从mysql到elasticsearch建立搜索——处理多表关联和频繁变化的数据
增量数据方案 maxwell -> kafka -> spring data (kafka + elasticsearch) -> elasticsearch
maxwell 简介
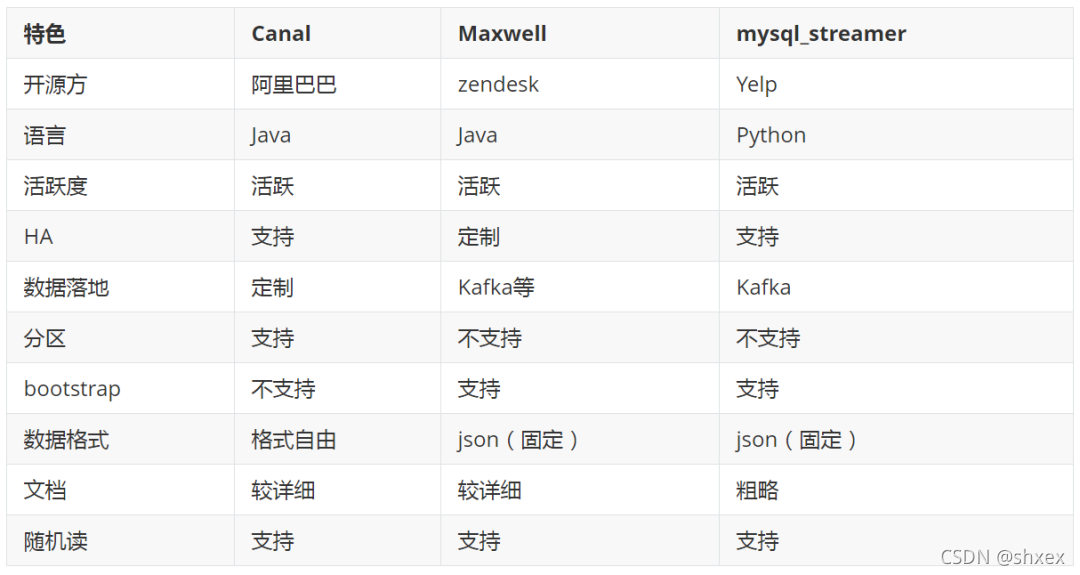
- 该工具伪装成mysql的从库达到监听数据库日志的效果,后转成json数据发动到消费端,主要关注json的database、table、type(增删改)、data、old 字段。
- 支持命令启动存量数据同步,命令指定一个独立的maxwell来执行同步工作,原理是执行select * form table 语句。根据社区文章显示,旧版本代码中存在order by id 和 sleep(1),进行流量控制,速度大概在800/s 左右,去掉上述代码速度可提高数倍。
./bin/maxwell-bootstrap --database xhd --table xhd-sso --host 127.0.0.1 --user xiehd --password xiehd2018 --client_id maxwell_dev
./bin/maxwell --client_id maxwell_dev
- producer_partition_by 可以选择按数据库、表、主键、事务 ID、列数据或”随机” 拆分流分发到不同的kafka分区。
- 可能要注意版本选择和时区问题
kafka对maxwell数据处理
kafka处理成的目标数据分为三种:
- 第一种为数据库直接拉过用的数据,这种数据处理比较简单,直接入es就行
- 第二种为业务需要的展示数据,因为表中很多关联,一对一的直接使用自己写的模拟join嵌入展示数据结构中,根据条件处理部分更新。一对多的嵌套效率不高,经过思考决定添加一个中间表来做聚合数据存放,这个表虽然不存在数据库中,但是也采用入列kafka的方式来处理,即为下面的第三种。
- 第三种为聚合数据,经过聚合的数据保存到es中,同时对业务表进行部分更新。而聚合处理通过一个索引的后处理器来执行。
综上所述,kafka对maxwell的数据处理需要分为几部分,一个是单表的直接处理,第二种的是一对一的嵌入处理,第三种是单表的后处理器对数据进行聚合再模拟maxwell写入kafka,之后这个数据会被单表和一对一的处理消费
public DataMapping{
//case_id,task_id,dispacher_id,assessor_id,assessor_name
private String index;//父关联字段,通常作为条件列
private String type;//关联字段,通常作为条件字段,在fields中
private String typeField;//主键,在fields中
private String database;
private String table;
private String tableField;
private String relationTypekey;
private String relationTableKey;
//将上面的数据解析为一个长Map
//当 某数据库的某表 的某字段改变时 某索引 的 某类型 的set里的字段更加pari条件改变 Map<String,Map<String,Map<Stirng,Map<String,Map<Stirng,Map<Pair<String,String>,Set<String>>>>>>
}
### elasticSearch 实现字段搜索封装
版权声明:本文为qq_29415357原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。