一、任务需求
爬取网址之家的网站排行信息,共获取6个指标:

2张图片和4个文本字符串,观察发现每个网页共30个,一共需要爬取10页,并把图片存入PNG目录下,文本信息存入info.txt文件中,最后上传到linux上的Mysql数据库中.
二、实战代码
import requests
import os,sys
import shutil
from bs4 import BeautifulSoup
import pymysql
conn=pymysql.connect(
host='192.168.1.111',
user='root',
passwd='root',
db='test',
port=3306
)
cursor=conn.cursor()
#爬第一个页面
response = requests.get(url="https://top.chinaz.com/hangye/")
def get_resource_path(relative_path): # 利用此函数实现资源路径的定位
if getattr(sys, "frozen", False):
base_path = sys._MEIPASS # 获取临时资源
print(base_path)
else:
base_path = os.path.abspath(".") # 获取当前路径
return os.path.join(base_path, relative_path) # 绝对路径
if response.status_code == 200: #404和405
print("连接成功!")
# 设置返回源码的编码格式
response.encoding = "UTF-8"
# print(type(response.text))
html = BeautifulSoup(response.text,"html5lib")
ul=html.find("ul",attrs={"class":"listCentent"})#找唯一的父节点再找子节点,或者找出后得到列表取第一个
li_list = ul.find_all("li")
i = 0
PNG1=get_resource_path('png1') #判断是否有PNG目录存在,存在则删除再创建,避免使用的时候报错
if os.path.exists(PNG1):
shutil.rmtree(PNG1)
png1 = os.mkdir(PNG1)
PNG2=get_resource_path('png2') #判断是否有PNG目录存在,存在则删除再创建,避免使用的时候报错
if os.path.exists(PNG2):
shutil.rmtree(PNG2)
png2 = os.mkdir(PNG2)
PNG3=get_resource_path('png3') #判断是否有PNG目录存在,存在则删除再创建,避免使用的时候报错
if os.path.exists(PNG3):
shutil.rmtree(PNG3)
png3 = os.mkdir(PNG3)
for li in li_list:
i += 1
img_src1 = 'https:'+li.find_all("img")[0]["src"]
response_child1 = requests.get(img_src1)
fileWriter = open(get_resource_path(os.path.join("png1", "{}.png".format(i))), "wb")
fileWriter.write(response_child1.content)
img_src2 = 'https://top.chinaz.com'+li.find_all("img")[1]["src"]
response_child2 = requests.get(img_src2)
fileWriter1 = open(get_resource_path(os.path.join("png2", "{}.png".format(i))), "wb")
fileWriter1.write(response_child2.content)
img_src3 = 'https://top.chinaz.com'+li.find_all("img")[2]["src"]
response_child3 = requests.get(img_src3)
fileWriter2 = open(get_resource_path(os.path.join("png3", "{}.png".format(i))), "wb")
fileWriter2.write(response_child3.content)
name=li.find("a",attrs={"class":"pr10 fz14"}).text
web=li.find("span",attrs={"class":"col-gray"}).text
p_list=li.find_all("p",attrs={"class":"RtCData"})
AleaxaRank=p_list[0].find('a').text
ReChainNum=p_list[3].find('a').text
text=open('info.txt','a',encoding='utf-8')
if i==1:
text.write('网站名'+' '+'网址'+' '+'Aleaxa排名'+' '+'反链数'+'\n')
else:
text.write(name+' '+web+' '+AleaxaRank+' '+ReChainNum+'\n')
text.close()
cursor.execute(
#"create table webs(name varchar(50),web varchar(50),AleaxaRank varchar(50),ReChainNum varchar(50),img_src1 varchar(200),img_src2 varchar(200))"
"insert into webs(name,web,AleaxaRank,ReChainNum,img_src1,img_src2)values(%s,%s,%s,%s,%s,%s)",
(str(name),str(web),str(AleaxaRank),str(ReChainNum),str(img_src1),str(img_src2))
)
conn.commit()#提交
#爬剩下的9个页面
for j in range(0,9):
div_a_list=html.find("div",attrs={"class":"ListPageWrap"})
a_list=div_a_list.find_all('a')
website='https://top.chinaz.com'+a_list[j+2]["href"]
response = requests.get(url=website,timeout=(3,7)) #防止[WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。
if response.status_code == 200: #404和405
print("连接成功!")
# 设置返回源码的编码格式
response.encoding = "UTF-8"
# print(type(response.text))
html = BeautifulSoup(response.text,"html5lib")
ul=html.find("ul",attrs={"class":"listCentent"})#找唯一的父节点再找子节点,或者找出后得到列表取第一个
li_list = ul.find_all("li")
for li in li_list:
i += 1
img_src1 = 'https:'+li.find_all("img")[0]["src"]
response_child1 = requests.get(img_src1)
fileWriter = open(get_resource_path(os.path.join("png1", "{}.png".format(i))), "wb")
fileWriter.write(response_child1.content)
img_src2 = 'https://top.chinaz.com'+li.find_all("img")[1]["src"]
response_child2 = requests.get(img_src2)
fileWriter1 = open(get_resource_path(os.path.join("png2", "{}.png".format(i))), "wb")
fileWriter1.write(response_child2.content)
img_src3 = 'https://top.chinaz.com'+li.find_all("img")[2]["src"]
response_child3 = requests.get(img_src3)
fileWriter2 = open(get_resource_path(os.path.join("png3", "{}.png".format(i))), "wb")
fileWriter2.write(response_child3.content)
name=li.find("a",attrs={"class":"pr10 fz14"}).text
web=li.find("span",attrs={"class":"col-gray"}).text
p_list=li.find_all("p",attrs={"class":"RtCData"})
AleaxaRank=p_list[0].find('a').text
ReChainNum=p_list[3].find('a').text
text=open('info.txt','a',encoding='utf-8')
if i==31:
text.write('网站名'+' '+'网址'+' '+'Aleaxa排名'+' '+'反链数'+'\n')
else:
text.write(name+' '+web+' '+AleaxaRank+' '+ReChainNum+'\n')
text.close()
cursor.execute(
"insert into webs(name,web,AleaxaRank,ReChainNum,img_src1,img_src2)values(%s,%s,%s,%s,%s,%s)",
(str(name),str(web),str(AleaxaRank),str(ReChainNum),str(img_src1),str(img_src2))
)
conn.commit()#提交
else:
print("连接失败!")
三、步骤分析
<ul class="listCentent"> ##唯一listCentent,获取后得到列表
<li class="clearfix LCliTheOne"> #第一个li
<div class="leftImg">
<a name="obj_1" target="_blank" id="obj_1" href="/site_www.baidu.com.html">
<img src="//topimg.chinaz.net/WebSiteimages/baiducom/969e383d-19b6-4081-b933-a38ca415dd8a_2017_s.png" onerror="this.src='//topimg.chinaz.net/WebSiteimages/nothing.png'" alt="">
</a> ##从leftImg里面的img获取src图片1
</div>
<div class="CentTxt">
<h3 class="rightTxtHead">
<a href="/site_www.baidu.com.html" title="百度" target="_blank" class="pr10 fz14">百度</a> ##从rightTxtHead中的pr10 fz14获取百度
<span class="col-gray">www.baidu.com</span> ####从rightTxtHead中的col-gray获取www.baidu.com
</h3>
div class="RtCPart clearfix">
<p class="RtCData">
<span>Alexa周排名:</span>
<a target="_blank" href="//alexa.chinaz.com/www.baidu.com">4</a> ##从RtCData里的a中获得4
</p>
<p class="RtCData">
<span>百度权重为:</span> ##从RtCData中的a的img获得/images/baidu/9.gif
<a target="_blank" href="//rank.chinaz.com/www.baidu.com"><img src="/images/baidu/9.gif"></a>
</p> ##同理
<p class="RtCData"><span>PR:</span><a target="_blank" href="//pr.chinaz.com/?PRAddress=www.baidu.com"><img src="/images/ranks/Rank_9.gif"></a></p>
<p class="RtCData"><span>反链数:</span><a target="_blank" href="//outlink.chinaz.com/?h=www.baidu.com">345762</a></p>
</div>
<p class="RtCInfo">网站简介:百度,全球大的中文搜索引擎、大的中文网站。2000年1月创立于北京中关村。...</p>
</div>
<div class="RtCRateWrap">
<div class="RtCRateCent">
<strong class="col-red02">1</strong>
<span>得分:4999</span>
</div>
</div>
</li>
Ⅰ、获取第一个网页的图片和文本:
观察发现,所需要获取的数据都在ul的 class=“listCentent” 标签下,且该class名是唯一的,所以可以直接用find定位到该ul,然后通过find_all定位到集合了30个网站排名的li列表;
用成员循环遍历该列表,在每次的循环中,先通过定位img获取得到图片数量为3的列表,根据下标顺序指定0和2即得到了目标数据;
然后对于网站名,它的a标签对应的class名pr10 fz14也是唯一的,所以可以通过find直接定位到;
剩下的三个文本信息都在p标签下,且class名都为RtCData,所以直接find_all定位得到列表,然后再获得目标数据.
Ⅱ、文件目录的创建和写入:
对于PNG目录,需要在爬虫启动前先用文件路径定位获取当前路径然后创建该目录,图片的写入则需要加上文件的名,利用计数器和format格式对文件名进行命名写入,每次程序启动时都需要判断PNG目录是否存在,存在则删除,提高程序的可执行性.
对于文本文件的创建直接open就行,需要使用追加模式,不然每次循环都会覆盖前一次的写入,删除也可以提前进行判断.
Ⅲ、mysql的连接和写入
conn=pymysql.connect(
host=‘192.168.1.111’, #linux对应的ip地址
user=‘root’, #mysql的用户名
passwd=‘root’, #mysql的登入密码
db=‘test’, #mysql的数据库
port=3306 #mysql的端号
)
cursor=conn.cursor() #创建游标
cursor.execute(
“insert into webs(name,web,AleaxaRank,ReChainNum,img_src1,img_src2)values(%s,%s,%s,%s,%s,%s)”,
(str(name),str(web),str(AleaxaRank),str(ReChainNum),str(img_src1),str(img_src2))
) #insert的前提是你mysql里面有webs这个表了,没有的话需要创建create table webs(name varchar(50),web varchar(50),AleaxaRank varchar(50),ReChainNum varchar(50),img_src1 varchar(200),img_src2 varchar(200)),这里为什么建议你在mysql上执行呢,因为每次程序执行时你已经存在了该库就报错了,当然你也可以先判断,或者用完第一次就注释掉.
conn.commit()#提交
Ⅳ、网站翻页和网址不全的解决办法
<div class="ListPageWrap">
<a href="/hangye/index.html" >
< </a><a class="Pagecurt"href="/hangye/index.html">1</a>
<a href="/hangye/index_2.html">2</a>
<a href="/hangye/index_3.html">3</a>
<a href="/hangye/index_4.html">4</a>
<a href="/hangye/index_5.html">5</a>
<a href="/hangye/index_6.html">6</a>
<a href="/hangye/index_7.html">7</a>
<a href="/hangye/index_8.html">8</a>
<span>...</span>
<a href="/hangye/index_1872.html">1872</a>
<a href="/hangye/index_2.html"> > </a>
</div>
找到翻页对应的html代码,发现div对应的class”ListPageWrap”名是唯一的,所以可以直接find定位得到,然后再find_all得到a的列表集合,利用for循环得到每个网页的网址.
你也可以观察发现,该网页的跳转都是由规律的都是index_后面的数字+1,所以你可以用for循环和format格式来拼接字符串得到网站.
对于获取href或者src网址不全的问题,我们可以通过观察如果它是有规律的,那就进行拼接字符串,如果没有规律,只能通过模拟点击的方式来实现.
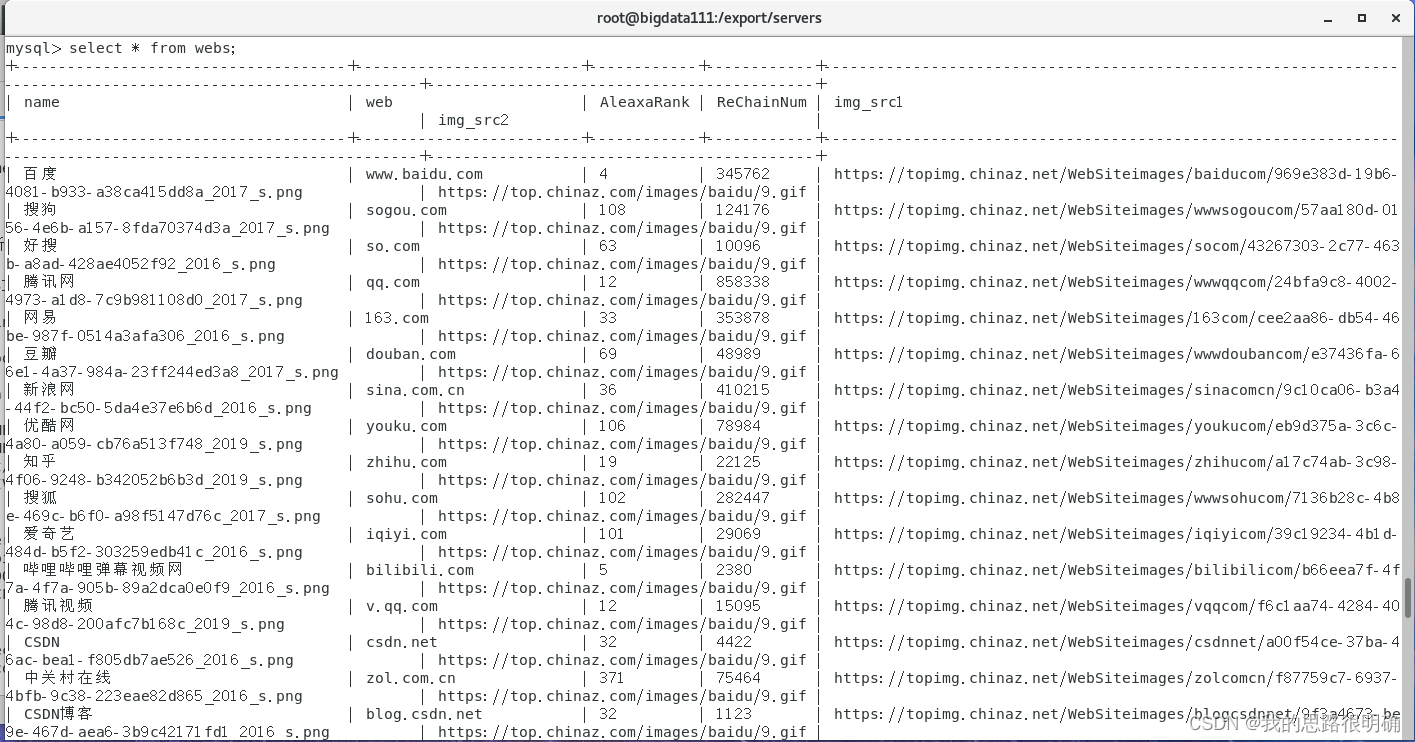
四、Mysql查看结果
mysql -uroot -proot
use test;
select * from webs;