7; }
当s = 256KB时,计算结果即为class_array_的最大索引2169,因此数组的大小为2170字节
计算任意内存地址对应的对象大小
当应用程序调用free()或delete释放内存时,需要有一种方式获取所要释放的内存地址对应的内存大小。结合前文所述的各种映射关系,在TCMalloc中按照以下顺序计算任意内存地址对应的对象大小
:
计算给定地址计所在的PageID(ptr >> 13)
从PageMap中查询该page所在的span
span中记录了size class编号
据size class编号从class_to_size_数组中查询对应的对象大小
这样做的好处是:不需要在内存块的头部记录内存大小,减少内存的浪费。
小结
size class的实现中有很多省空间省时间的做法:
省空间
控制划分跨度的最大值(8KB),减少内部碎片
控制一次申请page的数量,减少内部碎片
通过计算和一系列元数据记录内存地址到内存大小的映射关系,避免在实际分配的内存块中记录内存大小,减少内存浪费
两级PageMap或三级PageMap
压缩class_array_
省时间
一次申请多个page
一次移动多个空闲对象
线程局部缓存ClassSize分析(摘自其他文章)
问题
小对象是如何划分的?
对于任意一个小于kMaxSize的size是如何映射到某一种缓存对象上?
SizeMap分析
TCMalloc对这些细化分类构建了两个映射表,即
class_array_[kClassArraySize]:表示了size到class的映射关系(size需要先经过函数ClassIndex(size) 转换 )
class_to_size_[kNumClasses]:表示了class到size的映射关系。
要申请一个size的内存时,先从class_array_[ClassIndex(size)]查到size对应的sizeclass,然后从映射class_to_size_[kNumClasses]获取实际获取的内存大小
。
同时TCMalloc另外维护了两种映射表:
class_to_pages_[kNumClasses]:class_to_pages_[kNumClasses]表示了Central Cache每次从PageHeap获取内存时,对应的sizeclass每次需要从PageHeap获取几页内存
num_objects_to_move_[kNumClasses:num_objects_to_move_[kNumClasses]表示了ThreadCache每次从Central Cache获取内存时,对应的sizeclass每次需要从Central Cache获取的buffer(Object)个数
。
在do_malloc函数中有如下两行代码:
size_t cl = Static::sizemap()->SizeClass(size); size = Static::sizemap()->class_to_size(cl);
不难理解,这两行代码就是size映射到它最接近的缓存对象上。接下来继续探究SizeClass(size_t)和class_to_(size_t)两个函数,这两个函数在
common.h
文件中,代码如下:
class SizeMap { private: ... //其他暂时不关心的 //------------------------------------------------------------------- // Mapping from size to size_class and vice versa //------------------------------------------------------------------- // Sizes <= 1024 have an alignment >= 8. So for such sizes we have an // array indexed by ceil(size/8). Sizes > 1024 have an alignment >= 128. // So for these larger sizes we have an array indexed by ceil(size/128). // // We flatten both logical arrays into one physical array and use // arithmetic to compute an appropriate index. The constants used by // ClassIndex() were selected to make the flattening work. // // Examples: // Size Expression Index // ------------------------------------------------------- // 0 (0 + 7) / 8 0 // 1 (1 + 7) / 8 1 // ... // 1024 (1024 + 7) / 8 128 // 1025 (1025 + 127 + (120<<7)) / 128 129 // ... // 32768 (32768 + 127 + (120<<7)) / 128 376 static const int kMaxSmallSize = 1024; static const size_t kClassArraySize = ((kMaxSize + 127 + (120 << 7)) >> 7) + 1; unsigned char class_array_[kClassArraySize]; // Compute index of the class_array[] entry for a given size static inline int ClassIndex(int s) { ASSERT(0 <= s); ASSERT(s <= kMaxSize); const bool big = (s > kMaxSmallSize); const int add_amount = big ? (127 + (120<<7)) : 7; const int shift_amount = big ? 7 : 3; return (s + add_amount) >> shift_amount; } // Mapping from size class to max size storable in that class size_t class_to_size_[kNumClasses]; public: inline int SizeClass(int size) { return class_array_[ClassIndex(size)]; } ...//暂时不关心的 // Mapping from size class to max size storable in that class inline size_t class_to_size(size_t cl) { return class_to_size_[cl]; } }
原来SizeClass只是返回class_array_数组中的某个元素,这元素的索引由ClassIndex函数计算。ClassIndex的计算逻辑也很简单:
size<=1024的按8字节对齐,这样对于[0,1,2,…,1024]就映射成了[0,1,…,128],
size>1024的按128字节对齐。对于[1025,1026,…,kMaxSize]就会映射成[9,10,…,2048].
我们需要将这两数组按照原来size的顺序合并成一个数组。1024映射成了128,按理,1025应该映射成129. 为达到该目的,我们将后面的一个数组全部加上120,这样两个数组就可以合并成[0,1,…,128,129,…,2168]。
如此就不难理解
当size<=1024时size=(size+7)/8,位运算表达式为:(size+7)>>3.
当size>1024时,size=(size+127+120*128)/128, 位运算表达式为:(size+127+(120<<7))>>7
ClassIndex(size_t)算是搞清楚了,但是从代码中可以看出ClassIndex计算出来的只是class_array_的索引值。class_array_里存储的是class_to_size_的索引,class_to_size_的大小为kNumClass,kNumClass的定义如下:
#if defined(TCMALLOC_LARGE_PAGES) static const size_t kPageShift = 15; static const size_t kNumClasses = 78; #else static const size_t kPageShift = 13; static const size_t kNumClasses = 86; #endif
class_arrar_和class_to_size_的初始化代码如下:
// Initialize the mapping arrays void SizeMap::Init() { // Do some sanity checking on add_amount[]/shift_amount[]/class_array[] ... // Compute the size classes we want to use int sc = 1; // Next size class to assign int alignment = kAlignment; CHECK_CONDITION(kAlignment <= 16); for (size_t size = kAlignment; size <= kMaxSize; size += alignment) { alignment = AlignmentForSize(size); ... if (sc > 1 && my_pages == class_to_pages_[sc-1]) { // See if we can merge this into the previous class without // increasing the fragmentation of the previous class. const size_t my_objects = (my_pages << kPageShift) / size; const size_t prev_objects = (class_to_pages_[sc-1] << kPageShift) / class_to_size_[sc-1]; if (my_objects == prev_objects) { // Adjust last class to include this size class_to_size_[sc-1] = size; continue; } } // Add new class class_to_pages_[sc] = my_pages; class_to_size_[sc] = size; sc++; } ... // Initialize the mapping arrays int next_size = 0; for (int c = 1; c < kNumClasses; c++) { const int max_size_in_class = class_to_size_[c]; for (int s = next_size; s <= max_size_in_class; s += kAlignment) { class_array_[ClassIndex(s)] = c; } next_size = max_size_in_class + kAlignment; } // Double-check sizes just to be safe ... // Initialize the num_objects_to_move array. ... }
代码中还包含了其他的成员初始化,这些目前都不是我们关心的,为更清楚了解class_array_和class_to_size_是如何初始化的,我们删除不必要的代码
。
class_to_size_保存了每一类对齐内存对象的大小,各类大小的关系大致为:
class_to_size_[n]=class_to_size_[n-1]+AlignmentForSize(class_to_size_[n-1])
。
代码中还有一些对齐类的大小是需要调整的,这里先不考虑
AlignmentForSize函数的代码实现如下:
static inline int LgFloor(size_t n) { int log = 0; for (int i = 4; i >= 0; --i) { int shift = (1 << i); size_t x = n >> shift; if (x != 0) { n = x; log += shift; } } ASSERT(n == 1); return log; } int AlignmentForSize(size_t size) { int alignment = kAlignment; if (size > kMaxSize) { // Cap alignment at kPageSize for large sizes. alignment = kPageSize; } else if (size >= 128) { // Space wasted due to alignment is at most 1/8, i.e., 12.5%. alignment = (1 << LgFloor(size)) / 8; } else if (size >= 16) { // We need an alignment of at least 16 bytes to satisfy // requirements for some SSE types. alignment = 16; } // Maximum alignment allowed is page size alignment. if (alignment > kPageSize) { alignment = kPageSize; } CHECK_CONDITION(size < 16 || alignment >= 16); CHECK_CONDITION((alignment & (alignment - 1)) == 0); return alignment; }
先说下LgFloor函数,该函数的功能是返回size值的最高位1的位置。
例如,LgFloor(8)=3, LgFloor(9)=3, LgFloor(10)=3,…,LgFloor(16)=4,…
通过AlignmentForSize函数,我们不难得知class_to_size_的分类规则大致如下:
size在[16,128]之间按16字节对齐,
size在[129,256
1024]之间按(2
(n+1)-2
n)/8对齐,n为7~18,即[129,130,…,256
1024]会被映射为[128+16,128+2
16,…,128+8
16,256+32,256+2
32,…,256+8
32],
超过256*1024以上的按页对齐。
因为ClassIndex计算出来的结果还是太密集了,因此需要通过class_array_来索引到其真正映射到的对齐类
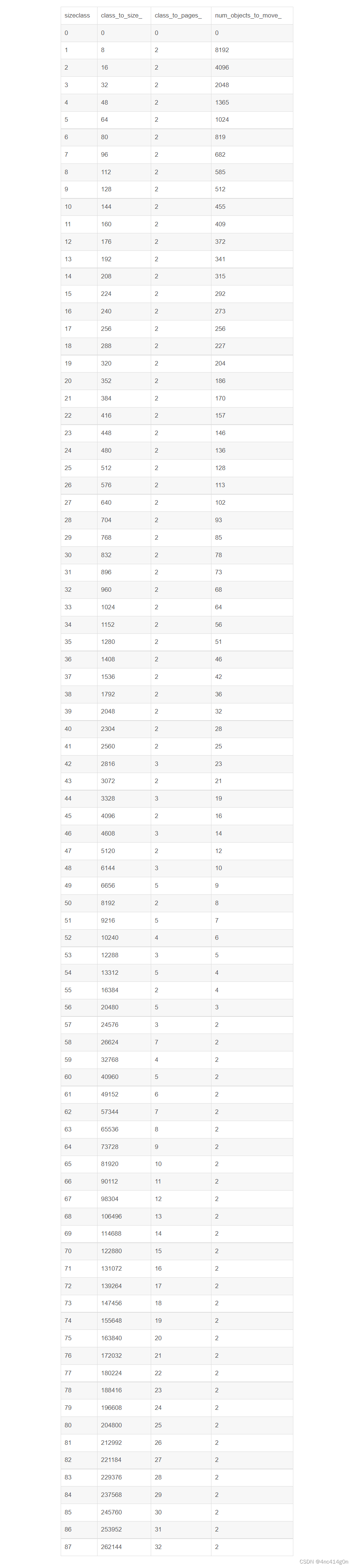
下面整个表表示了以8k为一页时,上述映射表的内容(由于class_array_[kClassArraySize]比较大,这里就不罗列了)。
TCMalloc的内存碎片 (摘自其他文章)
内碎片
TCMalloc采用了
Segregated-Freelist
的算法,提前分配好多种 size-class 保证了内部碎片基本在
12.5%
以下,在64位系统中,通常就是 88 种,那么问题来了,这个怎么计算?
首先看一下结果:8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176…
TCMalloc 的目标是最多 12.5% 的内存碎片,按照上面的 size-class算一下,例如 [112, 128),碎片率最大是 (128-112-1)/128 = 11.7%,(1152-1024-1)/1151 = 11.02%。当然结果是满足 12.5% 这一目标的
。
要生成一批满足碎片率的 size-class 其实也有多种方法,比如,[x, y)区间内,只要满足 (y-x-1)/y <= 0.125即可,即 y <= 8/7*(x+1),从前往后递推一下就可以得到这些结果了,另外再考虑一下字节对齐什么的,就可以得到不错的结果
。
不过 TCMalloc 从另一个角度来考虑这个问题的:从 size 到 size-class,需要进行一次向上对齐(round-up),例如 17 对齐到32;其实也是进行了一次字节对齐(Alignment),把 17 以 16 字节进行对齐,(17 + 15) / 16 * 16 = 32
。
那么,内存碎片率其实就是 (Alignment-1) / SizeClass。那么我们只需要保证每个SizeClass它的 Alignment 满足 (Alignment-1)/SizeClass <= 0.125 就能满足需求了
例如,对于 size-class 1024,下一个size-class 就是 1024 + 1024 / 8 = 1152,其中 Alignment 是1024/8=128;那么1152,我们是按照 1152/8=144,还是按照128计算 Alignment 呢,我们选一个比较好看的数字 128 计算出下一个 size-class。好吧,为什么是128呢,因为是把 1152 向下对齐到了2的幂级数1024,(这里的原因我就不是那么清楚了)。得到的代码如下:
func InitSizeClass() []int { alignment := 8 classToSize := make([]int, 0, 88) for size := alignment; size <= 256*1024; size += alignment { alignment = align(size) classToSize = append(classToSize, size) } return classToSize }
代码非常简单,不过省略了 align 这个函数的实现:
func align(size int) int { aligment := 8 if size > 256*1024 { aligment = PageSize } else if size >= 128 { aligment = (1 << uint32(lgfloor(size))) / 8 } else if size >= 16 { aligment = 16 } if aligment > PageSize { aligment = PageSize } return aligment }
计算 Alignment 的时候,大于 256 × 1024就按照Page进行对齐;最小对齐是8;在128到256×1024之间的,按照 1<<lgfloor(size) / 8进行对齐。等等,说好的向下取整到 2的幂级数然后除以8呢?
其实 lgfloor 就是用二分查找,向下对齐到2的幂级数的:
func lgfloor(size int) int { n := 0 for i := 4; i >= 0; i-- { shift := uint32(1 << uint32(i)) if (size >> shift) != 0 { size >>= shift n += int(shift) } } return n }
先看左边16位,有数字的话就搜左边,否则搜右边。。。
到这里,基本上完成了 size-class的计算(TCMalloc 还有一个优化)。
外碎片
外部碎片是因为 CentralCache 在向 PageHeap 申请内存的时候,以 Page 为单位进行申请。
举个例子,对于 size-class 1024,以一个Page(8192)申请,完全没有外部碎片;
但是对于 size-class 1152,就有 8192 % 1152 = 128 的碎片。
为了保证外部碎片也小于 12.5%,可以一次多申请几个Page,但是又不能太多造成浪费。
func numMoveSize(size int) int { if size == 0 { return 0 } num := 64 * 1024 / size return minInt(32768, maxInt(2, num)) } func InitPages(classToSize []int) []int { classToPage := make([]int, 0, NumClass) for _, size := range classToSize { blocksToMove := numMoveSize(size) / 4 psize := 0 for { psize += PageSize for (psize % size) > (psize >> 3) { psize += PageSize } if (psize / size) >= blocksToMove { break } } classToPage = append(classToPage, psize>>PageShift) } return classToPage }
这里计算出来的结果,就是每个 size-class 每次申请的 Page 数量,保证12.5%以下的外部碎片。
到这里基本能够保证内部碎片和外部碎片都在 12.5% 以下了,但 TCMalloc 还没有就此止步
size-class的合并:
在我们上面计算出来的size-class中存在一些冗余,比如 1664,1792。它们都是一次申请2个Page,1664 可以分配出 8 * 1024 * 2 / 1664 = 9 个对象,1792也是可以分配出 8 * 1024 * 2 / 1792 = 9 个对象,那么,区分这两个 size-class有意义吗?1664浪费的内存是 8
1024
2%1664=1408, 1792浪费的内存是 8
1024
2%1792=256,1792浪费的内存反而更少一点。因此都保留并不能让这2 个Page 发挥更大的价值,所以,我们干脆把这两个合并了,仅仅保留 1792,结果并不会更差。
不过还有一个问题,如果我们计算一下[1536, 1792)的碎片,会发现 (1792-1536+1) / 1792 = 14.28% ,怎么大于 12.5 % 了?略尴尬。这也意味着,申请 1537字节,它的实际碎片率是 (8192
2 – (8192
2/1792*1537)) / (8192 * 2) = 15.57%,还是大于了 12.5% 的承诺。
这里会发现,虽然内部碎片小于 12.5%,外部碎片也小于 12.5%,但是它们加在一起就大于12.5%了
⑥ PageHeap
前面介绍的都是TCMalloc如何对内存进行划分,接下来看TCMalloc如何管理如此划分后的内存,这是PageHeap的主要职责
。
TCMalloc源码中对PageHeap的注释:
// ------------------------------------------------------------------------- // Page-level allocator // * Eager coalescing // // Heap for page-level allocation. We allow allocating and freeing a // contiguous runs of pages (called a "span"). // -------------------------------------------------------------------------
空闲Span管理器
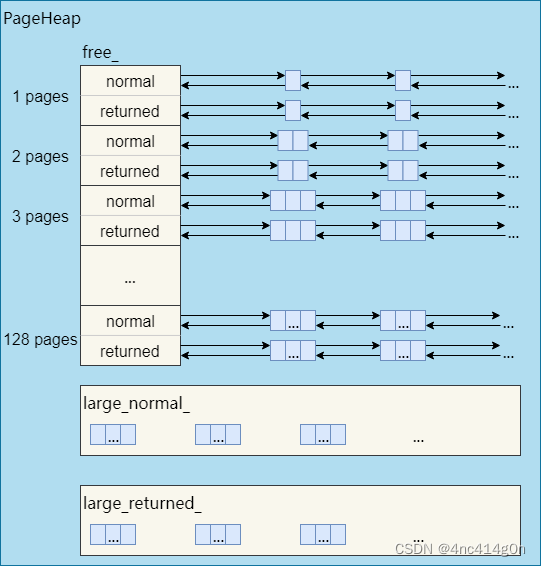
如前所述,128page以内的span称为小span,128page以上的span称为大span。PageHeap对于这两种span采取了不同的管理策略。小span用链表,而且每个大小的span都用一个单独的链表来管理。大span用std::set。
前文没有提到的是,从另一个维度来看,PageHeap是分开管理ON_NORMAL_FREELIST和ON_RETURNED_FREELIST状态的span的。因此,每个小span对应两个链表,所有大span对应两个set
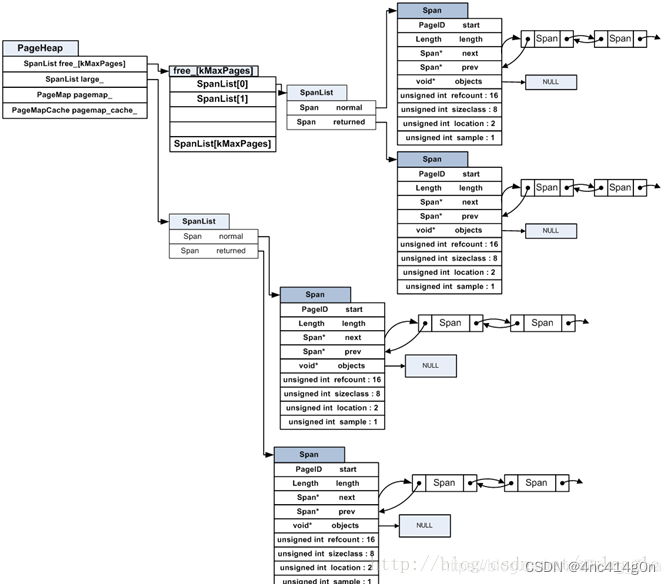
// We segregate spans of a given size into two circular linked // lists: one for normal spans, and one for spans whose memory // has been returned to the system. struct SpanList { Span normal; Span returned; }; // Array mapping from span length to a doubly linked list of free spans // // NOTE: index 'i' stores spans of length 'i + 1'. SpanList free_[kMaxPages]; // 128 typedef std::set<SpanPtrWithLength, SpanBestFitLess, STLPageHeapAllocator<SpanPtrWithLength, void> > SpanSet; // Sets of spans with length > kMaxPages. // // Rather than using a linked list, we use sets here for efficient // best-fit search. SpanSet large_normal_; SpanSet large_returned_;
因此,实际的PageHeap是这样的:
Heap段的使用限制
可以通过FLAGS_tcmalloc_heap_limit_mb对进程heap段的内存使用量进行限制,默认值0表示不做限制。如果开启了限制并且对heap段内存的使用量接近这个限制时,TCMalloc会更积极的将空闲内存释放给系统,进而会引发更多的软分页错误(minor page fault)
。
为了简化讨论,后文均假设没有对heap段的内存使用做任何限制。
创建Span
// Allocate a run of "n" pages. Returns zero if out of memory. // Caller should not pass "n == 0" -- instead, n should have // been rounded up already. Span* New(Length n);
创建span的过程其实就是分配中对象和大对象的过程,假设要创建k个page大小的span(以下简称大小为k的span),过程如下
:
搜索空闲span
Span* SearchFreeAndLargeLists(Length n);
搜索空闲span链表,按照以下顺序,找出第一个不小于k的span:
从大小为k的span的链表开始依次搜索
对于某个大小的span,先搜normal链表,再搜returned链表
如果span链表中没找到合适的span,则搜索存储大span的set:
从大小为k的span开始搜索
同样先搜normal再搜returned
优先使用长度最小并且起始地址最小的span(best-fit)
如果通过以上两步找到了一个大小为m的span,则将其拆成两个span:
大小为m – k的span重新根据大小和状态放回链表或set中
大小为k的span作为结果返回,创建span结束
如果没搜到合适的span,则继续后面的步骤:向系统申请内存
小插曲:释放所有空闲内存
ReleaseAtLeastNPages(static_cast<Length>(0x7fffffff));
当没有可用的空闲span时,需要向系统申请新的内存,但在此之前,还有一次避免向系统申请新内存的机会:释放所有空闲内存。向系统申请的内存每达到128MB,且空闲内存超过从系统申请的总内存的1/4,就需要将所有的空闲内存释放
。
因为TCMalloc将normal和returned的内存分开管理,而这两种内存不会合并在一起。因此,可能有一段连续的空闲内存符合要求(k个page大小),但因为它既有normal的部分,又有returned的部分,因此前面的搜索规则搜不到它。而释放所有内存可以将normal的内存也变为returned的,然后就可以合并了(合并规则详细后文合并span)
。
之所以控制在每128MB一次的频率,是为了避免高频小量申请内存的程序遭受太多的minor page fault
。
释放完毕后,会按照前面的搜索规则再次尝试搜索空闲span,如果还搜不到,才继续后续的步骤
向系统申请内存
bool GrowHeap(Length n);
找不到合适的空闲span,就只能向系统申请新的内存了
。
TCMalloc以sbrk()和mmap()两种方式向系统申请内存,所申请内存的大小和位置均按page对齐,优先使用sbrk(),申请失败则会尝试使用mmap()(64位系统Debug模式优先使用mmap,原因详见InitSystemAllocators()注释)
。
TCMalloc向系统申请应用程序所使用的内存时,每次至少尝试申请1MB(kMinSystemAlloc),申请TCMalloc自身元数据所使用的内存时,每次至少申请8MB(kMetadataAllocChunkSize)。这样做有两点好处:
减少外部内存碎片(减少所申请内存与TCMalloc元数据所占内存的交替)
均摊系统调用的开销,提升性能
另外,当从系统申请的总内存超过128MB时就为PageMap一次性申请一大块内存,保证可以存储所有page和span的对应关系。这一举措可以减少TCMalloc的元数据将内存分块而导致的外部碎片。从源码中可以发现,仅在32位系统下才会这样做,可能是因为64位系统内存的理论上限太大,不太现实
。// bool PageHeap::GrowHeap(Length n); if (old_system_bytes < kPageMapBigAllocationThreshold && stats_.system_bytes >= kPageMapBigAllocationThreshold) { pagemap_.PreallocateMoreMemory(); }
sbrk
先来看如何使用sbrk()从Heap段申请内存,下图展示了SbrkSysAllocator::Alloc()的执行流程,为了说明外部碎片的产生,并覆盖到SbrkSysAllocator::Alloc()的大部分流程,假设page大小为8KB,所申请的内存大小为16KB:
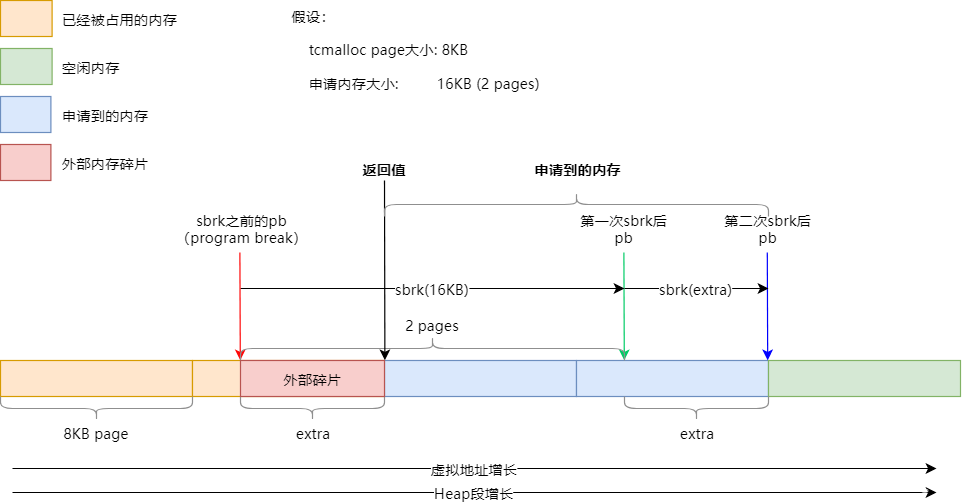
假设在申请内存之前,pb(program break,可以认为是堆内存的上边界)指向红色箭头所示位置,即没有在page的边界处
。
第一次sbrk申请16KB内存,因此pb移至绿色箭头所示位置
。
由于需要对申请的内存按page对齐,因此需要第二次sbrk,pb指向蓝色箭头所示位置,page的边界处
。
最终,返回的内存地址为黑色箭头所示位置,黑色和蓝色箭头之间刚好16KB。
可以看出,红色箭头和黑色箭头之间的内存就无法被使用了,产生了外部碎片
mmap
如果使用sbrk申请内存失败,TCMalloc会尝试使用mmap来分配。同样,为了覆盖MmapSysAllocator::Alloc()的大部分情况,下图假设系统的page为4KB,TCMalloc的page为16KB,申请的内存大小为32KB:
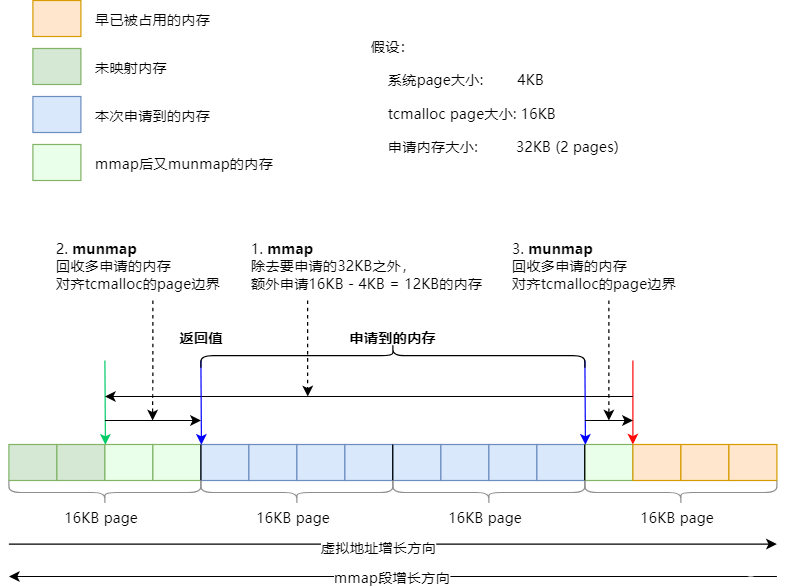
假设在申请内存之前,mmap段的边界位于红色箭头所示位置。
第一次mmap,会在32KB的基础上,多申请(对齐大小 – 系统page大小) = 16 -4 = 12KB的内存。此时mmap的边界位于绿色箭头所示位置
。
然后通过两次munmap将所申请内存的两侧边界分别对齐到TCMalloc的page边界。
最终申请到的内存为两个蓝色箭头之间的部分,返回左侧蓝色箭头所指示的内存地址
。
如果申请内存成功,则创建一个新的span并立即删除,可将其放入空闲span的链表或set中,然后继续后面的步骤。
最后的搜索
最后,重新搜索一次空闲span,如果还找不到合适的空闲span,那就认为是创建失败了。
至此,创建span的操作结束
删除Span
// Delete the span "[p, p+n-1]". // REQUIRES: span was returned by earlier call to New() and // has not yet been deleted. void Delete(Span* span);
当span所拆分成的小对象全部被应用程序释放变为空闲对象,或者作为中对象或大对象使用的span被应用程序释放时,需要将span删除。不过并不是真正的删除,而是放到空闲span的链表或set中
。
删除的操作非常简单,但可能会触发合并span的操作,以及释放内存到系统的操作
合并Span
当span被delete时,会尝试向前向后合并一个span。
合并规则如下:
只有在虚拟内存空间上连续的span才可以被合并。
只有同是normal状态的span或同是returned状态的span才可以被合并。

上图中,被删除的span的前一个span是normal状态,因此可以与之合并,而后一个span是returned状态,无法与之合并。合并操作之后如下图:

还有一个值得注意的开关:aggressive_decommit_,开启后TCMalloc会积极的释放内存给系统,默认是关闭状态,可通过以下方式更改:
MallocExtension::instance()->SetNumericProperty("tcmalloc.aggressive_memory_decommit", value)
当开启了aggressive_decommit_后,删除normal状态的span时会尝试将其释放给系统,释放成功则状态变为returned。
在合并时,如果被删除的span此时是returned状态,则会将与其相邻的normal状态的span也释放给系统,然后再尝试合并。
因此,上面的例子中,被删除的span和其前一个span都会被更改为returned状态,合并之后如下,即三个span被合并成为一个span:

释放span
Length ReleaseAtLeastNPages(Length num_pages);
在delete一个span时还会以一定的频率触发释放span的内存给系统的操作(ReleaseAtLeastNPages())。释放的频率可以通过>环境变量TCMALLOC_RELEASE_RATE来修改。默认值为1,表示每删除1000个page就尝试释放至少1个page,2表示每删除500个page尝试释放至少1个page,依次类推,10表示每删除100个page尝试释放至少1个page。0表示永远不释放,值越大表示>释放的越快,合理的取值区间为[0, 10]。
释放规则:
从小到大循环,按顺序释放空闲span,直到释放的page数量满足需求。
多次调用会从上一次循环结束的位置继续循环,而不会重新从头(1 page)开始。
释放的过程中能合并span就合并span
可能释放少于num_pages,没那么多free的span了。
可能释放多于num_pages,还差一点就够num_pages了,但刚好碰到一个很大的span。
释放方式:
如果系统支持,通过madvise(MADV_DONTNEED)释放span对应的内存。因此,即使释放成功,对应的虚拟内存地址空间仍然可访问,但内存的内容会丢失,在下次访问时会导致minor page fault以用0来重新初始化
⑦ ThreadCache
TCMalloc分配小对象的速度是非常快的,这得益于其对每个线程都有一份单独的cache,即ThreadCache。
ThreadCache其实就是一组FreeList而已。对于每个size class,在ThreadCache中都有一个FreeList,缓存了一组空闲对象,应用程序申请256KB以内的小内存时,优先返回FreeList中的一个空闲对象。因为每个线程每个size class都有单独的FreeList,因此这个过程是不需要加锁的,速度非常快。
如果FreeList为空,TCMalloc才会从size class对应的CentralFreeList中获取一组空闲对象放入ThreadCache的FreeList中,并将其中一个对象返回。从CentralFreeList中获取空闲对象需要加锁的。
回顾下ThreadCache的结构:
各个线程的ThreadCache互相连接成为一个双向链表,主要目的是为了方便统计信息

每线程Cache
那么每个线程一个ThreadCache是如何实现的呢?
这依赖于两种技术:Thread Local Storage(TLS),和Thread Specific Data(TSD)。两者的功能基本是一样的,都是提供每线程存储。TLS用起来更方便,读取数据更快,但在线程销毁时TLS无法执行清理操作,而TSD可以,因此TCMalloc使用TSD为每个线程提供一个ThreadCache,如果TLS可用,则同时使用TLS保存一份拷贝以加速数据的访问。
TLS和TSD的具体细节可参考
《The Linux Programming Interface》
相关章节(31.3,31.4),本文不再展开讨论。
详细可参考源码中ThreadCache::CreateCacheIfNecessary()函数和threadlocal_data_变量相关代码。
何时创建ThreadCache
当某线程第一次申请分配内存时,TCMalloc为该线程创建其专属的ThreadCache(ThreadCache::GetCache() -> ThreadCache::CreateCacheIfNecessary())。
何时销毁ThreadCache
在TCMalloc初始化TSD时,会调用Pthreads API中的pthread_key_create()创建ThreadCache对应的key,并且指定了销毁ThreadCache的函数ThreadCache::DestroyThreadCache()。因此,当一个线程销毁时,其对应的ThreadCache会由该函数销毁。
ThreadCache的大小
TCMalloc定义了一些变量来建议ThreadCache的大小。注意,是建议,而非强制。也就是说,实际的大小可能会超过这些值。
所有线程的ThreadCache的总大小限制(overall_thread_cache_size_)默认为32MB(kDefaultOverallThreadCacheSize),取值范围512KB~1GB,可以通过环境变量TCMalloc_MAX_TOTAL_THREAD_CACHE_BYTES或以下方式来进行调整:
MallocExtension::instance()->SetNumericProperty("TCMalloc.max_total_thread_cache_bytes", value);
每个线程的ThreadCache的大小限制默认为4MB(kMaxThreadCacheSize)。调整ThreadCache总大小时,会修改每个ThreadCache的大小限制到512KB~4MB之间的相应值。
慢启动算法:FreeList的长度控制
控制ThreadCache中各个FreeList中元素的数量是很重要的:
太小:不够用,需要经常去CentralCache获取空闲对象,带锁操作
太大:太多对象在空闲列表中闲置,浪费内存
不仅是内存分配,对于内存释放来说控制FreeList的长度也很重要:
太小:需要经常将空闲对象移至CentralCache,带锁操作
太大:太多对象在空闲列表中闲置,浪费内存
并且,有些线程的分配和释放是不对称的,比如生产者线程和消费者线程,这也是需要考虑的一个点。
类似TCP的拥塞控制算法,TCMalloc采用了慢启动(slow start)的方式来控制FreeList的长度,其效果如下:
FreeList被使用的越频繁,最大长度就越大。
如果FreeList更多的用于释放而不是分配,则其最大长度将仅会增长到某一个点,以有效的将整个空闲对象链表一次性移动到CentralCache中。
分配内存时的慢启动代码如下(FetchFromCentralCache):
const int batch_size = Static::sizemap()->num_objects_to_move(cl); // Increase max length slowly up to batch_size. After that, // increase by batch_size in one shot so that the length is a // multiple of batch_size. if (list->max_length() < batch_size) { list->set_max_length(list->max_length() + 1); } else { // Don't let the list get too long. In 32 bit builds, the length // is represented by a 16 bit int, so we need to watch out for // integer overflow. int new_length = min<int>(list->max_length() + batch_size, kMaxDynamicFreeListLength); // The list's max_length must always be a multiple of batch_size, // and kMaxDynamicFreeListLength is not necessarily a multiple // of batch_size. new_length -= new_length % batch_size; ASSERT(new_length % batch_size == 0); list->set_max_length(new_length); }
max_length即为FreeList的最大长度,初始值为1。batch_size是size class一节提到的一次性移动空闲对象的数量,其值因size class而异。
可以看到,只要max_length没有超过batch_size,每当FreeList中没有元素需要从CentralCache获取空闲对象时(即FetchFromCentralCache),max_length就加1。
一旦max_length达到batch_size,接下来每次FetchFromCentralCache就会导致max_length增加batch_size。
但并不会无限制的增加,最大到kMaxDynamicFreeListLength(8192),以避免从FreeList向CentralCache移动对象时,因为对象过多而过长的占用锁。
再来看内存回收时的情况,每次释放小对象,都会检查FreeList的当前长度是否超过max_length:
if (PREDICT_FALSE(length > list->max_length())) { ListTooLong(list, cl); return; }
如果超长,则执行以下逻辑:
void ThreadCache::ListTooLong(FreeList* list, uint32 cl) { size_ += list->object_size(); const int batch_size = Static::sizemap()->num_objects_to_move(cl); ReleaseToCentralCache(list, cl, batch_size); // If the list is too long, we need to transfer some number of // objects to the central cache. Ideally, we would transfer // num_objects_to_move, so the code below tries to make max_length // converge on num_objects_to_move. if (list->max_length() < batch_size) { // Slow start the max_length so we don't overreserve. list->set_max_length(list->max_length() + 1); } else if (list->max_length() > batch_size) { // If we consistently go over max_length, shrink max_length. If we don't // shrink it, some amount of memory will always stay in this freelist. list->set_length_overages(list->length_overages() + 1); if (list->length_overages() > kMaxOverages) { ASSERT(list->max_length() > batch_size); list->set_max_length(list->max_length() - batch_size); list->set_length_overages(0); } } if (PREDICT_FALSE(size_ > max_size_)) { Scavenge(); } }
与内存分配的情况类似,只要max_length还没有达到batch_size,每当FreeList的长度超过max_length,max_length的值就加1
当max_length达到或超过batch_size后,并不会立即调整max_length,而是累计超过3次(kMaxOverages)后,才会将max_length减少batch_size
垃圾回收
TODO:本节还没写完,请先参阅
官方介绍Garbage Collection of Thread Caches
一节
从ThreadCache中回收垃圾对象,将未使用的对象返回到CentralFreeList,可以控制缓存的大小。
不同线程对缓存大小的需求是不一样的,因此不能统一对待:有些线程需要大的缓存,有些线程需要小的缓存即可,甚至有些线程不需要缓存。
当一个ThreadCache大小超过其max_size_时,触发垃圾回收:
if (PREDICT_FALSE(size_ > max_size_)){ Scavenge(); }
只有当应用程序释放内存时(ThreadCache::Deallocate())才会触发垃圾回收,遍历ThreadCache中所有的FreeList,将FreeList中的一些对象移至对应的CentralFreeList中。
具体移动多少对象由低水位标记L(lowater_,每个FreeList一个)来决定。L记录自上次垃圾收集以来,FreeList的最小长度。
ThreadCache分析之线程局部缓存 (摘自其他文章)
线程局部缓存
tcmalloc采用线程局部存储技术为每一个线程创建一个ThreadCache,所有这些ThreadCache通过链表串起来
。
线程局部缓存有两种实现:
静态局部缓存,通过__thread关键字定义一个静态变量。
动态局部缓存,通过pthread_key_create,pthread_setspecific,pthread_getspecific来实现。
静态局部缓存的优点是设置和读取的速度非常快,比动态方式快很多,但是也有它的缺点。
静态缓存在线程结束时没有办法清除。
不是所有的操作系统都支持。
ThreadCache局部缓存的实现
tcmalloc采用的是动态局部缓存,但同时检测系统是否支持静态方式,如果支持那么同时保存一份拷贝,方便快速读取
。// If TLS is available, we also store a copy of the per-thread object // in a __thread variable since __thread variables are faster to read // than pthread_getspecific(). We still need pthread_setspecific() // because __thread variables provide no way to run cleanup code when // a thread is destroyed. // We also give a hint to the compiler to use the "initial exec" TLS // model. This is faster than the default TLS model, at the cost that // you cannot dlopen this library. (To see the difference, look at // the CPU use of __tls_get_addr with and without this attribute.) // Since we don't really use dlopen in google code -- and using dlopen // on a malloc replacement is asking for trouble in any case -- that's // a good tradeoff for us. #ifdef HAVE_TLS static __thread ThreadCache* threadlocal_heap_ # ifdef HAVE___ATTRIBUTE__ __attribute__ ((tls_model ("initial-exec"))) # endif ; #endif // Thread-specific key. Initialization here is somewhat tricky // because some Linux startup code invokes malloc() before it // is in a good enough state to handle pthread_keycreate(). // Therefore, we use TSD keys only after tsd_inited is set to true. // Until then, we use a slow path to get the heap object. static bool tsd_inited_; static pthread_key_t heap_key_;
尽管在编译器和连接器层面可以支持TLS,但是操作系统未必支持,因此需要实时的检查系统是否支持。主要是通过手动方式标识一些不支持的操作系统,代码如下(
thread_cache.h [cpp] view plain copy
):
// Even if we have support for thread-local storage in the compiler // and linker, the OS may not support it. We need to check that at // runtime. Right now, we have to keep a manual set of "bad" OSes. #if defined(HAVE_TLS) extern bool kernel_supports_tls; // defined in thread_cache.cc void CheckIfKernelSupportsTLS(); inline bool KernelSupportsTLS() { return kernel_supports_tls; } #endif // HAVE_TLS thread_cache.cc #if defined(HAVE_TLS) bool kernel_supports_tls = false; // be conservative #if defined(_WIN32) // windows has supported TLS since winnt, I think. void CheckIfKernelSupportsTLS() { kernel_supports_tls = true; } #elif !HAVE_DECL_UNAME // if too old for uname, probably too old for TLS void CheckIfKernelSupportsTLS() { kernel_supports_tls = false; } #else #include <sys/utsname.h> // DECL_UNAME checked for <sys/utsname.h> too void CheckIfKernelSupportsTLS() { struct utsname buf; if (uname(&buf) != 0) { // should be impossible Log(kLog, __FILE__, __LINE__, "uname failed assuming no TLS support (errno)", errno); kernel_supports_tls = false; } else if (strcasecmp(buf.sysname, "linux") == 0) { // The linux case: the first kernel to support TLS was 2.6.0 if (buf.release[0] < '2' && buf.release[1] == '.') // 0.x or 1.x kernel_supports_tls = false; else if (buf.release[0] == '2' && buf.release[1] == '.' && buf.release[2] >= '0' && buf.release[2] < '6' && buf.release[3] == '.') // 2.0 - 2.5 kernel_supports_tls = false; else kernel_supports_tls = true; } else if (strcasecmp(buf.sysname, "CYGWIN_NT-6.1-WOW64") == 0) { // In my testing, this version of cygwin, at least, would hang // when using TLS. kernel_supports_tls = false; } else { // some other kernel, we'll be optimisitic kernel_supports_tls = true; } // TODO(csilvers): VLOG(1) the tls status once we support RAW_VLOG } #endif // HAVE_DECL_UNAME #endif // HAVE_TLS
Thread Specific Key初始化
接下来看看每一个局部缓存是如何创建的。首先看看heap_key_的创建,它在InitTSD函数中
void ThreadCache::InitTSD() { ASSERT(!tsd_inited_); perftools_pthread_key_create(&heap_key_, DestroyThreadCache); tsd_inited_ = true; #ifdef PTHREADS_CRASHES_IF_RUN_TOO_EARLY // We may have used a fake pthread_t for the main thread. Fix it. pthread_t zero; memset(&zero, 0, sizeof(zero)); SpinLockHolder h(Static::pageheap_lock()); for (ThreadCache* h = thread_heaps_; h != NULL; h = h->next_) { if (h->tid_ == zero) { h->tid_ = pthread_self(); } } #endif }
该函数在TCMallocGuard的构造函数中被调用。TCMallocGuard类的声明和定义分别在tcmalloc_guard.h和tcmalloc.cc文件中
。class TCMallocGuard { public: TCMallocGuard(); ~TCMallocGuard(); }; // The constructor allocates an object to ensure that initialization // runs before main(), and therefore we do not have a chance to become // multi-threaded before initialization. We also create the TSD key // here. Presumably by the time this constructor runs, glibc is in // good enough shape to handle pthread_key_create(). // // The constructor also takes the opportunity to tell STL to use // tcmalloc. We want to do this early, before construct time, so // all user STL allocations go through tcmalloc (which works really // well for STL). // // The destructor prints stats when the program exits. static int tcmallocguard_refcount = 0; // no lock needed: runs before main() TCMallocGuard::TCMallocGuard() { if (tcmallocguard_refcount++ == 0) { #ifdef HAVE_TLS // this is true if the cc/ld/libc combo support TLS // Check whether the kernel also supports TLS (needs to happen at runtime) tcmalloc::CheckIfKernelSupportsTLS(); #endif ReplaceSystemAlloc(); // defined in libc_override_*.h tc_free(tc_malloc(1)); ThreadCache::InitTSD(); tc_free(tc_malloc(1)); // Either we, or debugallocation.cc, or valgrind will control memory // management. We register our extension if we're the winner. #ifdef TCMALLOC_USING_DEBUGALLOCATION // Let debugallocation register its extension. #else if (RunningOnValgrind()) { // Let Valgrind uses its own malloc (so don't register our extension). } else { MallocExtension::Register(new TCMallocImplementation); } #endif } } TCMallocGuard::~TCMallocGuard() { if (--tcmallocguard_refcount == 0) { const char* env = getenv("MALLOCSTATS"); if (env != NULL) { int level = atoi(env); if (level < 1) level = 1; PrintStats(level); } } } #ifndef WIN32_OVERRIDE_ALLOCATORS static TCMallocGuard module_enter_exit_hook; #endif
线程局部缓存Cache的创建和关联
接下来看如何创建各个线程的ThreadCache的创建。我们看GetCache代码,该代码在do_malloc中被调用
。inline ThreadCache* ThreadCache::GetCache() { ThreadCache* ptr = NULL; if (!tsd_inited_) { InitModule(); } else { ptr = GetThreadHeap(); } if (ptr == NULL) ptr = CreateCacheIfNecessary(); return ptr; } void ThreadCache::InitModule() { SpinLockHolder h(Static::pageheap_lock()); if (!phinited) { Static::InitStaticVars(); threadcache_allocator.Init(); phinited = 1; } }
该函数首先判断tsd_inited_是否为true,
该变量在InitTSD中被设置为true。那么首次调用GetCache时tsd_inited_肯定为false,
这时就InitModule就会被调用。InitModule函数主要是来进行系统的内存分配器初始化。
如果tsd_inited_已经为true了,那么线程的thread specific就可以使用了,
GetThreadHeap就是通过heap_key_查找当前线程的ThreadCache. 如果ptr为NULL,那么CreateCacheIfNecessary就会被调用,该函数来创建ThreadCache
ThreadCache* ThreadCache::CreateCacheIfNecessary() {
// Initialize per-thread data if necessary
ThreadCache* heap = NULL;
{
SpinLockHolder h(Static::pageheap_lock());
// On some old glibc's, and on freebsd's libc (as of freebsd 8.1),
// calling pthread routines (even pthread_self) too early could
// cause a segfault. Since we can call pthreads quite early, we
// have to protect against that in such situations by making a
// 'fake' pthread. This is not ideal since it doesn't work well
// when linking tcmalloc statically with apps that create threads
// before main, so we only do it if we have to.
#ifdef PTHREADS_CRASHES_IF_RUN_TOO_EARLY
pthread_t me;
if (!tsd_inited_) {
memset(&me, 0, sizeof(me));
} else {
me = pthread_self();
}
#else
const pthread_t me = pthread_self();
#endif
// This may be a recursive malloc call from pthread_setspecific()
// In that case, the heap for this thread has already been created
// and added to the linked list. So we search for that first.
for (ThreadCache* h = thread_heaps_; h != NULL; h = h->next_) {
if (h->tid_ == me) {
heap = h;
break;
}
}
if (heap == NULL) heap = NewHeap(me);
}
// We call pthread_setspecific() outside the lock because it may
// call malloc() recursively. We check for the recursive call using
// the "in_setspecific_" flag so that we can avoid calling
// pthread_setspecific() if we are already inside pthread_setspecific().
if (!heap->in_setspecific_ && tsd_inited_) {
heap->in_setspecific_ = true;
perftools_pthread_setspecific(heap_key_, heap);
#ifdef HAVE_TLS
// Also keep a copy in __thread for faster retrieval
threadlocal_heap_ = heap;
#endif
heap->in_setspecific_ = false;
}
return heap;
}
ThreadCache* ThreadCache::NewHeap(pthread_t tid) {
// Create the heap and add it to the linked list
ThreadCache *heap = threadcache_allocator.New();
heap->Init(tid);
heap->next_ = thread_heaps_;
heap->prev_ = NULL;
if (thread_heaps_ != NULL) {
thread_heaps_->prev_ = heap;
} else {
// This is the only thread heap at the momment.
ASSERT(next_memory_steal_ == NULL);
next_memory_steal_ = heap;
}
thread_heaps_ = heap;
thread_heap_count_++;
return heap;
}
CreateIfNecessary创建一个ThreadCache对象,并且将该对象与当前线程的pthread_key_关联,同时添加到ThreadCache链表的头部。这里有个特别的情况需要说明,首次调用malloc所创建的ThreadCache对象没有和pthread_key_关联,只是添加到了ThreadCache链表中去了,程序可能还会在tsd_inited_为true之前多次调用malloc,也就会多次进入CreateCacheIfNecessary函数,这时函数中会去遍历ThreadCache链表,发现当前线程已经创建好的ThreadCache对象
⑧ CentralCache
CentralCache是逻辑上的概念,其本质是CentralFreeListPadded类型(CentralFreeList的子类,用于64字节对齐)的数组,每个size class对应数组中的一个元素。
ATTRIBUTE_HIDDEN static CentralFreeListPadded central_cache_[kClassSizesMax];
由于各线程公用一个CentralCache,因此,使用CentralCache时需要加锁。
以下讨论都是针对某一个size class的。
CentralFreeList中缓存了一系列小对象,供各线程的ThreadCache取用,各线程也会将多余的空闲小对象还给CentralFreeList
另外CentralFreeList还负责从PageHeap申请span以分割成小对象,以及将不再使用的span还给PageHeap。
管理span
CentralFreeList真正管理的是span,而小对象是包含在span中的空闲对象链表中的。CentralFreeList的empty_链表保存了已经没有空闲对象可用的span,nonempty_链表保存了还有空闲对象可用的span:
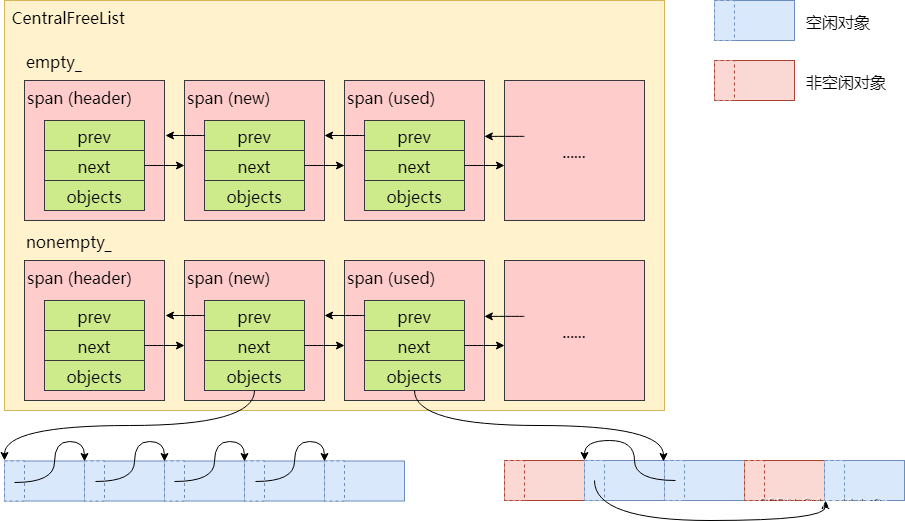
CentralFreeList↔ PageHeap
从PageHeap获取span
当ThreadCache从CentralFreeList取用空闲对象(RemoveRange),但CentralFreeList的空闲对象数量不够时,CentralFreeList调用Populate()从PageHeap申请一个span拆分成若干小对象,首首连接记录在span的objects指针中,即每个小对象的起始位置处,记录了下一个小对象的地址。此时的span如下图:
可以看到,此时span包含的对象按顺序连接在一起。
新申请的span被放入CentralFreeList的nonempty_链表头部。
将span还给PageHeap
CentralFreeList维护span的成员变量refcount,用来记录ThreadCache从中获取了多少对象。
当ThreadCache将不再使用的对象归还给CentralCache以致refcount减为0,即span中所有对象都空闲时,则CentralCache将这个span还给PageHeap。截取CentralFreeList::ReleaseToSpans()部分代码如下:
span->refcount--; if (span->refcount == 0) { Event(span, '#', 0); counter_ -= ((span->length<<kPageShift) / Static::sizemap()->ByteSizeForClass(span->sizeclass)); tcmalloc::DLL_Remove(span); --num_spans_; // Release central list lock while operating on pageheap lock_.Unlock(); { SpinLockHolder h(Static::pageheap_lock()); Static::pageheap()->Delete(span); } lock_.Lock(); }
CentralFreeList↔ThreadCache
CentralFreeList和ThreadCache之间的对象移动是批量进行的:
// Insert the specified range into the central freelist. N is the number of // elements in the range. RemoveRange() is the opposite operation. void InsertRange(void *start, void *end, int N); // Returns the actual number of fetched elements and sets *start and *end. int RemoveRange(void **start, void **end, int N);
start和end指定小对象链表的范围,N指定小对象的数量。批量移动小对象可以均摊锁操作的开销
ThreadCache取用小对象
当ThreadCache中某个size class没有空闲对象可用时,需要从CentralFreeList获取N个对象,那么N的值是多少呢?从ThreadCache::FetchFromCentralCache()中可以找到答案:
const int batch_size = Static::sizemap()->num_objects_to_move(cl); const int num_to_move = min<int>(list->max_length(), batch_size); void *start, *end; int fetch_count = Static::central_cache()[cl].RemoveRange(&start, &end, num_to_move);
移动数量N为max_length和batch_size的最小值(两者的具体涵义参见ThreadCache慢启动一节)
。
假设只考虑内存分配的情况,一开始移动1个,然后是2个、3个,以此类推,同时max_length每次也加1,直到达到batch_size后,每次移动batch_size个对象
。
CentralFreeList和ThreadCache之间的对象移动有个优化措施,因为大部分情况都是每次移动batch_size个对象,为了减少链表操作,提升效率,CentralFreeList将移动的batch_size个对象的链表的首尾指针缓存在了TCEntry中。因此后续只要需要移动batch_size个对象,只需要操作链表的首尾即可
。// Here we reserve space for TCEntry cache slots. Space is preallocated // for the largest possible number of entries than any one size class may // accumulate. Not all size classes are allowed to accumulate // kMaxNumTransferEntries, so there is some wasted space for those size // classes. TCEntry tc_slots_[kMaxNumTransferEntries];
ThreadCache归还小对象
当ThreadCache中的空闲对象过多时(ThreadCache::ListTooLong()),会将一部分空闲对象放回CentralFreeList(ThreadCache::ReleaseToCentralCache())。如何判断空闲对象过多请参考ThreadCache慢启动一节
。
线程销毁也会将其ThreadCache中所有的空闲对象都放回CentralFreeList。
如果ThreadCache缓存的内存大小超过其允许的最大值,会触发GC操作(ThreadCache::Scavenge()),在其中也会将部分小对象归还给CentralFreeList,具体请参考ThreadCache垃圾回收一节。
7)一些图
ThreadCache:
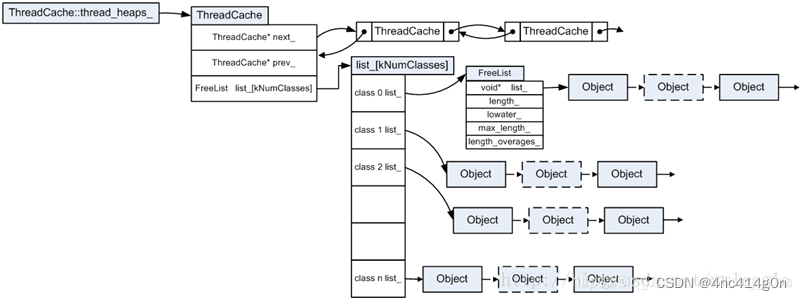
实现:
CentralCache
span:
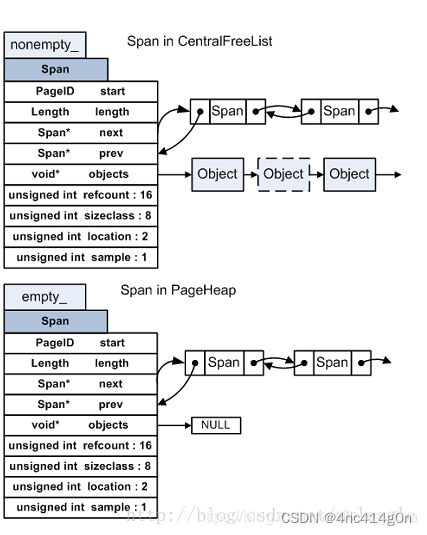
CentralFreelist内存分配

PageMap pagemap_
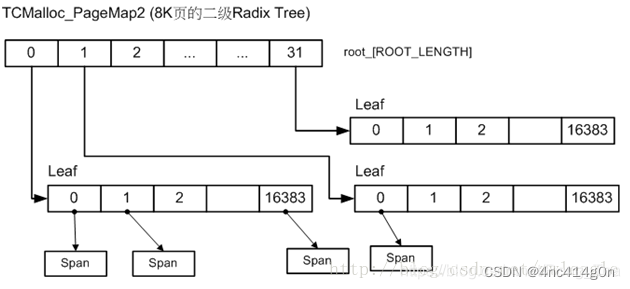
PageHeap