1. 前言
如果你对CoroutineContext不了解,本文值得你细细品读,如果一遍看不懂,不妨多读几遍。写作该文的过程也是我对CoroutineContext理解加深的过程。CoroutineContext是协程的基础,值得投入学习
Android开发者对Context都不陌生。在Android系统中,Context可谓神通广大,它可以获取应用资源,可以获取系统资源,可以启动Activity。Context有几个大名鼎鼎的子类,Activity、Application、Service,它们都是应用中非常重要的组件。
协程中也有个类似的概念,CoroutineContext。它是协程中的上下文,通过它我们可以控制协程在哪个线程中执行,可以设置协程的名字,可以用它来捕获协程抛出的异常等。
我们知道,通过CoroutineScope.launch方法可以启动一个协程。该方法第一个参数的类型就是CoroutineContext。默认值是EmptyCoroutineContext单例对象。

在开始讲解CoroutineContext之前我们来看一段协程中经常会遇到的代码

刚开始学协程的时候,我们经常会和Dispatchers.Main、Job、CoroutineName、CoroutineExceptionHandler打交道,它们都是CoroutineContext的子类。我们也很容易单独理解它们,Dispatchers.Main指把协程分发到主线程执行,Job可以管理协程的生命周期,CoroutineName可以设置协程的名字,CoroutineExceptionHandler可以捕获协程的异常。但是
+
操作符对大部分的Java开发者甚至Kotlin开发者而言会感觉到新鲜又难懂,在协程中CoroutineContext
+
到底是什么意思?
其实+操作符就是把两个CoroutineContext合并成一个链表,后文会详细讲解
2. CoroutineContext类图一览
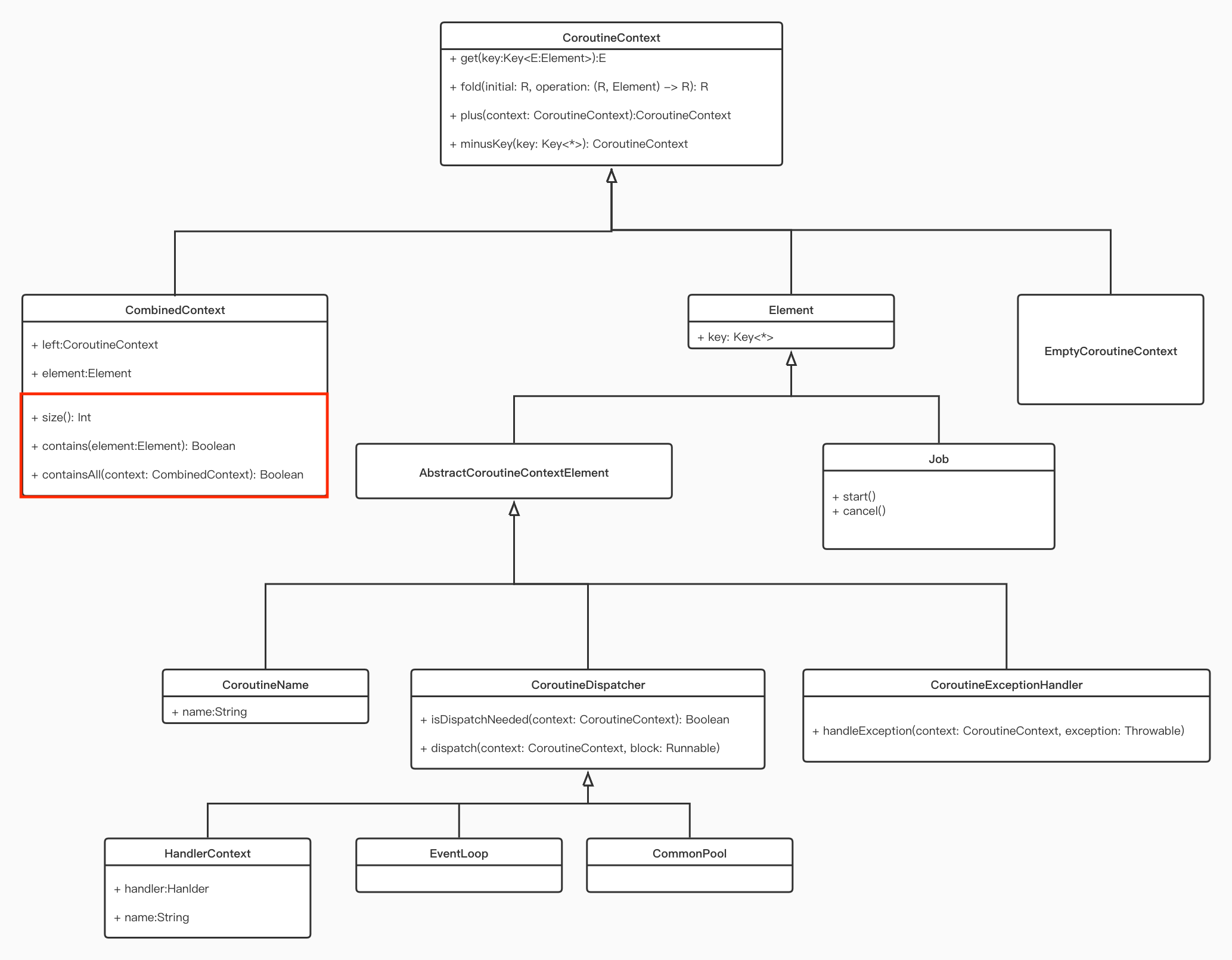
根据类图结构我们可以把它分成四个层级:
- CoroutineContext 协程中所有上下文相关类的父接口。
- CombinedContext、Element、EmptyCoroutineContext。它们是CoroutineContext的直接子类。
- AbstractCoroutineContextElement、Job。这两个是Element的直接子类。
-
CoroutineName、CoroutineExceptionHandler、CoroutineDispatcher
(包含Dispatchers.Main和Dispatchers.Default)
。它们是AbstractCoroutineContextElement的直接子类。
图中红框处,CombinedContext定义了size()和contains()方法,这与集合操作很像,CombinedContext是CoroutineContext对象的集合,而Element和EmptyCoroutineContext却没有定义这些方法,真正实现了集合操作的协程上下文只有CombinedContext,后文会详细讲解
3. CoroutineContext接口
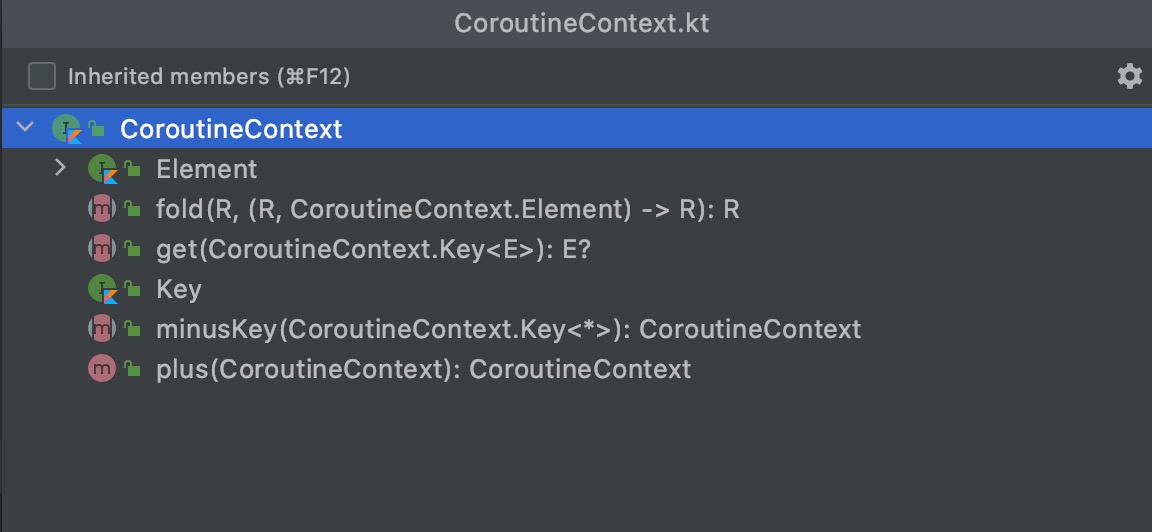
CoroutineContext源码如下:

首先
我们看下官方注释,我将它的作用归纳为:
Persistent context for the coroutine. It is an indexed set of [Element] instances. An indexed set is a mix between a set and a map. Every element in this set has a unique [Key].
- CoroutineContext是协程的上下文。
- CoroutineContext是element的set集合,没有重复类型的element对象。
- 集合中的每个element都有唯一的Key,Key可以用来检索元素。
相信大多数的人看到这样的解释时,都会心生疑惑,既然是set类型为啥不直接用HashSet来保存Element。CoroutineContext的实现原理又是什么呢?原因是考虑到协程嵌套,用链表实现更好。
接着
我们来看下该接口定义的几个方法
4. Key接口

Key是一个接口定义在CoroutineContext中的一个接口,作为接口它没有声明任何的方法,那么其实它没有任何真正有用的意义,它只是用来检索。我们先来看下,协程库中是如何使用Key接口的。

通过观察协程官方库中的例子,我们发现Element的子类都必须重写Key这个属性,而且Key的泛型类型必须和类名相同。以CoroutineName为例,Key是一个伴生对象,同时Key的泛型类型也是CoroutineName。
为了方便理解,
我仿照写了MyElement类,如下:

通过对比kt类和反编译的java类我们看到
Key就是一个静态变量,而且它的实现类,其实啥也没干。它的作用与HashMap中的Key类似:
- 实现key-value功能,为插入和删除提供检索功能
- Key是static静态变量,全局唯一,为Element提供唯一性保障
Kotlin语法糖
coroutineContext.get(CoroutineName.Key)
coroutineContext.get(CoroutineName)
coroutineContext[CoroutineName]
coroutineContext[CoroutineName.Key]
写法是等价的
4. CoroutineContext.get方法
源码(整理在一起,下同)

使用方式

讲解
通过Key检索Element。返回值只能是Element或者null,链表节点中的元素值。
- Element get方法:只要Key与当前Element的Key匹配上了,返回该Element否则返回null。
- CombinedContext get方法:遍历链表,查询与Key相等的Element,如果没找到返回null。
5. CoroutineContext.plus方法
源码

使用方式

讲解
将两个CoroutineContext组合成一个CoroutineContext,如果是两个类型相同的Element会返回一个新的Element。如果是两个不同类型的Element会返回一个CombinedContext。如果是多个不同类型的Element会返回一条CombinedContext链表。
我将上述算法总结成了5种场景,不过在介绍这5种场景前,我们先讲解CombinedContext的数据结构。
6. CombinedContext分析

因为CombinedContext是CoroutineContext的子类,left也是CoroutineContext类型的,所以它的数据结构是链表。
我们经常用next来表示链表的下一个节点。那么为什么这里取名叫left呢?我甚至怀疑写这段代码的是个左撇子。真正的原因是,协程可以启动子协程,子协程又可以启动孙协程。父协程在左边,子协程在右边

嵌套启动协程

越是外层的协程的Context越在左边,大概示意图如下
(真实并非如此,比这更复杂)

链表的两个知识点在此都有体现。CoroutineContext.plus方法中使用的是头插法。CombinedContext的toString方法采用的是链表倒序打印法。
7. 五种plus场景
根据plus源码,我总结出会覆盖到五种场景。

- plus EmptyCoroutineContext
- plus 相同类型的Element
- plus方法的调用方没有Dispatcher相关的Element
- plus方法的调用方只有Dispatcher相关的Element
- plus方法的调用方是包含Dispatcher相关Element的链表
结果如下:
-
Dispatchers.Main + EmptyCoroutineContext
结果:
Dispatchers.Main
。 -
CoroutineName("c1") + CoroutineName("c2")
结果:
CoroutineName("c2")
。相同类型的直接替换掉。 -
CoroutineName("c1") + Job()
结果:
CoroutineName("c1") <- Job
。头插法被plus的(
Job
)放在链表头部 -
Dispatchers.Main + Job()
结果:
Job <- Dispatchers.Main
。虽然是头插法,但是ContinuationInterceptor必须在链表头部。 -
Dispatchers.Main + Job() + CoroutineName("c5")
结果:
Job <- CoroutineName("c5") <- Dispatchers.Main
。Dispatchers.Main在链表头部,其它的采用头插法。
如果不考虑Dispatchers.Main的情况。我们可以把
+
用
<-
代替。
CoroutineName("c1") + Job()
等价于
CoroutineName("c1") <- Job
8. CoroutineContext的minusKey方法
源码

讲解
- Element minusKey方法:如果Key与当前element的Key相等,返回EmptyCoroutineContext,否则相当于没减成功,返回当前element
- CombinedContext minusKey方法:删除链表中符合条件的节点,分三种情况。
三种情况以下面链表为例
Job <- CoroutineName(“c5”) <-Dispatchers.Main
-
没找到节点:minusKey(MyElement)。在Job节点处走newLeft === left分支,依此类推,在CoroutineName处走同样的分支,在Dispatchers.Main处走同样的分支。
-
节点在尾部:minusKey(Job)。在CoroutineName(“c5”)节点走newLeft === EmptyCoroutineContext分支,依此往头部递归
-
节点不在尾部:minusKey(CoroutineName)。在Dispatchers.Main节点处走else分支
9. 总结
学习CoroutineContext首先要搞清楚各类之间的继承关系,其次,CombinedContext各具体Element的集合,它的数据结构是链表,如果读者对链表增删改查操作熟悉的话,那么很容易就能搞懂CoroutineContext原理,否则想要搞懂CoroutineContext那简直如盲人摸象。
记得关注“字节小站”公众号哟~