当我们优化一个低性能的SQL时,通常第一件事就是查看执行计划。通过执行计划我们可以查看MySQL是如何处理一个SQL语句的,包括表的连接顺序、预估成本、索引使用情况等。
根据SQL执行计划可以找到性能低下的瓶颈在哪,在不需要重写SQL的情况下,通常SQL性能问题可以分为以下几类:
- 表的连接没有创建索引,连接效率低下。
- 表的连接顺序不合适。
- 表创建了索引,但是mysql却没有使用。
对应的解决方法通常为:
- 建立合适的索引,提升表连接的速度。
- 调整表的连接顺序(使用hint或外连接)
- 排查索引失效的原因,重新收集统计信息,帮助优化器选择更好的执行计划。
目录
一、查看执行计划
1. explain
查看执行计划,最简单的办法就是在SQL前添加explain关键字,explain不仅可以解释select查询,还可以解释delete,insert,update和replace语句,但最常用的场景还是优化select查询:
explain select * from cor_crm_ent;

2. explain extended
在explain后增加extended关键字,mysql会在执行计划中额外增加一列filtered,并且会根据执行计划逆向编译出一个select语句。这个语句是在生成执行计划后,根据执行计划反向编译出来的,与原SQL无关,可以用show warnings语句查看。大部分情况下这个SQL与原SQL不同,可以通过这种方式查看mysql是如何改写SQL语句的。
explain extended select cust_id,company_name from cor_crm_ent;

注意explain extended语句会附带一个warning信息,通过show warnings我们可以查看反向编译的SQL:
show warnings;

3. explain partitions
explain partions可以显示检索的分区信息,这个选项只有在涉及分区表才会使用,普通非分区表即使使用也显示为空
explain partitions select count(*) from focs_interest partition (p_201808);

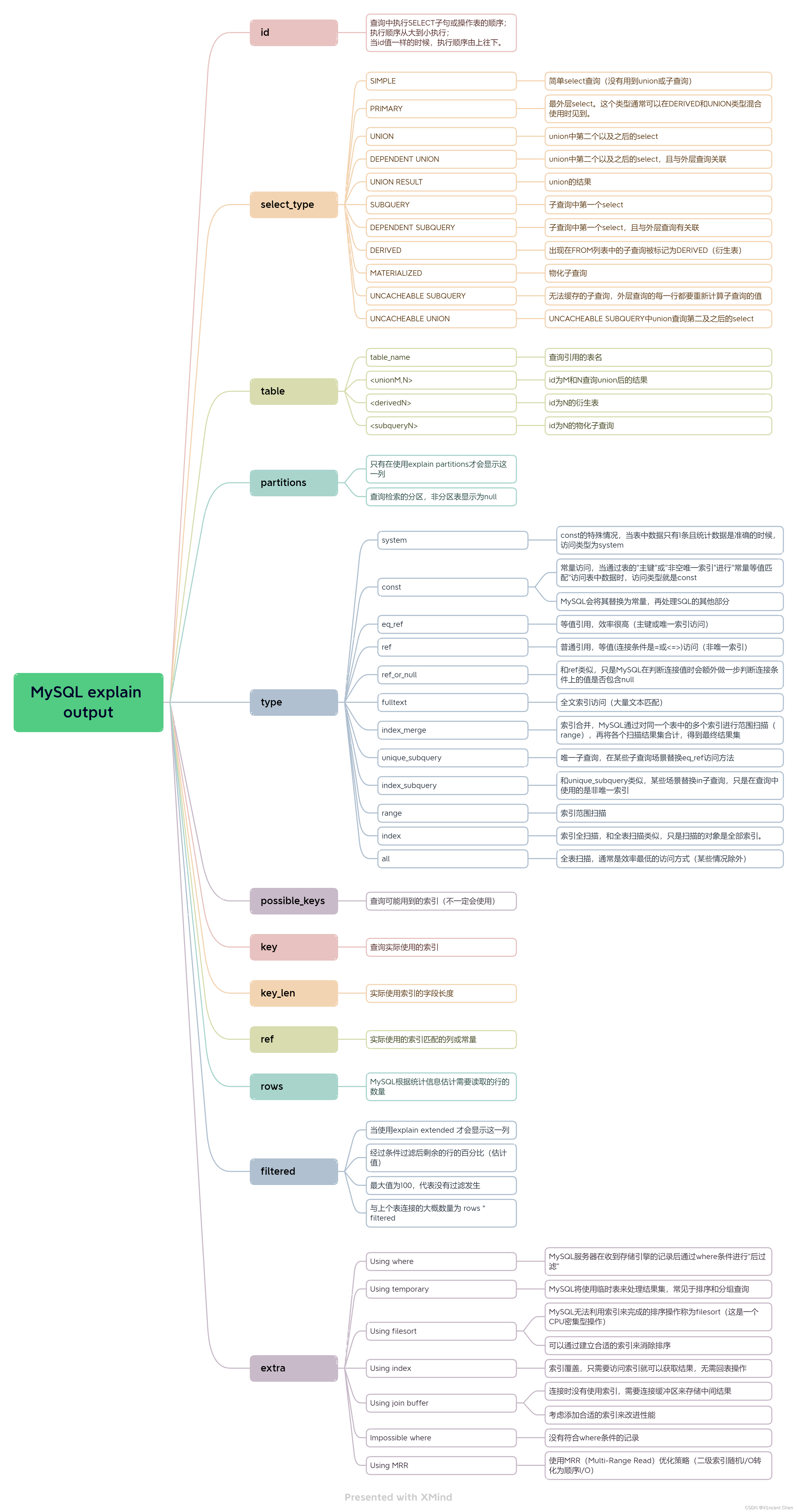
二、执行计划输出列含义
1. id
select的标识符,一般按select出现的顺序编号。但如果是引用union的结果,id显示为空,此时table列会显示<unionM,N>,代表编号为M和N的select合并结果。
explain
select * from ( -- id为1的select
select cust_id from cor_crm_ent -- id为2的select
union
select credit_id from cor_lms_facility) t; -- id为3的select

注意最后一行union result,id的编号为空,同时table列是<union2,3>,代表是id为2,3的select合并后的结果集。
2. select_type
select_type代表不同的select类型,具体的值和含义如下表:
|
select_type |
含义 |
|
SIMPLE |
简单select查询(没有用到union或子查询) |
|
PRIMARY |
最外层select。这个类型通常可以在DERIVED和UNION类型混合使用时见到。 |
|
UNION |
union中第二个以及之后的select |
|
DEPENDENT UNION |
union中第二个以及之后的select,且与外层查询关联 |
|
UNION RESULT |
union的结果 |
|
SUBQUERY |
子查询中第一个select |
|
DEPENDENT SUBQUERY |
子查询中第一个select,且与外层查询有关联 |
|
DERIVED |
出现在FROM列表中的子查询被标记为DERIVED(衍生表) |
|
MATERIALIZED |
物化子查询 |
|
UNCACHEABLE SUBQUERY |
无法缓存的子查询,外层查询的每一行都要重新计算子查询的值 |
|
UNCACHEABLE UNION |
UNCACHEABLE SUBQUERY中union查询第二及之后的select |
3. table_name
查询用到的表名,也可能是union结果集,衍生表,物化子查询,可能出现的值如下:
|
table_name |
含义 |
|
table_name |
查询引用的表名 |
|
<unionM,N> |
id为M和N查询union后的结果 |
|
<derivedN> |
id为N的衍生表 |
|
<subqueryN> |
id为N的物化子查询 |
4. type
数据的访问方法,具体的解释可以参考下面文章:
MySQL查询优化之一:数据的访问方法(Access Paths)_V1ncent Chen的博客-CSDN博客
5. possible_keys
查询中可能用到的索引,这里只是列出可以使用的索引,但实际查询时并不一定会用到。
6. keys
显示MySQL实际使用的索引,如果这个索引没有出现在possible_keys列中,那么MySQL选用它是出于另外的原因——比如它可能选择了一个覆盖索引。
7. key_len
实际使用的索引(keys列)的字节数。
8.ref
显示在key列记录的索引中查找值所用的列或常量。
9. rows
这一列是MySQL估计为了找到所需的行而要读取的行数。数值根据索引和统计信息计算出,可能不是很精确。rows列的值如果很大,通常代表访问方法(type列,access paths)不是很高效,需要尝试是否有更高效的访问方法。
10. filtered
使用explain extended会显示此列,它显示的是针对表里符合某个条件(WHERE子句或联接条件)的记录数的百分比所做的一个估算。如果你把rows列和这个百分比相乘,就能算出MySQL估算它将和查询计划里前一个表关联的行数。
在查看执行计划时,rows*filtered列是一个需要关注的重点,大量的数据会导致连接速度急剧下降。
11.Extra
包含一些不适合在其他列显示额外信息,其中比较重要的有如下(完整的内容较多,可以参考官方文档):
|
Extra |
含义 |
|
Using where |
MySQL服务器在收到存储引擎的记录后通过where条件进行“后过滤”(MySQL中索引过滤是在存储引擎层,where条件过滤是在应用层) |
|
Using temporary |
|
|
Using filesort |
MySQL无法利用索引来完成的排序操作称为filesort(这是一个CPU密集型操作) 可以通过建立合适的索引来消除排序 |
|
Using index |
索引覆盖,只需要访问索引就可以获取结果,无需回表操作 |
|
Using join buffer |
连接时没有使用索引,需要连接缓冲区来存储中间结果 考虑添加合适的索引来改进性能 |
|
Impossible where |
没有符合where条件的记录 |
|
Using MRR |
使用MRR(Multi-Range Read)优化策略(二级索引随机I/O转化为顺序I/O) |
在优化SQL,阅读执行计划时,我们通常需要关注的点有:
- table列,关注连接的顺序,驱动表是否高效。
- type/possible_keys/key,关注索引的使用情况(SQL的写法、统计信息失效都会导致未正确使用索引)。
- rows/filter,关注是否需要访问大量的数据,通常与访问方法type有关,高效的访问方式,rows列值通常都很低。
- extra列,辅助判断执行信息,是否有排序(filesort)等高成本操作,考虑用索引消除。
对于也SQL可以尝试优化改写,并查看不同的执行计划区别,找到最高效的方式。