相关博客:
Python 爬虫入门(二)—— IP代理使用:
http://www.cnblogs.com/hearzeus/p/5157016.html
python爬虫如何抓取代理服务器:
https://segmentfault.com/n/1330000005070016
# The proxy address and port:
proxy_info = { 'host' : 'proxy.myisp.com',
'port' : 3128
}
# We create a handler for the proxy
proxy_support = urllib2.ProxyHandler({"http" : "http://%(host)s:%(port)d" % proxy_info})
# We create an opener which uses this handler:
opener = urllib2.build_opener(proxy_support)
# Then we install this opener as the default opener for urllib2:
urllib2.install_opener(opener)
# Now we can send our HTTP request:
htmlpage = urllib2.urlopen("http://sebsauvage.net/").read(200000)
#如果代理需要验证
proxy_info = { 'host' : 'proxy.myisp.com',
'port' : 3128,
'user' : 'John Doe',
'pass' : 'mysecret007'
}
proxy_support = urllib2.ProxyHandler({"http" : "http://%(user)s:%(pass)s@%(host)s:%(port)d" % proxy_info})
opener = urllib2.build_opener(proxy_support)
urllib2.install_opener(opener)
htmlpage = urllib2.urlopen("http://sebsauvage.net/").read(200000)
#该代码片段来自于: http://www.sharejs.com/codes/python/226
下面以
*
国内高匿代理IP
*网站为实例,该网站提供代理服务器,但是正常爬去(IP,Port)只能爬取275条左右,本例利用前期爬去的275条代理服务器对网站进行继续的爬取:
#encoding=utf8
import urllib2
import BeautifulSoup
import random
from multiprocessing.dummy import Pool
def proxys():
proxy_cont=open("proxy_avi.txt").read()
##proxy_avi是经过测试可用的代理服务器
proxy_list=proxy_cont.split('\n')
return proxy_list
def crawl_ip(page):
print page
User_Agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0'
header = {}
header['User-Agent'] = User_Agent
for proxy in proxys():
proxy={"http":proxy}
proxy_support = urllib2.ProxyHandler(proxy) # 注册代理
# opener = urllib2.build_opener(proxy_support,urllib2.HTTPHandler(debuglevel=1)) ##构建open
opener = urllib2.build_opener(proxy_support)
urllib2.install_opener(opener)
url = 'http://www.xicidaili.com/nn/' + str(page)
req = urllib2.Request(url, headers=header)
try:
response = urllib2.urlopen(req, None,5)
soup = BeautifulSoup.BeautifulSoup(response)
ips = soup.findAll('tr')
except Exception as e:
continue
with open("proxy.txt",'a+') as f:
for x in range(1,len(ips)):
ip = ips[x]
tds = ip.findAll("td")
ip_temp = tds[1].contents[0]+"\t"+tds[2].contents[0]+"\n"
# print ip_temp
# print tds[2].contents[0]+"\t"+tds[3].contents[0]
f.write(ip_temp)
print "final"
break
if __name__=="__main__":
pagelist=range(298,1011)
pool=Pool(8)
pool.map(crawl_ip,pagelist)
pool.close()
pool.join()
文本样式:
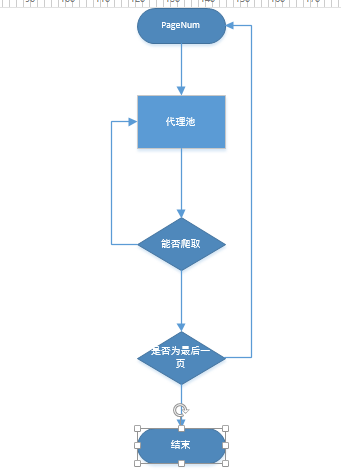
具体流程:
版权声明:本文为weiyudang11原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。