DataX的环境搭建以及简单测试
什么是DataX
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、 HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
(这是一个单机多任务的ETL工具)

下载地址:
http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
一、前置条件
JDK(1.8以上,推荐1.8)
Python(推荐Python2.6.X)
Apache Maven 3.x (Compile DataX)
查看自有版本是否符合要求(下面附上安装链接)
JDK版本查看
java -version
Python版本查看(通常虚拟机自带版本2.x)
python --version
Maven版本查看
mvn -v
安装链接
安装JDK:https://blog.csdn.net/qq_32786873/article/details/78749384
安装python:https://www.cnblogs.com/MWCloud/p/11354591.html
安装maven:https://www.howtoing.com/install-apache-maven-on-centos-7
二、开始安装
1.下载DataX安装包:https://github.com/alibaba/DataX/blob/master/userGuid.md
2.用Xftp将安装包传输至 usr/local 目录下
3.解压
tar -zxvf datax.tar.gz4.进入datax的bin目录下,自检脚本
cd /usr/local/datax/bin
python datax.py ../job/job.json出现以下界面,则表示DataX安装成功
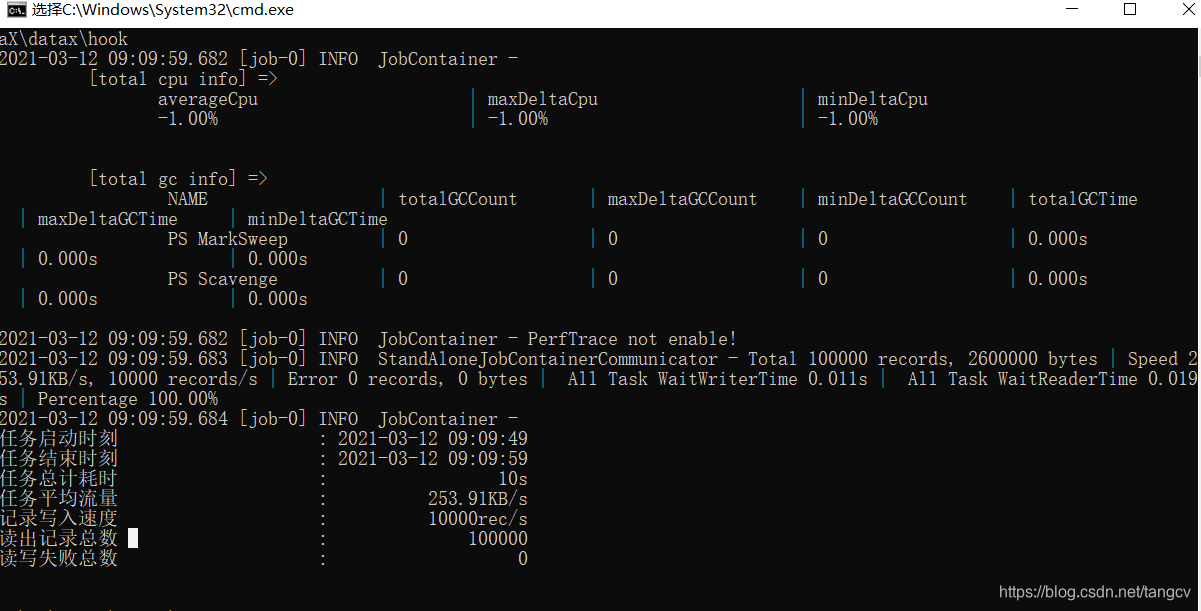
安装失败
第一个错误:命令提示符界面出现出现乱码。
解决方法:
可以在cmd中输入: CHCP 65001 (切换为UTP8编码-65001 (UTF-8)),然后进行后续操作。
第二个错误:print的问题
File "datax.py", line 114
print readerRef
^
SyntaxError: Missing parentheses in call to 'print'. Did you mean print(readerRef)?python版本错误,把高版本的python切换至2.6或2.7
2.7下载地址:
https://www.python.org/ftp/python/2.7/python-2.7.amd64.msi
第三个问题:连接mysql
2020-10-28 08:02:46.914 [job-0] WARN DBUtil - test connection of [jdbc:mysql://localhost:3306/ssm] failed, for Code:[DBUtilErrorCode-10], Description:[连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port或者向 DBA 寻求帮助(注意网络 环境).]. - 具体错误信息为:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server..
2020-10-28 08:02:46.918 [job-0] ERROR RetryUtil - Exception when calling callable, 异常Msg:DataX无法连接对应的数据库,可能原因是:1) 配置的ip/port/database/jdbc错误,无法连接。2) 配置的username/password错误,鉴权失败。请和DBA确认该数据库的 连接信息是否正确。
java.lang.Exception: DataX无法连接对应的数据库,可能原因是:1) 配置的ip/port/database/jdbc错误,无法连接。2) 配置的username/password错误,鉴权失败。请和DBA确认该数据库的连接信息是否正确。
at com.alibaba.datax.plugin.rdbms.util.DBUtil$2.call(DBUtil.java:71) ~[plugin-rdbms-util-0.0.1-SNAPSHOT.jar:na]
at com.alibaba.datax.plugin.rdbms.util.DBUtil$2.call(DBUtil.java:51) ~[plugin-rdbms-util-0.0.1-SNAPSHOT.jar:na]
at com.alibaba.datax.common.util.RetryUtil$Retry.call(RetryUtil.java:164) ~[datax-common-0.0.1-SNAPSHOT.jar:na]
at com.alibaba.datax.common.util.RetryUtil$Retry.doRetry(RetryUtil.java:111) ~[datax-common-0.0.1-SNAPSHOT.jar:na]
解决方法:
查看MySQL驱动包
把mysql-connector-java-5.1.34.jar 修改为
mysql-connector-java-8.0.18.jar
添加?serverTimezone=UTC
jdbc.url=jdbc:mysql://localhost:3306/ssm?serverTimezone=UTC
完美结果:
020-10-28 08:19:36.780 [job-0] INFO OriginalConfPretreatmentUtil - Available jdbcUrl:jdbc:mysql://localhost:3306/ssm?serverTimezone=UTC&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true.
2020-10-28 08:19:36.836 [job-0] INFO OriginalConfPretreatmentUtil - table:[menu] has columns:[id,name,pid].
2020-10-28 08:19:36.900 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2020-10-28 08:19:36.900 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do prepare work .
2020-10-28 08:19:36.902 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do prepare work .
2020-10-28 08:19:36.906 [job-0] INFO JobContainer - jobContainer starts to do split ...
2020-10-28 08:19:36.907 [job-0] INFO JobContainer - Job set Channel-Number to 3 channels.
2020-10-28 08:19:36.936 [job-0] INFO SingleTableSplitUtil - split pk [sql=SELECT MIN(id),MAX(id) FROM menu] is running...
第四个错误 mysql2mysql
首先也要更新驱动
2020-10-28 09:59:52.876 [job-0] ERROR RetryUtil - Exception when calling callable, 即将尝试执行第1次重试.本次重试计划等待[1000]ms,实际等待[1001]ms, 异常Msg:[Code:[DBUtilErrorCode-10], Description:[连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port或者向 DBA 寻求帮助(注意网络环境).]. - 具体错误信息为:java.sql.SQLException: No suitable driver found for ["jdbc:mysql://localhost:3306/ssm?serverTimezone=UTC&useUnicode=true&characterEncoding=gbk"]&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true]
把
"jdbcUrl": [
"jdbc:mysql://localhost:3306/ssm?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8"
]
修改为
"jdbcUrl": "jdbc:mysql://localhost:3306/ssm?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8"
测试:利用DataX同步数据
配置测试样例:下面我们配置一组 从mysql数据库到另一个mysql数据库。
配置测试样例:下面我们配置一组 从mysql数据库到另一个mysql数据库。
第一步创建作业的配置文件(json格式)
可以参考:
https://github.com/alibaba/DataX
自行配置
根据配置模板填写相关选项
根据模板配置json文件(mysql2mysql.json)如下:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","name"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://192.168.155.56:3306/test"],
"table": ["test"]
}
],
"username": "root",
"password": "123456",
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["id","name","age"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.155.58/test",
"table": ["YOUR_TABLE"]
}
],
"username": "root",
"password": "123456",
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
第二步、启动DataX
启动之前的数据库:
启动
cd {YOUR_DATAX_DIR_BIN}
python datax.py ../job/mysql2mysql.json
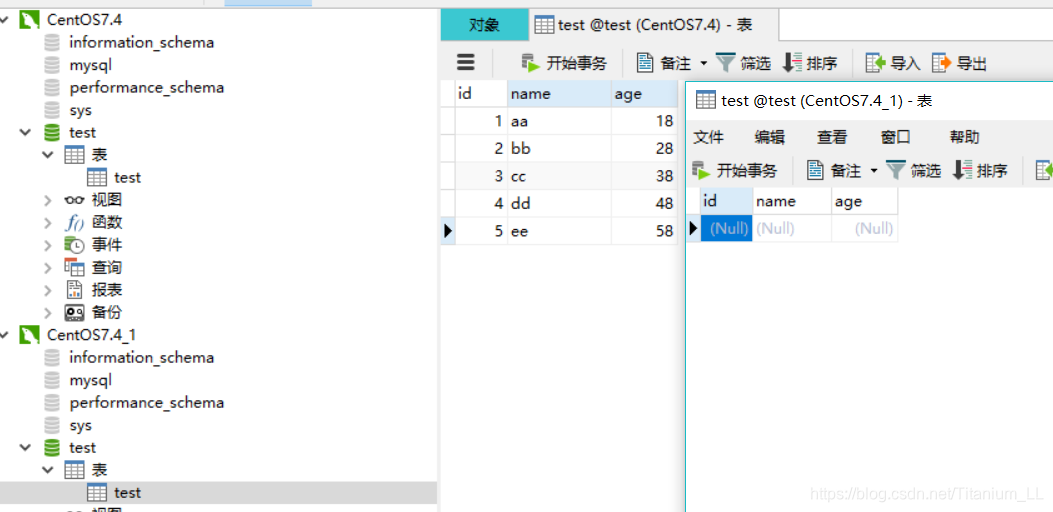
同步结束,显示日志如下:
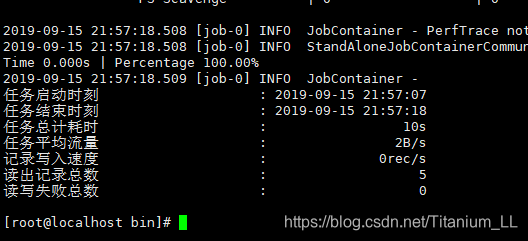
再来看一下我们的数据库:
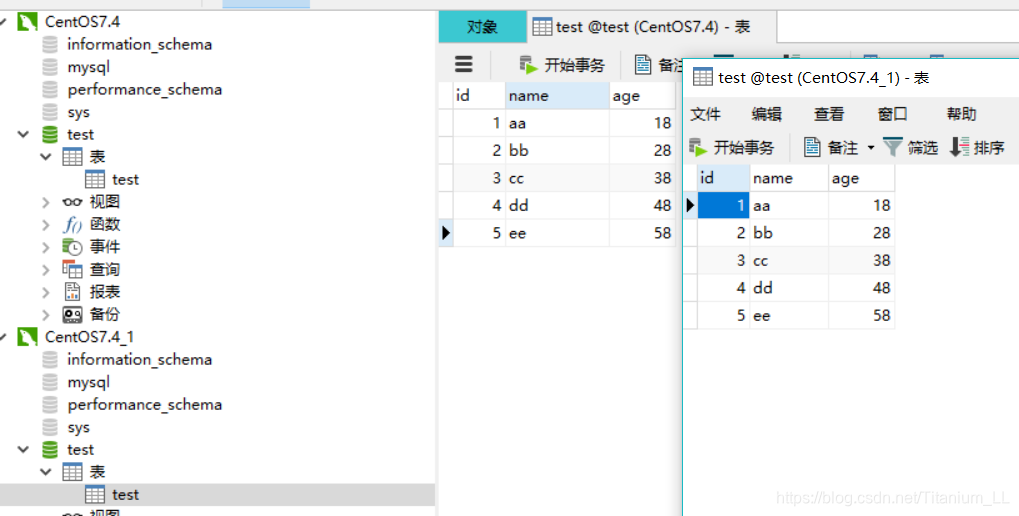
至此,mysql到mysql的数据传输已经完成。
一、设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
此前已经开源DataX1.0版本,此次介绍为阿里云开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。Github主页地址:
https://github.com/alibaba/DataX
二、DataX3.0框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
三. DataX3.0插件体系
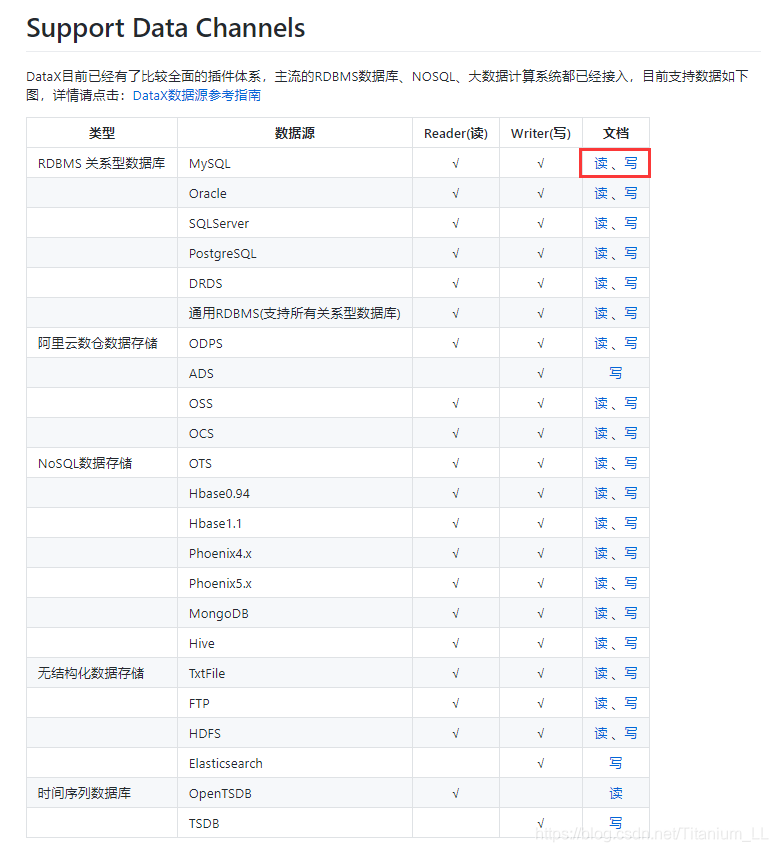
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:
DataX数据源参考指南

四、DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。


核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
五、DataX 3.0六大核心优势
可靠的数据质量监控
-
完美解决数据传输个别类型失真问题
DataX旧版对于部分数据类型(比如时间戳)传输一直存在毫秒阶段等数据失真情况,新版本DataX3.0已经做到支持所有的强数据类型,每一种插件都有自己的数据类型转换策略,让数据可以完整无损的传输到目的端。 -
提供作业全链路的流量、数据量运行时监控
DataX3.0运行过程中可以将作业本身状态、数据流量、数据速度、执行进度等信息进行全面的展示,让用户可以实时了解作业状态。并可在作业执行过程中智能判断源端和目的端的速度对比情况,给予用户更多性能排查信息。 -
提供脏数据探测
在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,为用户提供多种的脏数据处理模式,让用户准确把控数据质量大关!
丰富的数据转换功能
DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。详情请看DataX3的transformer详细介绍。
精准的速度控制
还在为同步过程对在线存储压力影响而担心吗?新版本DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在库可以承受的范围内达到最佳的同步速度。
"speed": {
"channel": 8, ----并发数限速(根据自己CPU合理控制并发数)
"byte": 524288, ----字节流限速(根据自己的磁盘和网络合理控制字节数)
"record": 10000 ----记录流限速(根据数据合理空行数)
}
强劲的同步性能
DataX3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。性能测试相关详情可以参照每单个数据源的详细介绍:
DataX数据源指南
健壮的容错机制
DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX3.0可以做到线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。
线程内部重试
DataX的核心插件都经过团队的全盘review,不同的网络交互方式都有不同的重试策略。
线程级别重试
目前DataX已经可以实现TaskFailover,针对于中间失败的Task,DataX框架可以做到整个Task级别的重新调度。
极简的使用体验
下载即可用,支持linux和windows,只需要按照模板填相应的参数即可
DataX3.0安装过程:
https://blog.csdn.net/u014646662/article/details/82748055
DataX3.0 Oracle导入Oracle:
https://blog.csdn.net/u014646662/article/details/82777966
DataX3.0 MySQL导入MySQL:
https://blog.csdn.net/u014646662/article/details/82778067
————————————————
参考资料来源:CSDN博主「yandao」 https://blog.csdn.net/yandao/article/details/109325035
参考资料来源:CSDN博主「Titanium_LL」 https://blog.csdn.net/Titanium_LL/article/details/100859499
参考资料来源:简书 香山上的麻雀 https://www.jianshu.com/p/f5f0dc99d5ab