全文字数 2954 字,预计耗时 8 min
在上周的【洞见症结】技术文章分享中,文章全面的介绍了DMDSC节点故障无法加入集群的解决思路。本文作为姊妹篇,将分享达梦数据资深技术工程师在重大项目实施过程中,对带DataWatch的三节点DMDSC集群
「备库分离后无法恢复主备关系」
的分析解决思路。
本文包含丰富案例及配图,希望能够对各位DMer有所启发,大家有任何疑问,欢迎在文章底部留言讨论。

DMDSC 集群作为一种共享存储集群,具备高可用、高性能、负载均衡等企业级特性;DM数据守护(DataWatch)作为一种数据库级的热备方案,也是数据库异地容灾的首选解决方案。本文主要记录了在带 DataWatch的三节点DMDSC集群运维过程中遇到的典型问题的处理过程。
环境介绍
CPU架构:X86_64
操作系统:银河麒麟v10
数据库版本:DM8
集群环境:三节点DMDSC集群为主库,带一个实时备库
备库分离后无法恢复主备关系
在压测过程中,DMDSC主库到备库的
实时归档
状态变为了
INVALID
,DMDSC主库可继续提供服务,但备库已被分离,不再应用日志,且无法通过attach的方式重新加入主备集群。
同步原理
正常的压测过程中,备库会被自动分离吗?
在弄清楚这个问题之前,我们需要对数据守护的实现原理和机制进行深入研究。
达梦数据守护环境主要用到两种归档类型:实时归档和即时归档。当前测试环境的归档类型为
实时归档+高性能模式
。
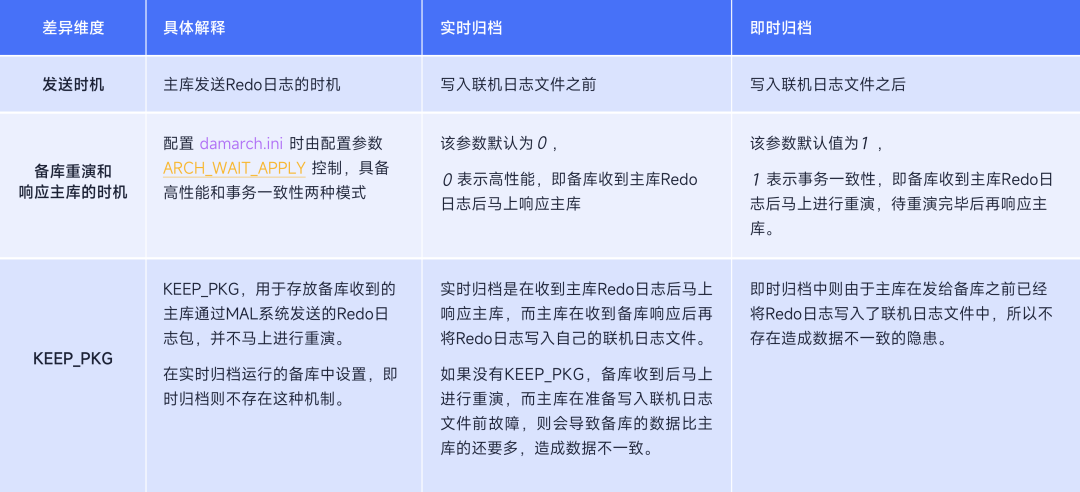
1)实时归档(REALTIME)
主备环境中,主库在Redo日志写入联机日志文件之前,先通过MAL系统把自己的Redo日志发送给备库,等待备库响应后,再写入自己的联机日志文件。
2)即时归档(TIMELY)
主备环境中,主库在Redo日志写入联机日志文件之后,再通过MAL系统把自己的Redo日志发送给备库。
3)实时归档和即时归档对比
实时归档进行重演的时机主要有:
1)备库收到新的RLOG_PKG,会将当前保存的 KEEP_PKG日志重演,并将新收到的RLOG_PKG再次放入KEEP_PKG中。
2)主库会定时将
FILE_LSN
(已写入联机日志文件的日志包的最大LSN)等信息发送到备库,当主库
FILE_LSN
等于备库
SLSN
(备库明确可重演的最大 LSN 值) 时,表明主库已经将KEEP_PKG对应的 Redo日志写入联机日志文件中,此时备库会启动KEEP_PKG的日志重演。
3)备库切换为新主库,在监视器执行 SWITCHOVER或TAKEOVER命令,或者确认监视器通知备库自动接管时,备库会在切换为
PRIMARY
模式之前,启动KEEP_PKG的日志重演。
下面通过一张图对该原理和实际应用场景进行一个总结
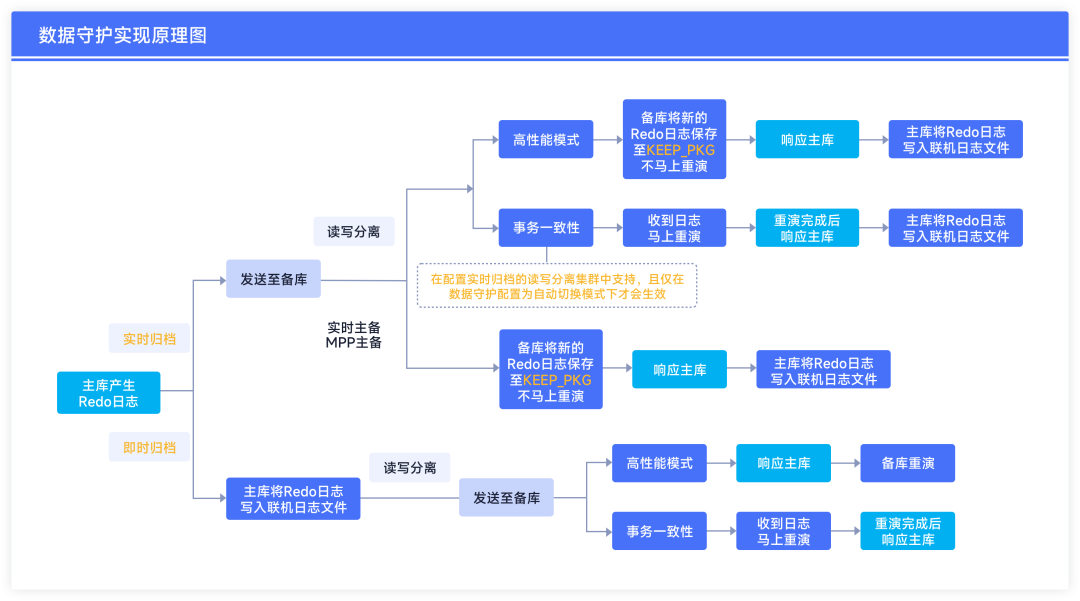
在发生故障的环境中,使用的是
实时归档+高性能模式
的组合,在该配置下,
主库的Redo日志将在写入联机日志之前就发送给了备库,备库收到后即刻响应主库,并不马上进行重演
。
问题分析
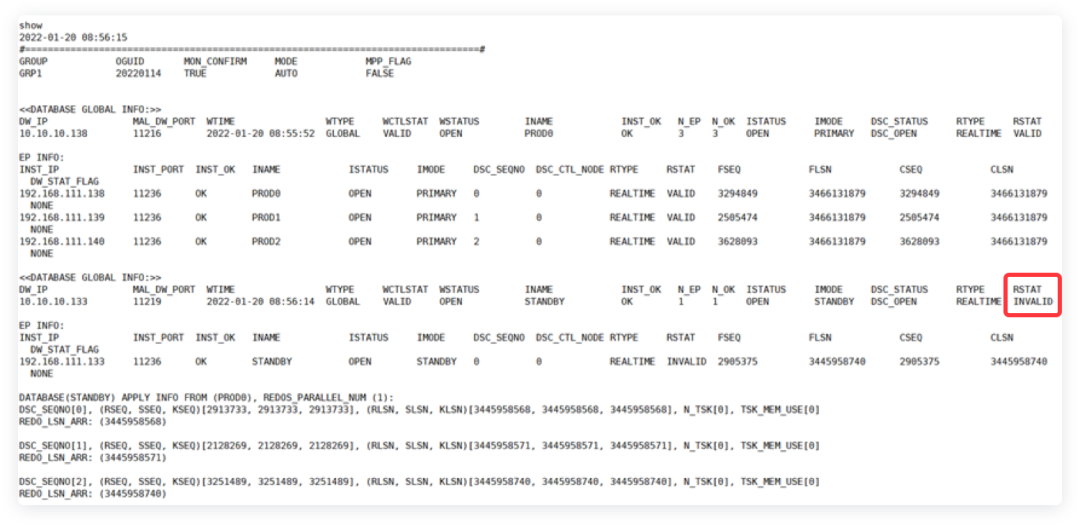
压测完毕后,监视器发现备库
RSTAT
状态变为了
INVALID。
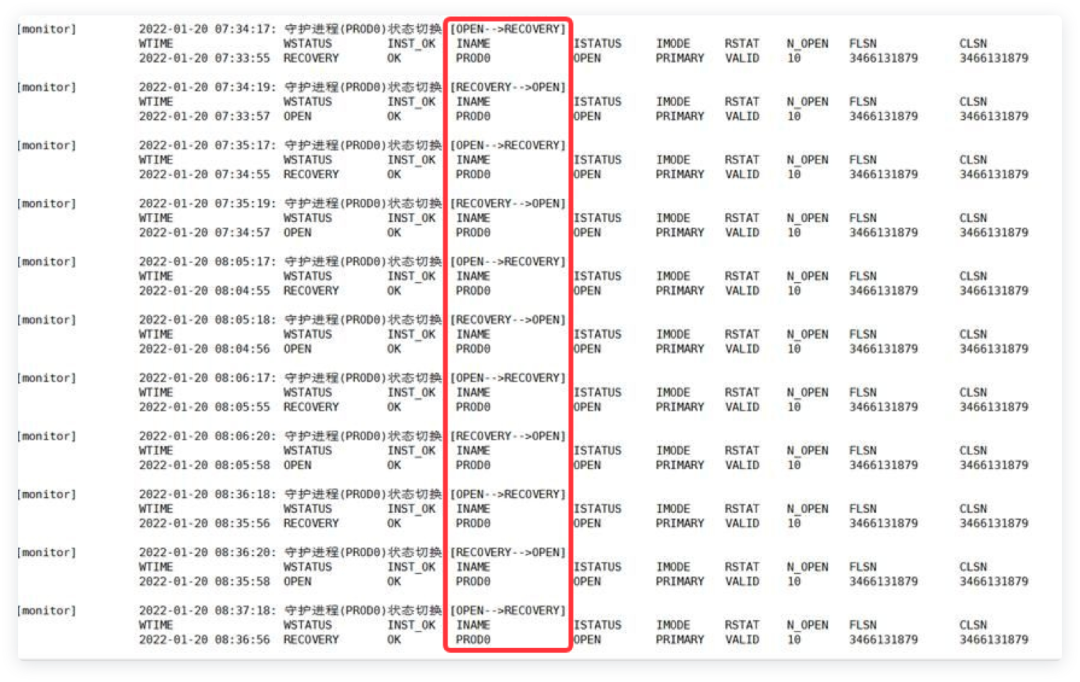
一直在自动进行OPEN>RECOVERY、RECOVERY>OPEN动作,但是实际上
备库并没有应用日志。
step 1:
查询主、备库中各自保存的FLSN号,发现并不一致,数据在中途停止了同步,主库直接将备库分离了。查询DMDSC集群三个节点的当前FLSN:
select * from v$rlog;
查询结果显示主库三个节点的FLSN分别为
3464530623、3464530626、3464530632
。
step 2:
查询备库上已应用的LSN:
SELECT P_DB_MAGIC, N_EP, PKG_SEQ_ARR, APPLY_LSN_ARR from V$RAPPLY_LSN_INFO;
查询结果显示备库应用的主库3个节点的LSN号分别为
3445958568、3445958571、3445958740
,均小于上述对应节点的FLSN号。

step 3:
此时尝试attach备库,发现虽然能成功执行,但备库并没有继续进行重演,备库归档状态仍为
INVALID
,集群主备关系依然没有恢复正常。

step 4:
此时查询主备库的归档日志。
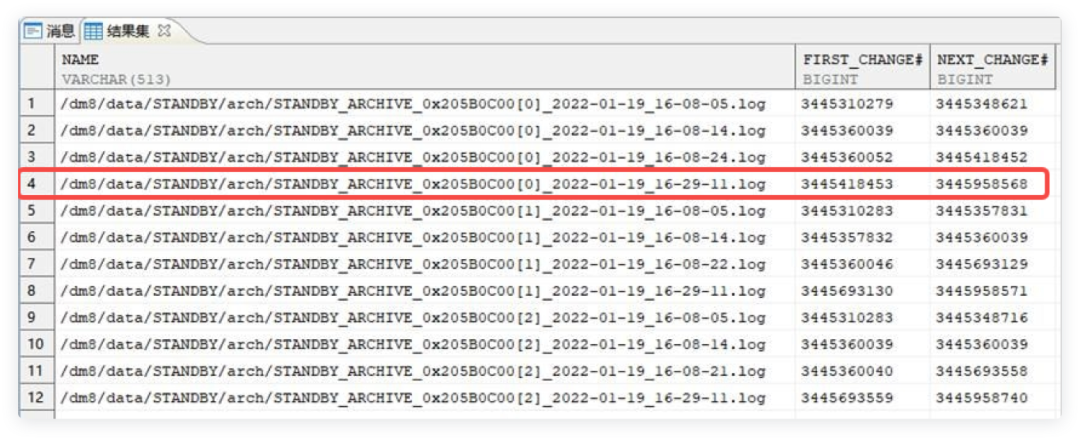
select name,first_change#,next_change# from V$ARCHIVED_LOG;
如下图所示,备库上已应用的来自节点1的日志最大LSN为
3445958568。
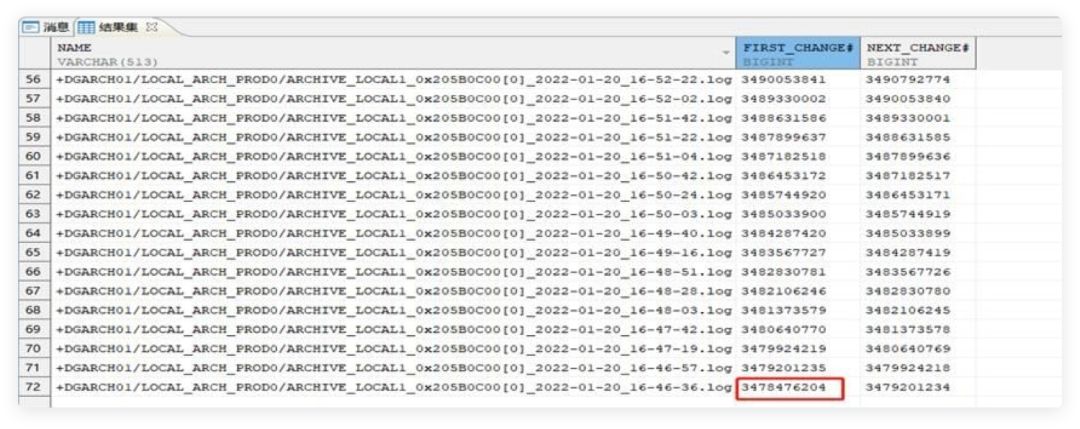
而主库节点1的本地归档日志最小的LSN为
3478476204
,比
3445958568
还大。
分析上述现象产生的原因可能为:
备库在收到LSN为
3445958568
日志的时候,主库的归档日志大小已经达到了
dmarch.ini
中配置的
ARCH_SPACE_LIMIT
上限,该参数当前配置值为
30720
。
当超过上限时,系统会自动删除最早生成的归档日志文件,删掉的这部分归档还没来得及发送到备库上,主库就已经将其删除,故备库的归档状态被设置成了
INVALID
。
而由于备库的归档日志缺失也不能符合恢复的条件,从而在DMMONITOR发起Recovery流程时,归档日志发送失败,备库无法正常重演进行数据的恢复,两边数据无法达到一致的状态。
监视器中执行如下代码:
show arch send info grp1.standby执行结果如下图所示,
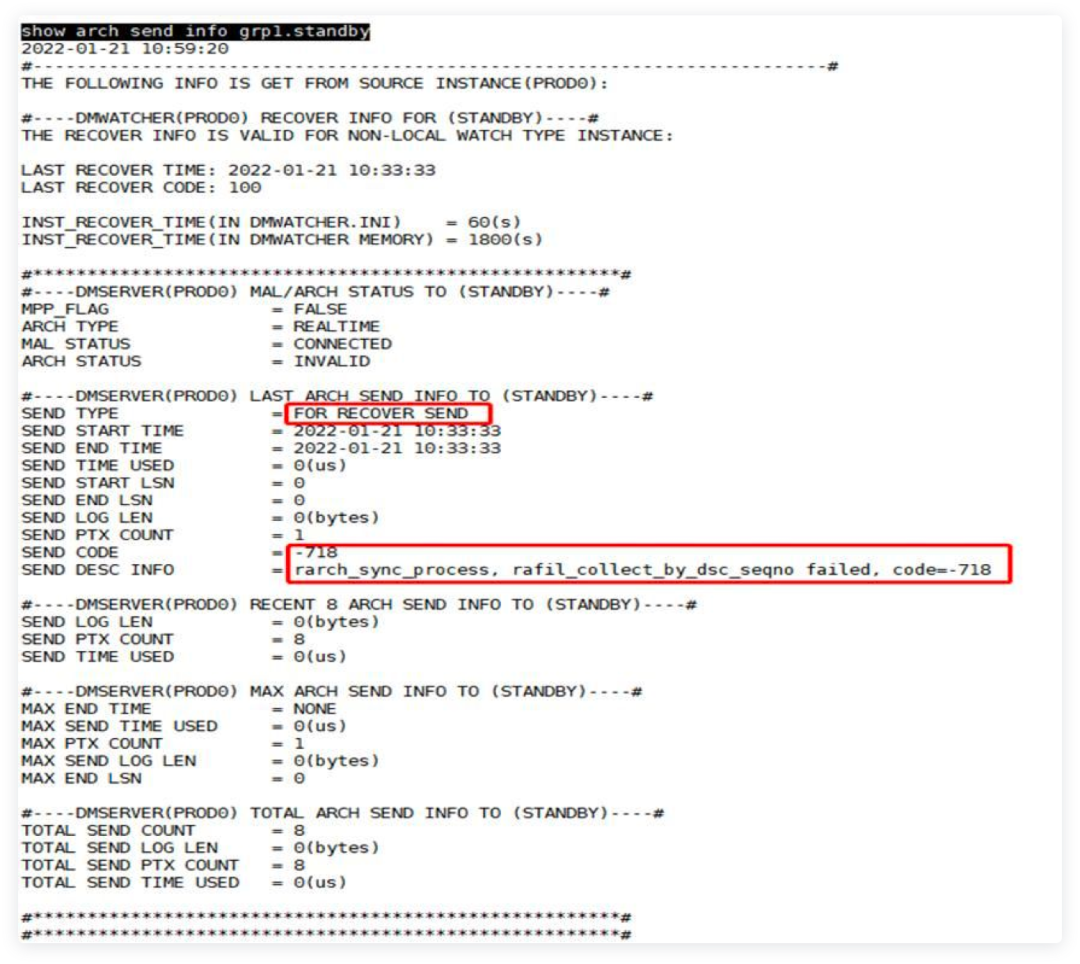
根据DM8数据守护与读写分离集群手册了解到:
1)FOR RECOVER SEND
:表示主库的守护进程发起的Recovery流程中的归档日志发送
2)SEND CODE
:主库到指定备库的日志发送结果, Code 小于 0 表示发送失败,等于 0 表示发送成功,等于 100 表示实际未发送。
综上所述,导致压测后备库
RSTAT
状态变为了
INVALID
且备库也不符合恢复条件的原因可能有:
1).
备库重演日志速度较慢,导致APPLY任务队列有大量的待应用的重做日志堆积
,如果队列有上限,达到上限后,主库是否会停止发送或者减慢发送日志。另外,备库收到新的日志后,由于队列满导致需要等待,无法响应主库,主库收不到响应超过一定时间,就把备库设置为了
INVALID
。
2).
主库本地归档日志文件累积大小超限
。当备库应用日志的速度小于主库产生日志的速度,主库产生的日志还未来得及发送给备库供备库使用时,已经由于到达空间上限而被清理,导致备库上日志缺失,备库丢失部分数据,应用日志过程中产生了中断,从而无法与主库保持数据一致。
解决办法
重新搭建备库,根据服务器实际存储空间和业务压力(每小时或者每天产生的日志量),合理评估并设置归档日志文件累积大小限制参数
ARCH_SPACE_LIMIT
。
我在该场景下将这里调整为了
512000
。后面在相同环境和配置下进行同样的压测,整个过程中没有再次发生备库被分离的现象。
总 结
主备环境搭建时,归档配置文件
dmarch.ini
中的参数
ARCH_SPACE_LIMIT
,
应根据实际存储空间和主库产生日志的速度进行合理的设置,太小则会导致主备关系异常。

在两期【洞见症结】栏目中,我们分享了「DSC节点故障无法加入集群」和「备库分离后无法恢复主备关系」故障的排查解决过程,希望以上分享能帮助各位DMer切实解决问题,如对文中的内容有任何疑问,或者想了解达梦相关产品,欢迎在文章底部留言和讨论?