一、背景
1.什么是缓存穿透:
一般的缓存系统,都是按照 key 去缓存查询,如果不存在对应的 value,就应该去后端系统查找(比如 DB)。如果 key 对应的 value 是一定不存在的,并且对该 key 并发请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
2.什么是缓存雪崩:
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如 DB)带来很大压力。
二、解决
1.如何避免缓存雪崩:
1.
1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该 key 对应的数据 insert 了之后清理缓存。
1.2:对一定不存在的 key 进行过滤。可以把所有的可能存在的 key 放到一个大的 Bitmap 中,查询时通过该 bitmap 过 滤。【感觉应该用的不多吧】
2.如何避免雪崩:
2.1:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个 key 只允许一个线程查询数据和 写缓存,其他线程等待。
2.2:不同的 key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
2.3:做二级缓存,A1 为原始缓存,A2 为拷贝缓存,A1 失效时,可以访问 A2,A1 缓存失效时间设置为短期,A2 设置 为长期(此点为补充)
三、介绍一个实际的案例以及解决方式
1.Redis缓存的使用,极大的提升了应用程序的性能和效率,特别是数据查询方面。但同时,它也带来了一些问题。其中,最要害的问题,就是数据的一致性问题,从严格意义上讲,这个问题无解。如果对数据的一致性要求很高,那么就不能使用缓存。
另外的一些典型问题就是,缓存穿透、缓存雪崩和缓存击穿。目前,业界也都有比较流行的解决方案。本篇文章,并不是要更加完美的解决这三个问题,也不是要颠覆业界流行的解决方案。而是,从实际代码操作,来演示这三个问题现象。之所以要这么做,是因为,仅仅看这些问题的学术解释,脑袋里很难有一个很形象的概念,有了实际的代码演示,可以加深对这些问题的理解和认识。
缓存穿透,是指查询一个数据库一定不存在的数据。正常的使用缓存流程大致是,数据查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存。
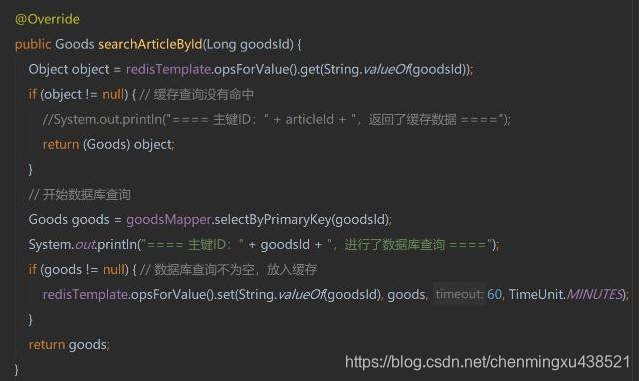
代码流程
参数传入对象主键ID根据key从缓存中获取对象如果对象不为空,直接返回如果对象为空,进行数据库查询如果从数据库查询出的对象不为空,则放入缓存(设定过期时间)想象一下这个情况,如果传入的参数为-1,会是怎么样?这个-1,就是一定不存在的对象。就会每次都去查询数据库,而每次查询都是空,每次又都不会进行缓存。假如有恶意攻击,就可以利用这个漏洞,对数据库造成压力,甚至压垮数据库。即便是采用UUID,也是很容易找到一个不存在的KEY,进行攻击。
小编在工作中,会采用缓存空值的方式,也就是【代码流程】中第5步,如果从数据库查询的对象为空,也放入缓存,只是设定的缓存过期时间较短,比如设置为60秒。
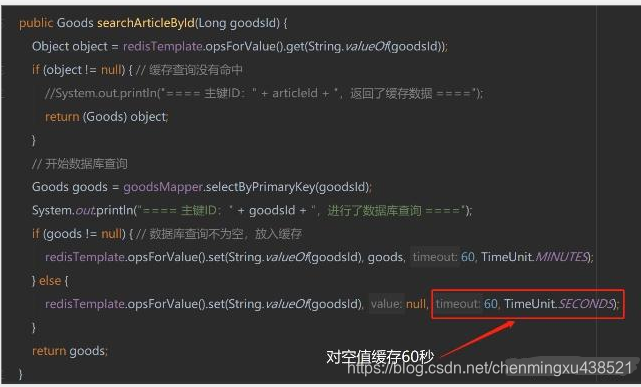
2.缓存雪崩,是指在某一个时间段,缓存集中过期失效。
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。
小编在做电商项目的时候,一般是采取不同分类商品,缓存不同周期。在同一分类中的商品,加上一个随机因子。这样能尽可能分散缓存过期时间,而且,热门类目的商品缓存时间长一些,冷门类目的商品缓存时间短一些,也能节省缓存服务的资源。
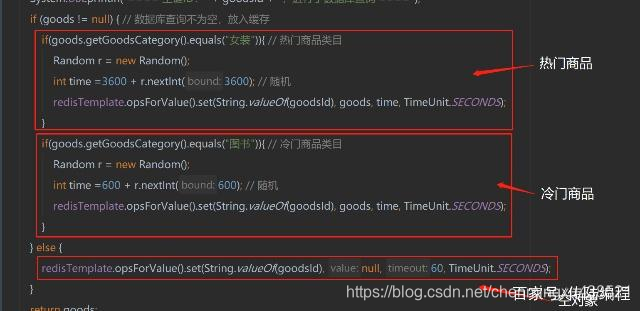
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,那么那个时候数据库能顶住压力,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
3.缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
四、结束