文章目录
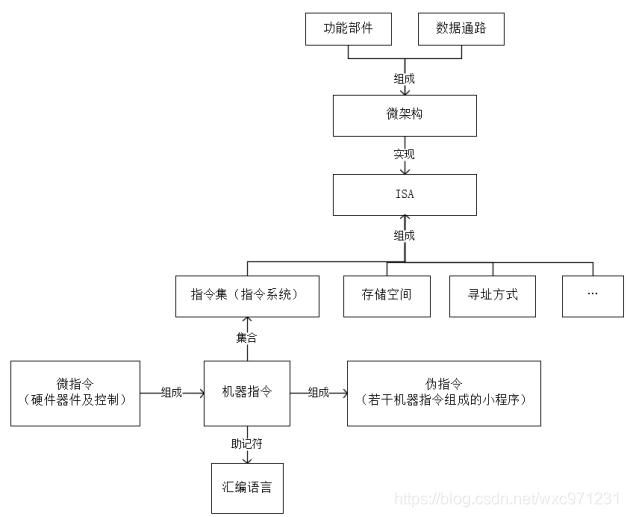
一、指令集体系结构(ISA)的基础概念
1. 指令相关概念
- CPU只能识别指令形式的机器语言(01序列),不管C、python还是什么高级语言,都需要翻译(编译、汇编、解释)为机器语言才能执行
-
指令可以分为三个类型
-
微指令
:
微程序级的命令
,它属于
硬件
; -
宏指令(伪指令)
:由
若干条机器指令组成
的软件指令,它属于软件; -
机器指令
:介于微指令和伪指令之间,处于硬件和软件的交界面,每一条指令可完成一个独立的算术运算或逻辑运算操作。
一般讲的指令就是指机器指令
- 一条机器指令对应了硬件层面的一段微程序,微程序由若干微指令组成。比如在多周期CPU中执行一个加法指令,它可能对应了类似这样的一段微程序:从寄存器取操作数 -> 运算 -> 结果写回寄存器,这里就是三条微指令,每个机器周期执行一条。
- 机器指令就是一串二进制的01序列
-
-
指令集(指令系统)
:一台机器可以执行的
机器指令的集合
,它是
ISA的核心组成部分
-
微架构
:处理器核心的实现方式,是
将一种给定的ISA在处理器中执行的方法
2. 什么是ISA
-
ISA(指令集体系结构)是一种
规约
(Specification),它
规定了如何使用硬件
,是一种对硬件的抽象
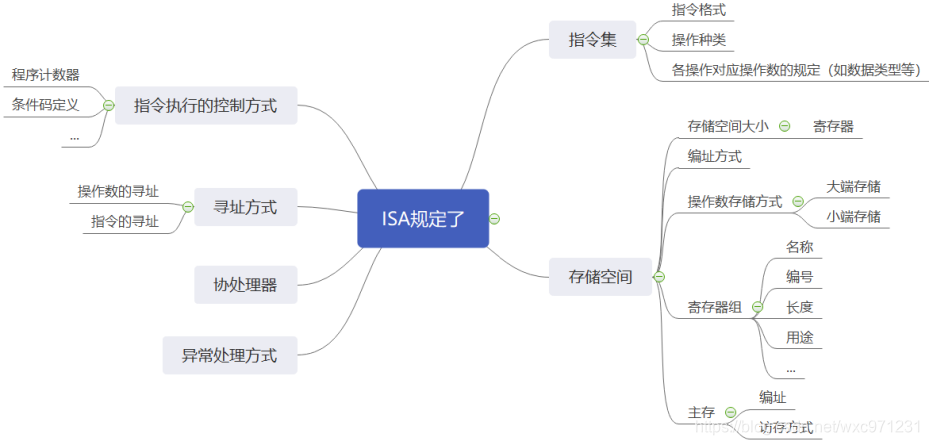
-
关系图
3. ISA的地位
(1)ISA是软件和硬件的交界面(接口)
-
计算机体系结构示意
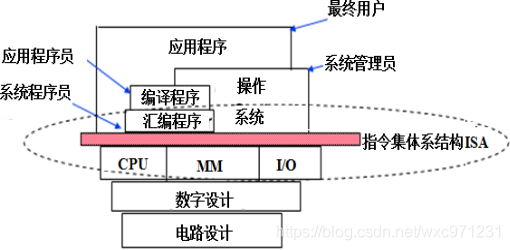
-
指令系统处在软/硬件交界面,同时被硬件设计者和系统程序员看到
-
硬件设计者角度:
指令系统为CPU提供功能需求
,要求易于硬件设计 -
系统程序员角度:
通过指令系统来使用硬件
,要求易于编写编译器
-
硬件设计者角度:
-
ISA是对硬件的抽象,所有软件功能都建立在 ISA之上
(2)ISA是计算机的必要组成部分
- ISA是最贴近CPU的,它规定了CPU可以理解的机器码语法以及部分CPU设计要求,因此它在计算机体系结构的发展中一直存在。它是CPU的接口,只要有计算机硬件,就有ISA。
- 操作系统、各种层次的编程语言等等都是建立与ISA之上的,它们即使这些都没有,我们直接写机器码也可以让计算机正常工作
-
计算机体系结构的发展
简图
如下,可以看到
其中都有ISA
:-
最早的计算机,用机器语言编程

-
之后出现了OS和汇编语言,可以执行多道程序

-
现代计算机体系结构

-
最早的计算机,用机器语言编程
-
最后附一张不同层次的计算机工作者对计算机的认识
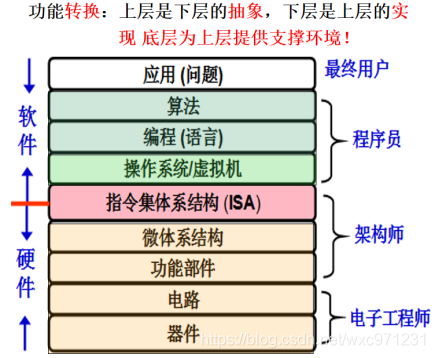
-
下面,
针对ISA的核心组成部分——指令集(指令系统),进行进一步介绍
二、指令格式设计
1. 一条指令必须包含的信息
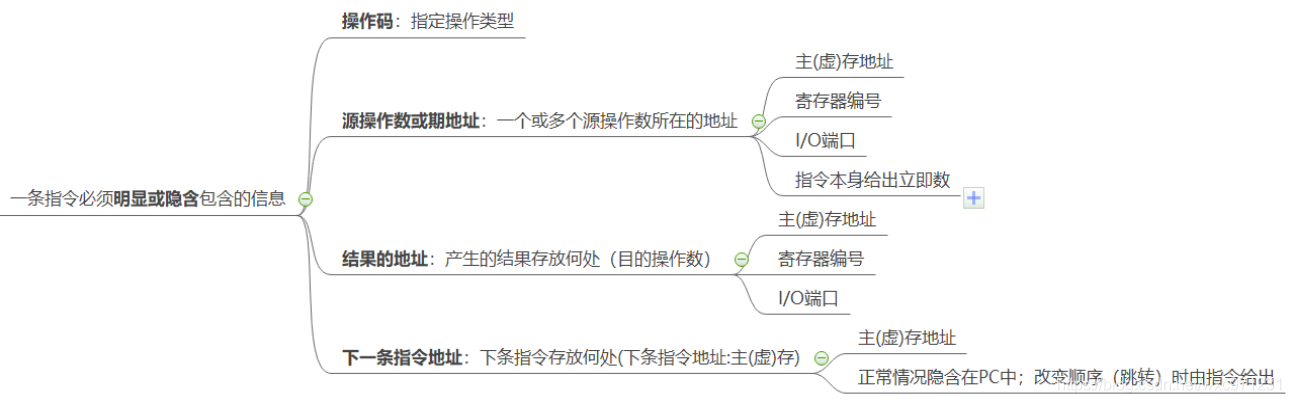
2. 不同地址码个数的指令
-
这里的地址是指一个操作数所在的地址
。它具体可能是寄存器编号、存储器地址、I/O端口或指令立即数等等…

3. 从指令执行周期看指令设计涉及的问题
-
CPU的运行流程:
-
取指令 – 指令译码 – 计算地址取操作数 – 进行运算,得标志位 – 计算结果送目的地 – 计算下条指令地址
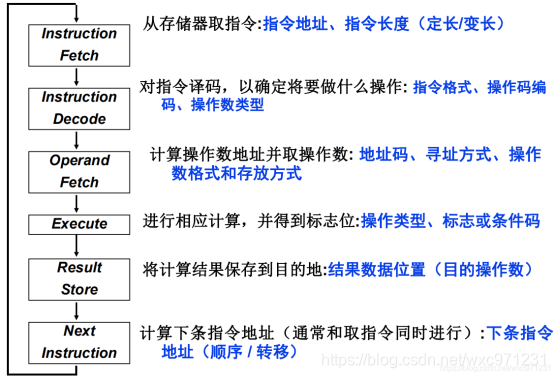
-
上面这种划分得比较细,一个标准五级流水线中是这样划分的:
取指 - 译码 - 执行 - 访存 - 写回
-
三、指令系统设计
1. 设计指令系统
(1)设计原则
- 应尽量短
- 要有足够的操作码位数
- 指令编码必须有唯一的解释,否则是不合法的指令
- 指令字长应是字节的整数倍
- 合理地选择地址字段的个数
- 指令尽量规整
(2)设计的重要方面
-
操作码的全部组成
:操作码个数 / 种类 / 复杂度 (主存读写、自增、跳转四种指令已足够编制任何可计算程序,但程序会很长) -
数据类型
:对哪几种数据类型完成操作 -
指令格式
:指令长度 / 地址码个数 / 各字段长度(看上面
一、2
部分) -
通用寄存器
:个数 / 功能 / 长度 -
寻址方式
:操作数地址的指定方式 -
下条指令的地址如何确定
:顺序,PC+1;条件转移;无条件转移;…… - 一条指令的功能,一般通过对操作码进行不同的编码来定义; 操作码相同时,再由功能码进行区分(例如MIPS的R型指令)
2. 操作数类型和存储方式
-
操作数
:指令处理的对象,与高级语言的数据类型对应
-
操作数存放在
寄存器
或
内存单元
中
(1)指令应涉及的基本数据类型
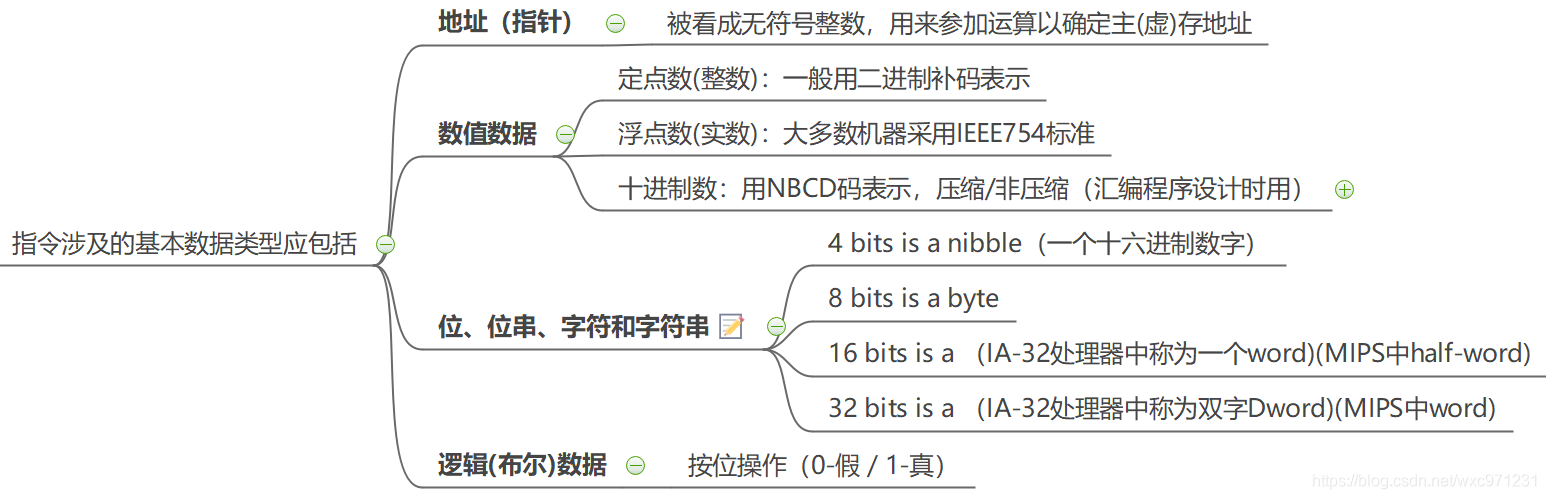
(2)IA32和MIPS中的数据类型
-
IA-32(英特尔32位体系架构,80386开始采用)
- 基本类型:字节、字(16位)、双字(32位)、四字(64位)
- 整数: 16位、32位、64位三种2-补码表示的整数;18位压缩8421 BCD码表示的十进制整数
- 无符号整数(8、16或32位)
- 近指针:32位段内偏移(有效地址)
- 浮点数:IEEE 754(80位扩展精度浮点数寄存器)
-
MIPS
- 基本类型:字节、半字(16位)、字(32位)、四字(64位)
- 整数: 16位、32位、64位三种2-补码表示的整数
- 无符号整数:(16、32位)
- 浮点数:IEEE 754(32位/64位浮点数寄存器)
3. 寻址方式
(1)关于寻址
-
寻址方式
:指令或操作数地址的指定方式。即:根据地址找到指令或操作数的方法
,通常特指 “操作数的寻址” -
指令中如何表示寻址方式
-
没有专门的寻址方式位(由操作码确定寻址方式)
:如MIPS指令,一条指令中最多仅有一个主(虚)存地址,且仅有一到两种寻址方式。 -
有专门的寻址方式位
:如X86指令,一条指令中有多个操作数,且寻址方式各不相同, 需要各自说明寻址方式,因此每个操作数有专门的寻址方式位
-
- 常用寻址方式:立即 / 直接 / 间接 / 寄存器 / 寄存器间接 / 偏移 / 堆栈…
(2)有效地址和地址编码
-
有效地址
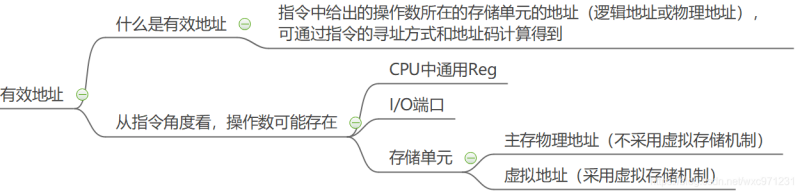
-
地址编码

(3)指令的寻址
-
指令寻址

(4)操作数的寻址
1. 常用寻址方式
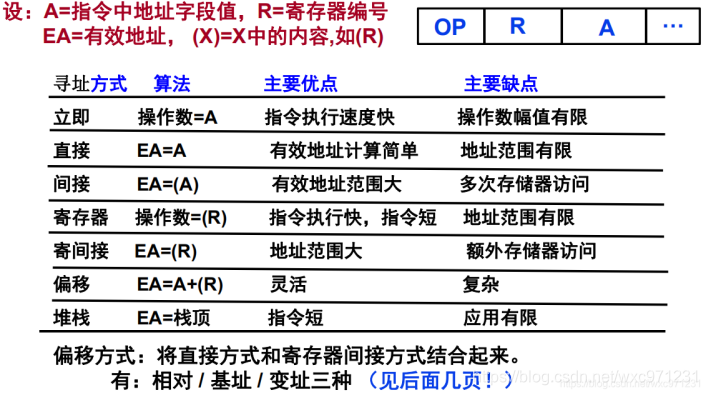
-
EA是操作数在主存中的地址,得到EA后,
还要访存
才能得到操作数 -
操作数的真实位置
-
在指令中
直接给出:立即寻址 -
在寄存器中
:寄存器寻址 -
在主存中
:以上除了立即和寄存器之外所有 -
在磁盘中
:对于在主存中的操作数,可能发生 “缺页” ,此时操作数在磁盘中,需要被置换进主存
-
- 偏移寻址有三种,这块比较复杂,下面逐一分析
2. 三种偏移寻址方式详述
-
寻址算法思想
-
思维导图

- 可见,所谓偏移寻址就是利用基地址和地址偏移量计算目标地址,根据地址给出形式的不同,可以分成三种类型。
-
一般RISC机器不提供自动变址寻址,并将变址和基址寻址统一成一种 “偏移寻址方式”
。比如MIPS就是这样的
-
思维导图
-
相对寻址:
EA=A+(PC)
-
定义:
目标地址 = 相对于PC寄存器当前值的位移量为A的存储单元
。指令地址码给出一个偏移量(带符号数),基准地址由PC寄存器隐含给出 -
注意:当前PC值可能是
本条指令
(没有指令预取,如单周期CPU)或
下一条指令
的地址(有指令预取,如流水线CPU) -
可用来实现
程序(公共子程序)的浮动
或
指定转移目标地址
-
公共子程序的浮动:
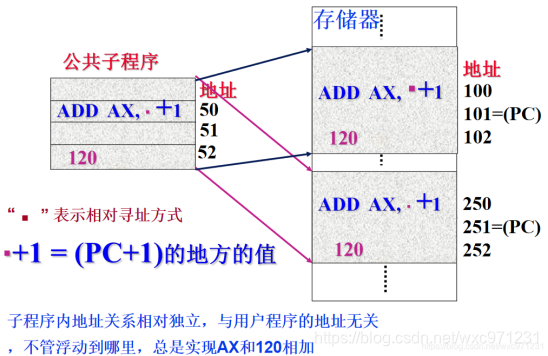
-
相对寻址实现相对转移
-
举例:双字节(2个字节)定长指令字,第一字节是操作码Jxx,第二字节是
位移量D,用补码表示
。目标地址范围不等于位移量D的表示范围,只有确定了是
按字还是字节编址、位移量D是指指令条数还是单元数
,才能确定目标地址范围。若D为字节单元数,跳转范围[-126,128]单元,[-63,64]条指令

-
假设使用流水线技术,有指令预取,按字节编址,指令长度为双字节,D代表单元数,则
目标地址 = (PC) +2 +D
。由于流水线,在取这条Jxx指令的时候,PC已经+1了,指令长度又是双字节,所以要先加2得到此刻Jxx指令的地址,然后再加单元偏移D得到目的地址 -
举例:若转移指令地址为2000H,转移目标地址为1FF0H,总是在取指令同时对PC增量(流水线),则转移指令第二字节位移量为多少?

-
举例:MIPS指令
beq $1, $2, Label_25
的转移目标地址为
(PC)+4+4*25
,这里的25是
指令条数而
不是单元数,MIPS采用定长指令字,按字节编址,所有指令的长度都是32位(4字节)。 -
说明:
MIPS采用定长指令字,按字节编址, 所有指令的长度都是32位(4字节)
-
-
-
定义:
-
基址寻址:
EA=A+(B)
-
定义:
目标地址 = 相对于基址(B)处位移量为A的单元
。指令地址码给出一个偏移量,基准地址 由基址寄存器B给出。 (例如MIPS指令
lw / sw $s2, 0x40($t1)
) -
可用来实现
多道程序重定位
或
过程调用中参数的访问
-
基址寻址实现程序重定位

-
基址寻址实现程序重定位
-
定义:
-
变址寻址:
EA=A+(I)
-
定义:
目标地址 = 相对于首址A处位移量为(I)的单元
。指令地址码给出一个基准(形式)地址A ,而偏移量(无符号数) 由变址寄存器 I 给出。(例如Intel 8086指令
MOV AL, [SI+1000H]
,这里SI就是I, 1000H就是A。) -
MIPS中没有变址寄存器;IA32中有
。 -
可为
循环重复操作
提供一种高效机制,如实现对线性SK表IP的方便操作
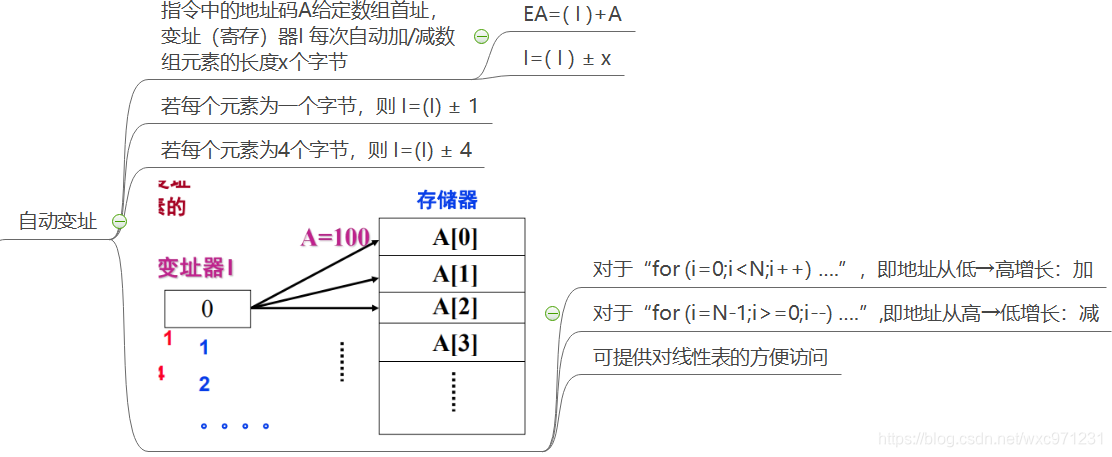
-
定义:
4. 操作码编码

(1)定长操作码编码
-
思维导图

-
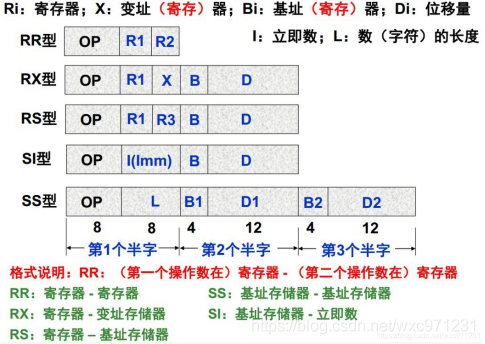
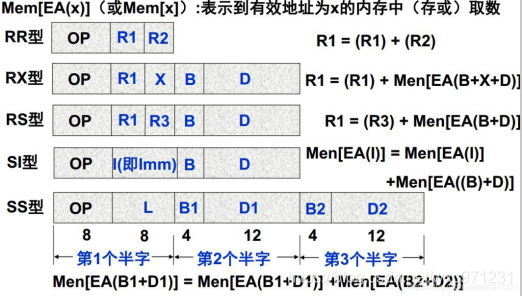
举例:IBM360/370的指令格式
-
可以看到,各种指令类型中,
OP
段(操作码)的编码长度都是一致的 -
IBM360/370使用了
定长操作码,变长指令字
-
可以看到,各种指令类型中,
(2)变长操作码编码
-
基本思想
-
将
操作码
的编码长度分成
几种固定长的格式
-
指令格式:
变长操作码、变长指令字
-
将
-
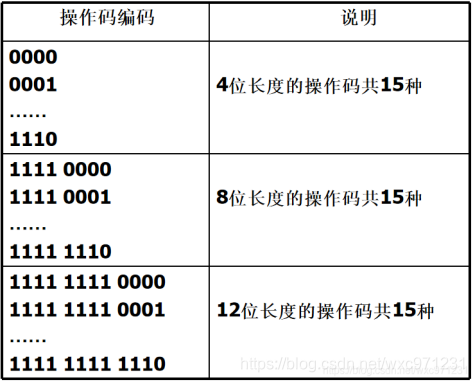
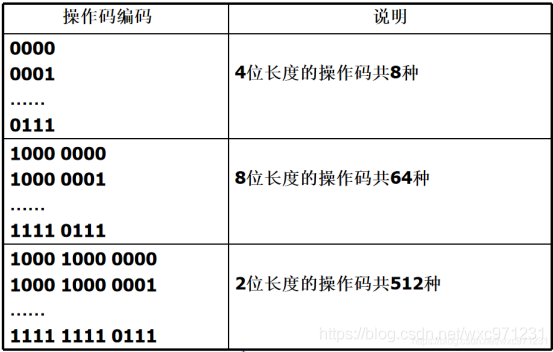
变长操作码编码有两种
- 扩展编码
- 哈夫曼编码
- PDP-11是典型的变长操作码机器
- 大多数指令集采用变长操作码编码这种方式
1. 哈夫曼编码
- 这就是数据结构中学习过的哈夫曼编码,可以有效压缩操作码的平均长度
- 通过构造一棵哈夫曼数,我们可以轻松获取每个操作码的哈夫曼编码,这里不展开说了
-
哈夫曼编码应用于指令设计时存在一些问题
-
操作码长度很不规整
; -
硬件译码困难
-
与地址码共同组成
固定长的指令比较困难
-
2. 扩展编码
-
核心原则:任意操作码的编码不能是另一个操作码的编码的前缀
-
等长15/15/15扩展编码
-
等长8/64/512扩展编码
-
不等长操作码4/6/10扩展编码法
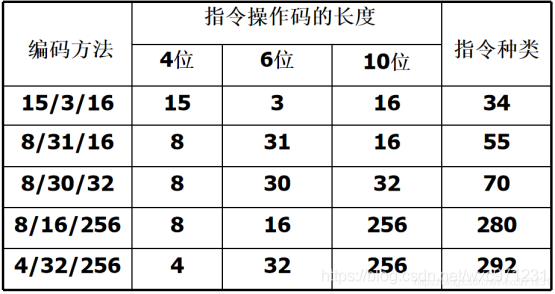
3. 设计操作码编码示例
-
设某指令系统指令字是16位,操作码从最高位开始,地址码都在最低位,每个地址码为6位。包含三类指令
- 二地址指令15条
- 一地址指令34条
- 其余为零地址指令
-
分析:
- 二地址指令格式:4位操作码 | 6位地址 | 6位地址
- 一地址指令:10位操作码 | 6位地址
- 零地址指令:16位操作码
-
编码设计:

5. 标志信息的生成与使用
(1)条件测试方式
-
在一些CPU设计中,
条件转移指令
通常根据
Condition Codes
(
条件码
/
CC
) 决定是否转移。如IA-32结构中的
Jcc
系列指令 -
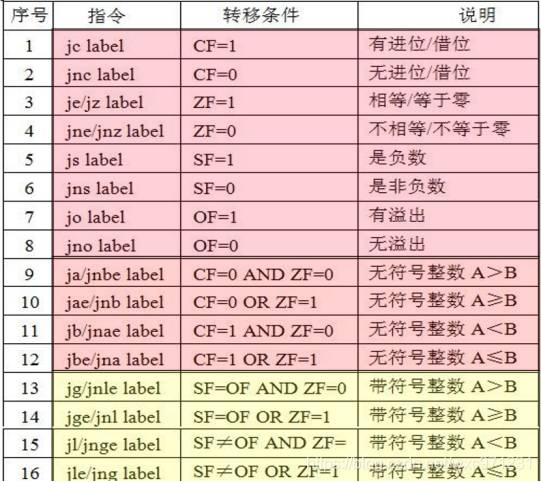
IA-32的
Jcc指
令示例,
可见条件码cc本质上是由一些标志位的逻辑运算结果决定的,也就是说:标志位经过逻辑运算,可以进行逻辑判断或溢出检测等
-
常见的标志位由以下四种,
对于带符号和无符号运算,标志生成方式有没有不同
,因为电路不知道是无符号数还是带符号整数!

-
通过
执行算术指令
或
显式地由比较和测试指令
来设置CC(即设置标志位),它们(尤其是第二类)往往配合跳转转移系列指令
Jcc
使用-
第一类:如IA-32中的
add
,
sub
等算术指令 -
第二类:如IA-32中的
cmp
,
test
等指令
-
第一类:如IA-32中的
-
更多关于IA-32中标志相关的内容,请参考:
IA-32汇编语言笔记(3)—— 简单传送、加减指令 & 标志寄存器
(2)标志寄存器
-
IA-32系列结构中使用了标志寄存器(程序状态字寄存器)
PSW
,这是一个16位的寄存器。 它反映了CPU运算的状态特征并且存放某些控制标志。8086使用了16位中的9位,包括6个状态标志位和3个控制标志位


(3)MIPS中没有标志位
-
MIPS架构和IA-32的一个大区别就是
MIPS没有标志位的概念,自然也没有标志寄存器PSW
-
MIPS架构中,
直接在ALU部件运算时生成转移发生、溢出发生等信号
,这些信号被传输到其他部件控制动作发生
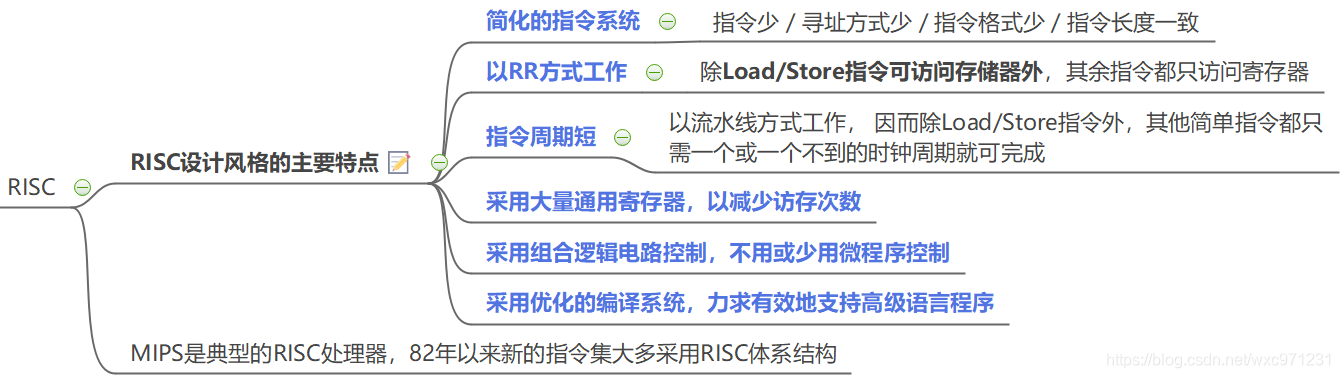
6. 指令设计风格
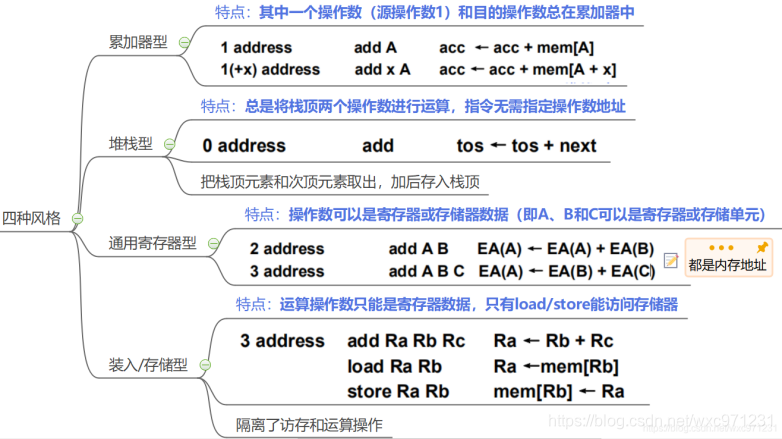
(1)按操作数位置指定风格
-
四种指令风格
-
指令风格比较

- 累加器型,因为所有运算都要用累加器,表达式复杂时,程序中移入移出累加器的指令增多
- 1975年开始,寄存器型指令集占主导地位。寄存器速度快,使用大量通用Reg减少访存;与堆栈型指令用到堆栈相比,编译高级语言中变量时,不用考虑顺序
-
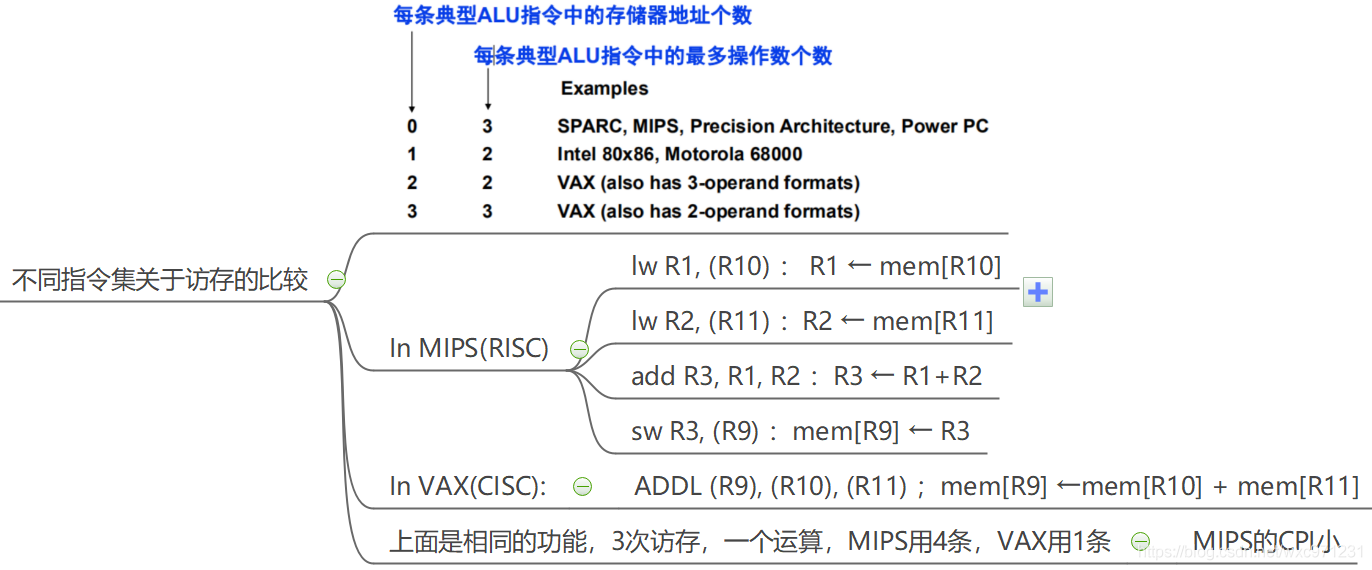
不同指令集关于访存的比较
(2)按指令格式的复杂度来分
1. 复杂指令集计算机CISC

2. 精简指令集计算机RISC