平常我们对分类的判断也是基于标题中的某些字,或者某些词性。比如《姚明篮球打的怎样》应该判别为体育,这时候“姚明”,“篮球”应该算对我们比较重要的词汇。词性我们关注点在“人名”和“名词”上面,深度学习的attention机制刚好符合这个特点。我们能不能利用attention机制来做分类呢,并且让注意力集中在我们期望的词上呢?
先贴个结果,
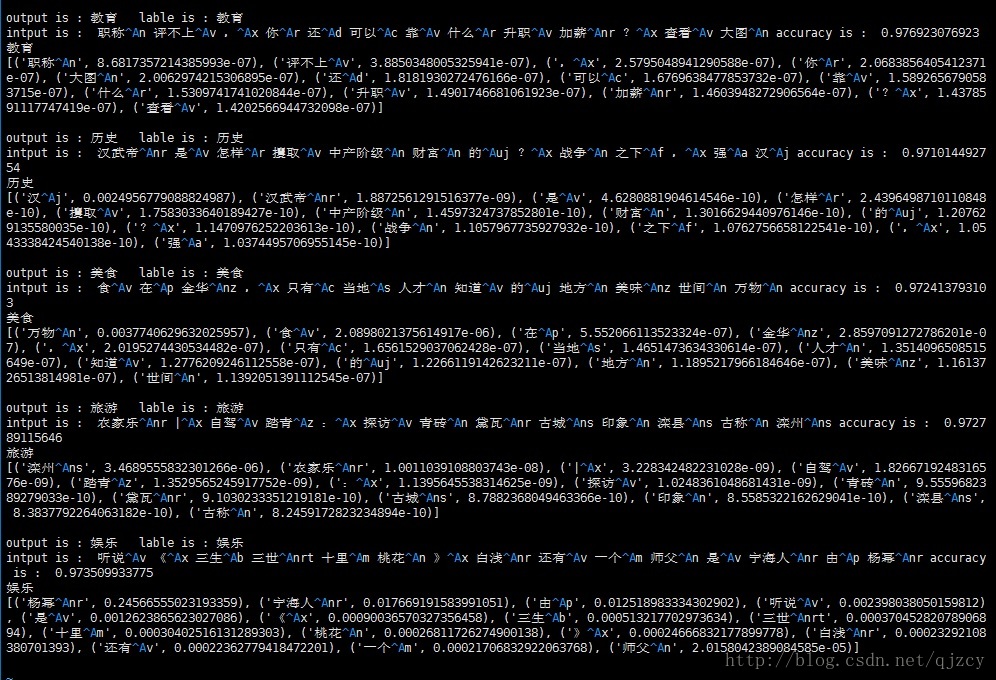
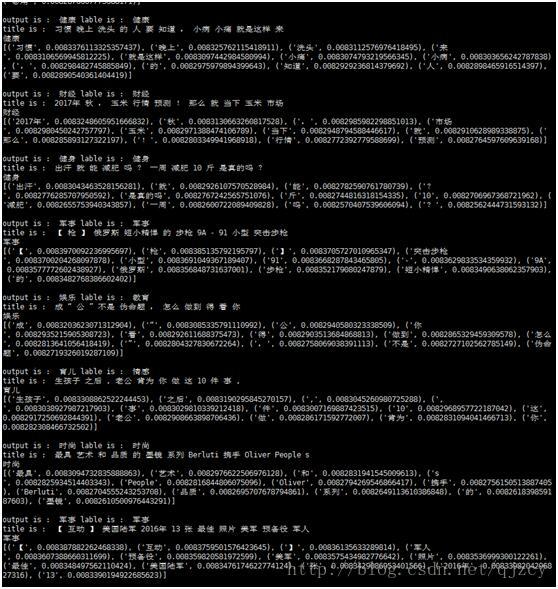
output是机器跑的分类结果,lable是人工打的分类结果。最后一段是机器对每个词的权重打分
准确率大概在95%左右。使用词性后准确率和attention的可解释性都得到了提升。
格式:
第一行‘输出’ ‘标签’
第二行 ‘输入’ ’总体准确率‘
第三行 不同词的attention值,从大到小排序
使用词性+attention后结果
仅使用attention结果
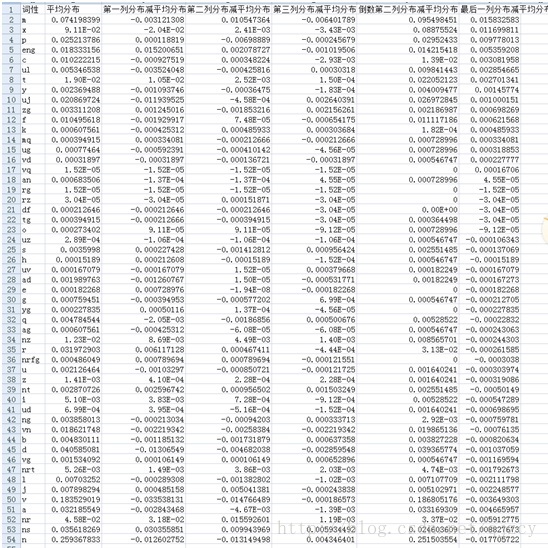
每列词性的分布减去词性平均分布得到排序前十,我们可以看到,前几列更侧重在专有名词,实体词方面。后几列更侧重在介词,组词,语气词方面。这和我们平时经验相吻合
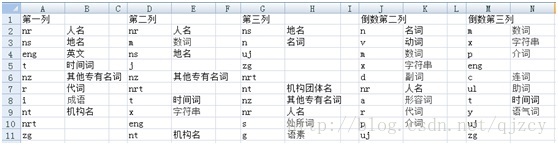
不同位置词性的分布:
计算方法:不同位置词性的分布减去词性平均分布得到得分
算法原理:
Attention机制,论文中的公式如下。
我们对在公式2进行修改,eij=vaT*tanh(Wa*Si-1+Ua*hj+w3*pi),其中pi是为每个词扩展开的词性向量,w3为权重参数,这样我们就很好的把词性和词的attention机制结合起来。
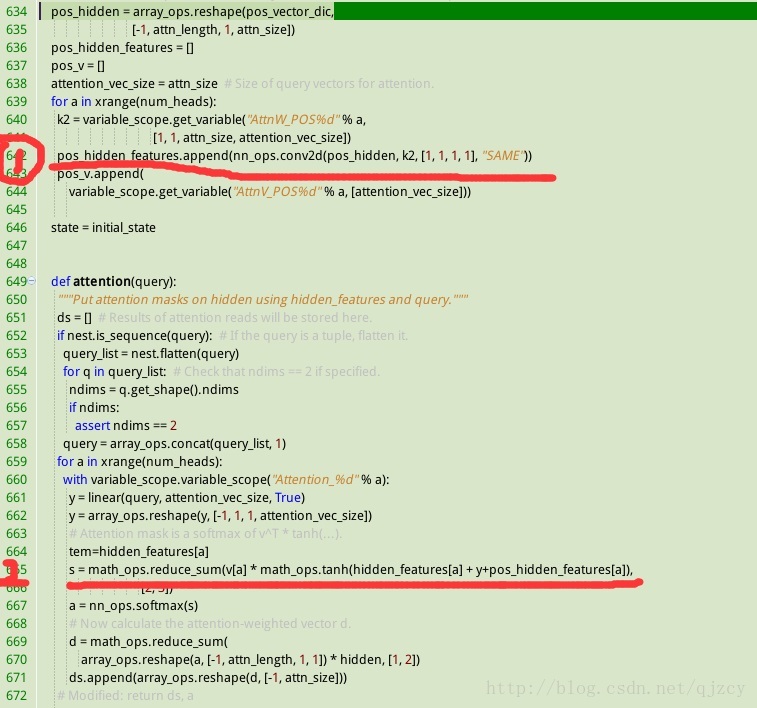
代码实现:
如下图所示, 红线1位置实现w3*pi, 红线2位置实现eij=vaT*tanh(Wa*Si-1+Ua*hj+w3*pi)
词性attention扩展的不同方式延展思考:
如上所示我们可以把词性并列的扩展,然后把各权重值进行叠加。其实我们也可以把词性和词的扩展拼接在一起,完成对attention的词性扩展。从美学上来说这种方式应该更加合理。但是这种方式会增加更多的w权重参数。比如同样是batch*20个词*扩展256维进行词性扩展。并行的扩展添加的w3维度也是batch*120*256。如果采用拼接的方式除了需要词性w3维度batch*20*256 还需要额外把dt的w2维度扩展batch*1*256