1.为什么对数据进行分区?
对数据库进行分区可以极大的降低系统响应延迟同时提高数据吞吐量。具体来说,分区有以下几个好处:分区使得大型表更易于管理。对数据子集的维护操作也更加高效,因为这些操作只针对需要的数据而不是整个表。一个好的分区策略将通过只读取满足查询所需的相关数据来减少要扫描的数据量。当所有的数据都在同一个分区上,对数据库的查询,计算,以及其它操作都会被限制在磁盘访问IO这个瓶颈上。
分区使得系统可以充分利用所有资源。一个良好的分区方案搭配并行计算,分布式计算就可以充分利用所有节点来完成通常要在一个节点上完成的任务。 当一个任务可以拆分成几个分散的子任务,每个子任务访问不同的分区,就可以达到提升效率的目的。
分区增加了系统的可用性。由于分区的副本通常是存放在不同的物理节点的。所以一旦某个分区不可用,系统依然可以调用其它副本分区来保证作业的正常运转。
2.分区方式
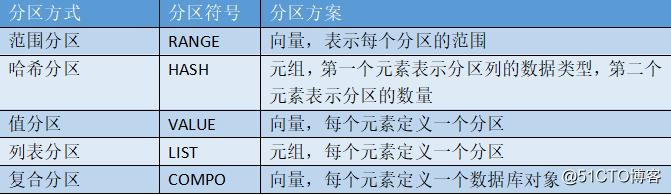
DolphinDB database支持多种分区方式: 范围分区(RANGE),哈希分区(HASH),值分区(VALUE),列表分区(LIST),复合分区(COMPO)。范围分区每个区间创建一个分区,是最常用的也是推荐的一种分区方式。可以把数值在一个区间内的所有记录放置到一个分区。
哈希分区利用哈希函数对分区列操作,方便建立指定数量的分区。
值分区每个值创建一个分区,例如股票交易日期,股票交易月。
列表分区是根据用户枚举的列表来进行分区,比值分区更加灵活。
复合分区适用于数据量特别大而且查询经常涉及两个或以上的分区列。每个分区选择都可以采用区间,值或列表分区。例如按股票交易日期进行值分区, 同时按股票代码进行范围分区。
我们可以使用database函数创建数据库。
语法:database(directory, [partitionType], [partitionScheme], [locations])
参数
directory:数据库保存的目录。DolphinDB有三种类型的数据库,分别是内存数据库、磁盘上的数据库和分布式文件系统上的数据库。创建内存数据库,directory为空;创建本地数据库,directory应该是本地文件系统目录;创建分布式文件系统上的数据库,directory应该以“dfs://”开头。本教程以创建Windows本地数据库为例。
partitionType:分区方式,有5种方式: 范围分区(RANGE),哈希分区(HASH),值分区(VALUE),列表分区(LIST),复合分区(COMPO)。
partitionScheme:分区方案。各种分区方式对应的分区方案如下:
locations:指定每个分区所在的节点位置。如果是分布式文件系统的数据库或者复合分区(COMPO)类型的数据库,不能使用locations参数。
2.1 范围分区
范围分区是由分区向量决定。分区向量表示区间,包含起始值,不包含结尾值。
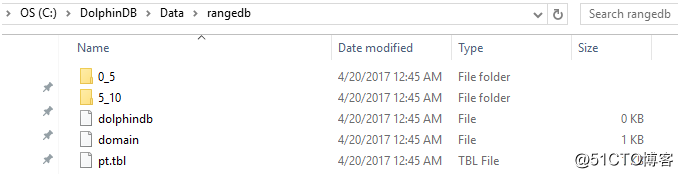
在下面的例子中,数据库db有两个分区:[0,5)和[5,10)。使用函数append!在数据库db中保存表t为分区表pt,并使用ID作为分区列。n=1000000
ID=rand(10, n)
x=rand(1.0, n)
t=table(ID, x)
db=database(“dfs://rangedb”, RANGE, 0 5 10)
pt = db.createPartitionedTable(t, `pt, `ID)
pt.append!(t);
pt=loadTable(db,`pt)
select count(x) from pt
2.2 哈希分区
哈希分区对分区列使用哈希函数以产生分区。哈希分区是产生指定数量的分区的一个简便方法。但是要注意,哈希分区不能保证分区的大小一致,尤其当分区列的值的分布存在偏态的时候。此外,若要查找分区列上一个连续区域的数据时,哈希分区的效率比区域分区或值分区要低。
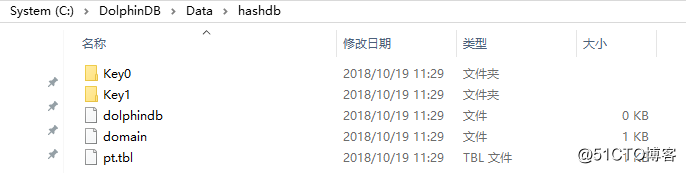
在下面的例子中,数据库db有两个分区。使用函数append!在数据库db中保存表t为分区表pt,并使用ID作为分区列。n=1000000
ID=rand(10, n)
x=rand(1.0, n)
t=table(ID, x)
db=database(“dfs://hashdb”, HASH, [INT, 2])
pt = db.createPartitionedTable(t, `pt, `ID)
pt.append!(t);
pt=loadTable(db,`pt)
select count(x) from pt
2.3 值分区
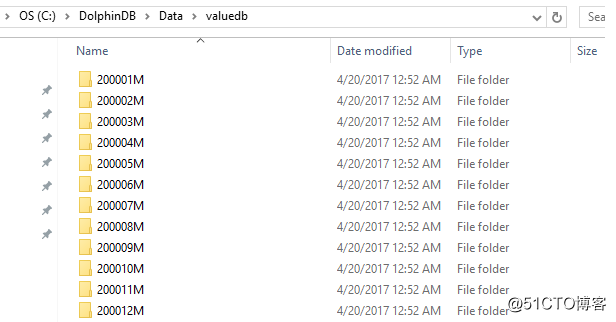
值分区用一个值代表一个分区。下面的例子定义了204个分区。每个分区表示2000年1月到2016年12月之间的一个月。n=1000000
month=take(2000.01M..2016.12M, n)
x=rand(1.0, n)
t=table(month, x)
db=database(“dfs://valuedb”, VALUE, 2000.01M..2016.12M)
pt = db.createPartitionedTable(t, `pt, `month)
pt.append!(t)
pt=loadTable(db,`pt)
select count(x) from pt
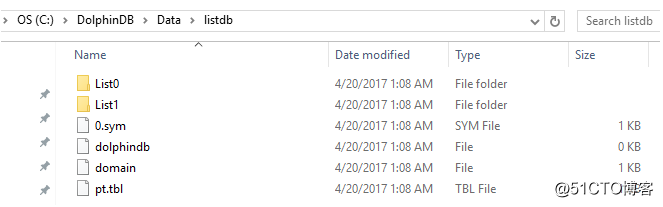
2.4 列表分区
在列表(LIST)分区中,我们用一个包含多个元素的列表代表一个分区。下面的例子有两个分区,第一个分区包含3个股票代码,第二个分区包含2个股票代码。n=1000000
ticker = rand(`MSFT`GOOG`FB`ORCL`IBM,n);
x=rand(1.0, n)
t=table(ticker, x)
db=database(“dfs://listdb”, LIST, [`IBM`ORCL`MSFT, `GOOG`FB])
pt = db.createPartitionedTable(t, `pt, `ticker)
pt.append!(t)
pt=loadTable(db,`pt)
select count(x) from pt
2.5 组合分区
组合(COMPO)分区可以定义2或3个分区列。每列可以独立采用范围(RANGE),值(VALUE)或列表(LIST)分区。组合分区的多个列在逻辑上是并列的,不存在从属关系或优先级关系。n=1000000
ID=rand(100, n)
dates=2017.08.07..2017.08.11
date=rand(dates, n)
x=rand(10.0, n)
t=table(ID, date, x)
dbDate = database(, VALUE, 2017.08.07..2017.08.11)
dbID=database(, RANGE, 0 50 100)
db = database(“dfs://compoDB”, COMPO, [dbDate, dbID])
pt = db.createPartitionedTable(t, `pt, `date`ID)
pt.append!(t)
pt=loadTable(db,`pt)
select count(x) from pt
上面的例子创建了5个值分区。
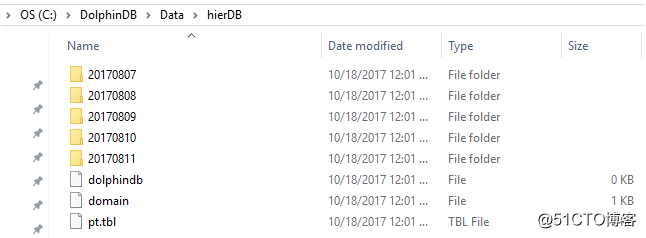
在20170807这个分区,有2个范围分区。

DolphinDB分区数据库教程(二)将会介绍DolphinDB分区原则以及特殊的分区方案。