【从零开始制作 bt 下载器】一、了解 torrent 文件
写作背景
最先开始是朋友向我诉说使用某雷下载结果显示因为版权无法下载,找其他的下载器有次数限制,于是来询问我是否能自己制作一个 bt 下载器。
都问到门儿上来了,是男人就不能退缩。我答应下来,并开启这个专栏。让我们一点点解开 P2P 的面纱,制作一个属于自己的 bt 下载器吧!
因为能力有限,所以如果出现
用词不当
、
解释不通
等
情况,烦请各位大佬在评论区指出!
读取 torrent 文件
首先让我们来看看传说中的 torrent 文件中都有什么(随便找了个举例子,直接 ‘rb’ 读取),如下图所示。
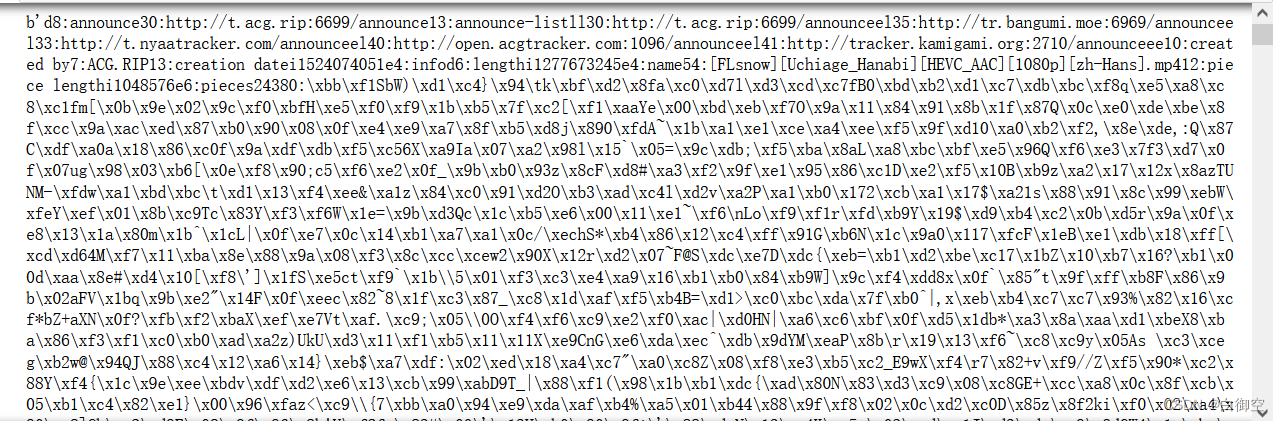
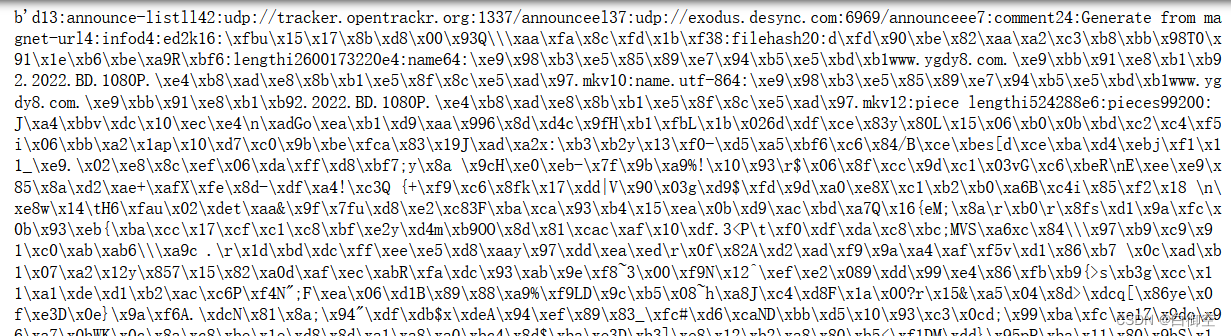
是不是黑压压一片,老眼昏花?,我就有这种感觉。
不过我们可以发现一些规律,文件的内容都是以
d
开头,后边数字,然后冒号,再一些字符之类的,这就是
bencode
的编码格式。
认识 bencode
bencode
编码是 bt 协议中用来进行信息描述的编码,包括四种数据类型,以 Python 数据类型作为参照来说就是
str
,
int
,
list
,
dict
。
-
str
,字符类型,格式是
【Length】:【String】
,就是这个字符串的长度,一个冒号,该字符串。我们就很容易读取字符串,如果碰到数字,后边跟了个冒号,那么就读取这个数字长度即为我们要的字符串。 -
int
,整数类型,格式是
i【integer】e
,就是以字符
i
开头,
e
结尾,中间是数字,而其中的数字即为所求。 -
list
,列表类型,格式类似于整数类型,和整数类型的差别就在于是以
l
开头,而其中的内容可以是字符串、整数、嵌套列表,可以在读取到
l
、判断为列表时对其中的内容进行递归,获取列表中的每一个元素。 -
dict
,字典类型,格式也类似于列表类型,只不过是以
d
开头,其中的内容就要以键值对的形式读,也就是先读到的元素作为键,后边一个元素作为值,然后再开启下一个键值对。
使用 Python 解析 torrent 文件
看过了
bencode
,是不是觉得很简单,那现在就用 Python 对 torrent 文件进行解析吧,看看里边都有什么内容。
倒是有现成的库
bencoder
,但我尝试后发现每个元素都是
bytes
类型(也有可能是我哪里没有设置导致的吧),我还是想将可以转化的都转化一下,所以最后决定自己写一个。
我的思路是:
- 函数接收两个参数,一个用来读取数据,一个表示当前数据的类型。
-
根据
当前数据的类型
初始化变量
data
。 -
每次读取一个字符,
-
如果是
i
、
l
、
d
就代表是需要递归处理的比较特殊的数据,递归时函数的第二个参数指定对应的类型。通过当前设置的类型判断操作,-
如果是
字符串
或者
整数
,就返回。 -
如果是
列表
就加入到初始化的
data
中。 -
如果是
字典
,需要先判断有没有设置
键
,没有的话就代表当前读取的数据是
键
,否则就是
值
。
-
如果是
-
如果是
数字
,则累积到字符串
length
中,这时有两种情况,一种是这个数字代表
字符串长度
,另一种就是
整数
。 -
如果是
冒号
,说明后面的数据是
字符串
或者
字节流
,就要读取上一步中设置的
length
长度的字符。 -
如果是
e
,就代表是第一步中所说的较为特殊类型的结尾符,就要分两种情况,一种是
整数
,需要先
eval
再返回,否则就直接返回。 - 注:判断为字符串后,会直接根据长度将整个字符串读取,所以不需要担心字符串数据中特定字符的影响。
-
如果是
直接上代码。
def tdecode(fread, dtype=None):
# 初始化变量
length = b''
if dtype in ['str', 'int']:
data = b''
elif dtype == 'list':
data = []
elif dtype == 'dict':
key = b''
data = {}
elif dtype is None:
pass
else:
raise ValueError(f'Input param `dtype` "{dtype}" is invalid, valuable: ["str", "int", "list", "dict"].')
# 对文件进行读取
while True:
# 每次读取一个字符
c = fread.read(1)
# 以特定字符作为起始的较为特殊的类型
d_list = {b'i': 'int', b'l': 'list', b'd': 'dict'}
if c in d_list or c == b':':
# 如果属于上述特殊类型,则进行递归,并获取递归结果
# 否则为字符串类型,直接读取 length 字节
current = tdecode(fread, d_list[c]) if c in d_list else fread.read(eval(length))
length = b''
# 将字节转为字符串,其余类型不变
# 也可能碰到 hash 值无法解码,直接存储字节流
try:
current = current.decode() if isinstance(current, bytes) else current
except:
pass
# 如果当前类型是字符串或者整数类型,直接返回
if dtype in ['str', 'int']:
return current if dtype == 'str' else eval(current)
# 列表类型直接加入列表
elif dtype == 'list':
data.append(current)
# 字典类型需要判断是否有键,没有的话就设置,有的话将键值对加入字典
elif dtype == 'dict':
if not key: key = current
else:
data[key] = current
key = b''
# 针对所有数据为一个大字典,如果变量 data 不存在则返回变量 current
else: return data if 'data' in locals().keys() else current
# 如果是数字 0-9 或者数字的负号,则记录到 length 变量中,可能代表字符串的长度,也可能代表整数类型
elif 48 <= ord(c) <= 57 or (c == b'-' and dtype == 'int'):
length += c
# 类型结尾符,整数类型就 eval 后返回,列表和字典直接返回
elif c == b'e':
if dtype == 'int': return eval(length)
else: return data
else:
pass
这个函数接受两个参数,
-
第一个就是使用
open
函数以
rb
模式打开的
_io.BufferedReader
对象,注意一定要是
rb
打开,因为其中存储的
hash
值无法解码,直接使用
r
读取会报错。 -
第二个就是当前要读取的元素的类型,初始的话
None
就好了。
P.S. 先开始我想的是构造一些变量对当前读取到的元素进行存储,四种类型都要存储,但因为有嵌套关系的存在,我放弃了直接拿同一变量存储很多元素,因为很多时候不知道会嵌套多少层,写起来比较麻烦,所以就写了个函数,利用函数递归来区分不同层次的元素。
解密 torrent 文件
我们这时候就可以比较方便地看看 torrent 文件中到底存储了什么数据。下面是开头那两个 torrent 文件解析后的结果。
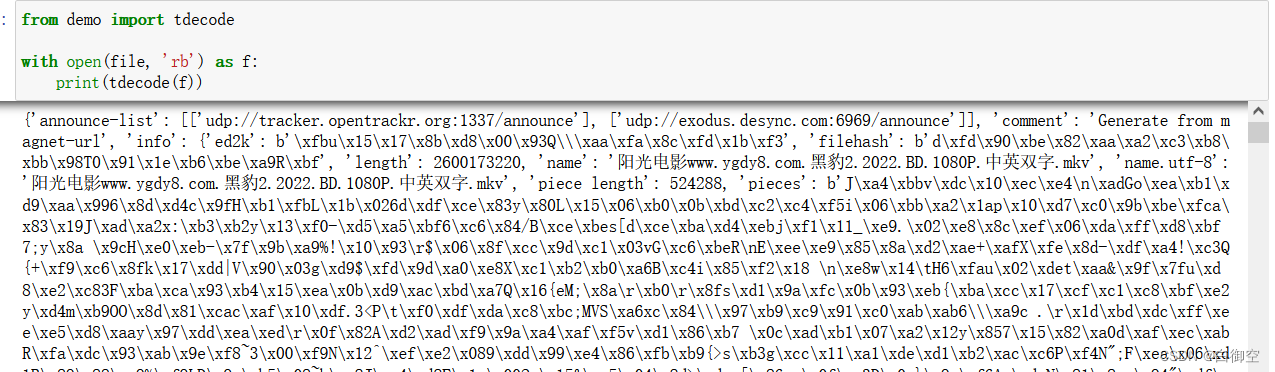
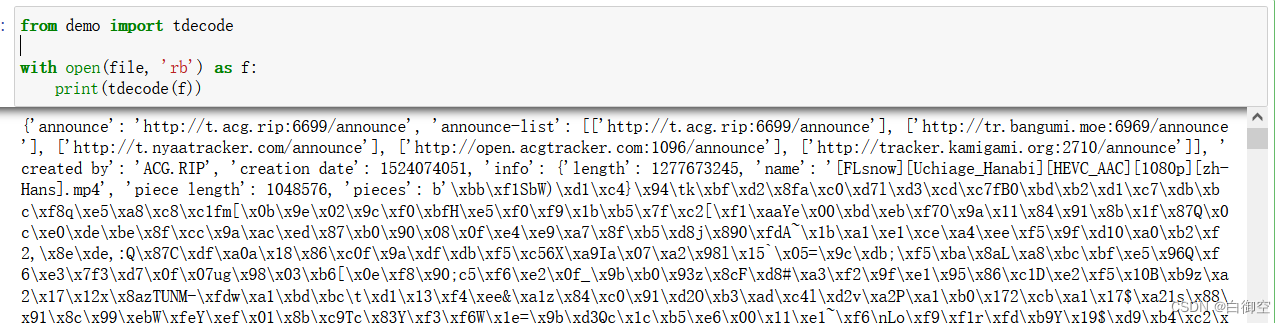
可以看到键有
announce-list
,
comment
,
info
等等,
info
又是一个字典,包含了一些信息,这样解码的工作就完成了。



可以看到,其实整个 torrent 文件的内容就是个大的字典。其中:
-
announce
的值是一个 Tracker 的 url,目前只需要知道 Tracker 是个用于文件分发的服务器即可。 -
announce-list
提供了一个列表,里边存储了一些备用的 Tracker url。 -
created by
显示了生成种子文件的 BT 客户端软件的信息。 -
creation date
指明了该 torrent 文件是什么时间创建的。 -
comment
是该文件的备注信息。 -
magnet
代表 MagNet 地址。 -
info
即为存储的可下载的文件的信息,如果是单个文件,如下图所示。

length
是要下载的文件的总字节数。
name
是要下载的文件的名称。
name.utf8
就是
utf-8
编码的文件名。
piece length
代表下载的块儿的大小,因为下载文件是一块儿一块儿下载的,每一块儿可能存储在不同的主机上,所以要指定每次下载的块儿的大小。
pieces
就是每个块儿的 hash 值。
private
好像是代表是否为私有资源,取值为
0
和
1
。(我没看协议规范,根据翻译和取值猜测,不对的话请大佬们指出)。如果包含多个文件,如下图所示。

这里就会有个
files
,存储的是所有文件的信息,是个
list
。
列表的每个元素都是一个
dict
,包含:
length
,一个整数,表明文件大小。
path
,是个列表,指出文件的路径,如果是包含在文件夹中,列表中会包含多个元素,形如
[【文件夹】, 【文件夹】, ……, 【文件名】]
。
这样就完成了了解 Torrent 文件的任务了。
结尾
有想要一起学习
python
的小伙伴可以
私信我
进群哦。
以上就是我要分享的内容,因为
学识尚浅
,
会有不足
,还
请各位大佬指正
。
有什么问题也可在评论区留言。
