1、前言
在阅读Linux内核代码时,我们可以看到在if/else结构中,都用到了likely和unlikely这样的判断,其实不只是Linux内核,很多开源代码,比如DPDK,suricata等等,都用到了它们。
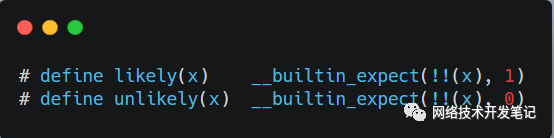
ps: 这里两次取反,是把x的表达式变成一个bool类型的值。
那如果我们深究一下,为什么这些开源代码都热衷于在if后面加这么个宏定义呢?使用它到底有什么好处呢?
碰到问题,我们习惯通过搜索引擎找答案,搜索引擎一般给出的答案是:通过likely和unlikely告诉编译器哪个条件分支发生的可能性更大。
这个说法当然没错,只是还没有说到更关键的点子上。
其实,使用likely和unlikely是跟CPU的工作方式有关,今天我们就一起来看一下。
2、C代码生成可执行程序的过程
我们一般都知道,C语言由源码变成可以运行的可执行文件包括四个阶段,分别是:
-
-预处理阶段(预处理器)
-
-编译阶段(编译器)
-
-汇编阶段(汇编器)
-
-链接阶段(链接器)
以我写的下面这个C代码likely.c文件为例:
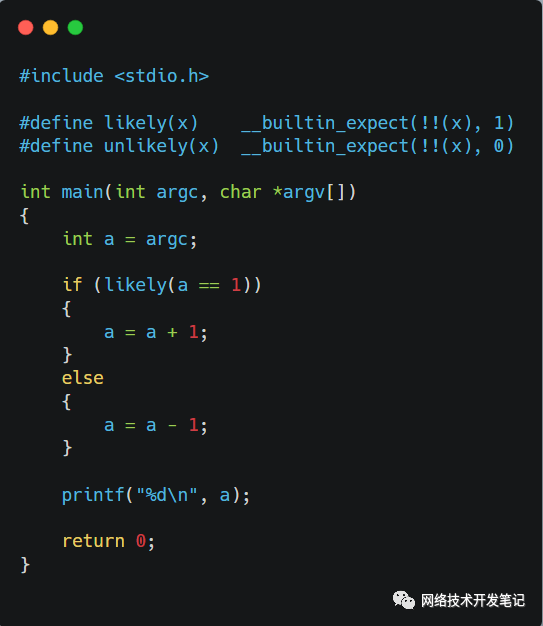
具体过程见下图:

我们使用objdump命令:objdump -S likely.o,看一下likely.o的汇编指令:
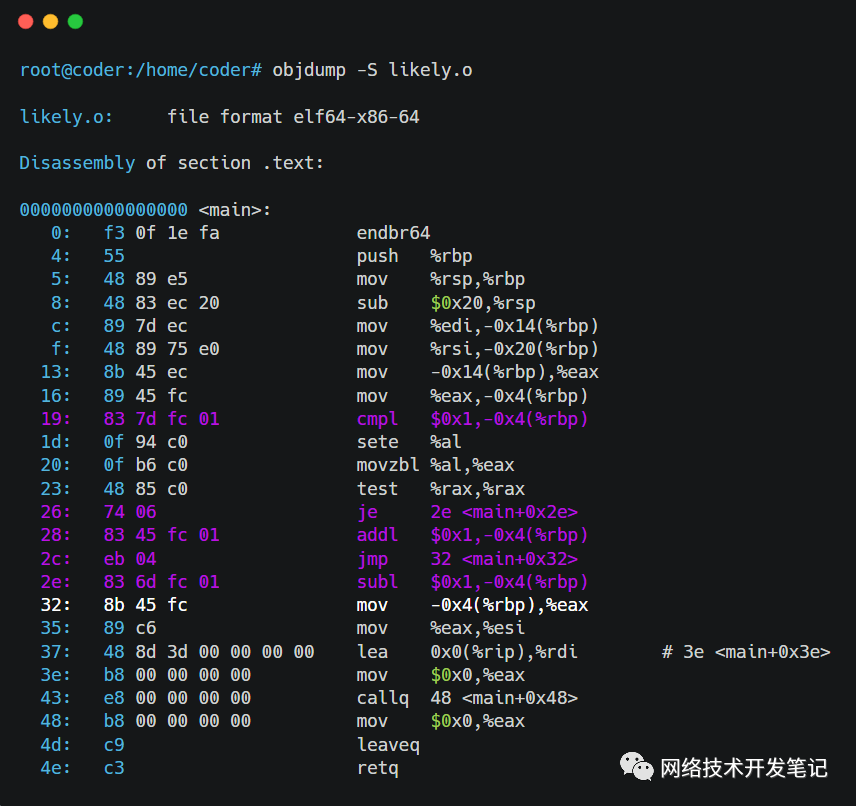
在这个过程中,gcc编译器帮我们把likely.c的分支代码逻辑,翻译成了cmpl、je、addl、jmp和subl等汇编机器指令给CPU去执行。
3、CPU Cache和指令预取
上面的likely.c源码,经过编译,最终生成了likely可执行程序,这个可执行程序现在在磁盘上,当我们在linux系统上通过./likely执行程序时,计算机会把likely程序文件包含的内容,从磁盘读到内存,然后再读到CPU Cache中进行执行。
为什么要有Cache?因为CPU执行指令的速度非常快,而从内存中读数据却慢得多,所以在它们之间加了一个Cache,CPU从内存中读取指令数据时,会把一些热点数据放到Cache中,每次读取时,会先去Cache中看有没有需要的数据,如果没有,才去内存中读取,通过这样的方式来提高CPU的处理效率。
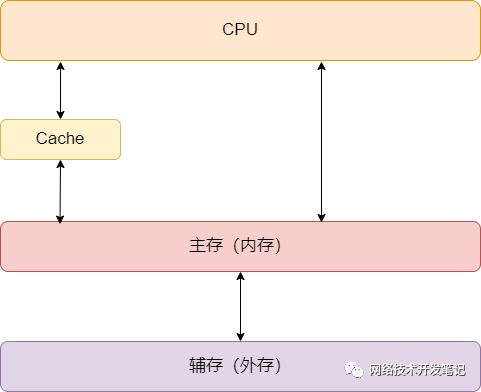
通过下面这张图,我们可以了解到计算机系统存储系统的层次结构,
它是一个金字塔是结构:
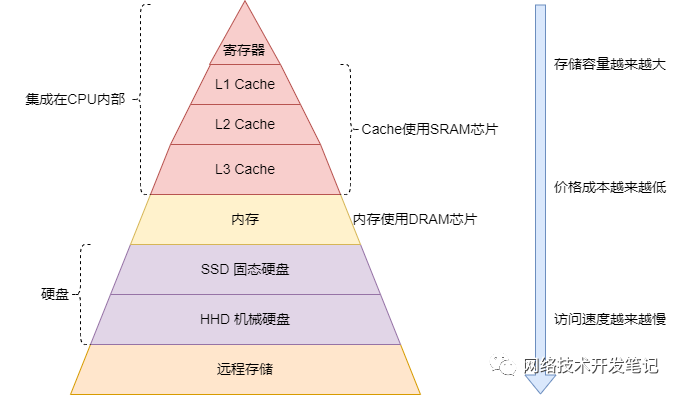
另外,CPU从Cache中读取数据,并不是一条一条指令数据的读取,而是以一定大小字节来读取的,一般是64字节,我们也叫做Cache Line。
所以对于上面if语句里面的代码指令,CPU很有可能也是会读到Cache中,从而方便下次进行处理的。
但是这里有一个问题,if/else是一个条件分支,也就是if和else分支包含的内容,是只会执行一个的,所以,如果把if和else中包含的指令都加载到Cache,总有一部分是无用的,而且会占用Cache的空间(Cache的空间很小)。
这部分无用的指令在Cache中不会被命中,我们叫做Cache miss,它也是会影响CPU的性能。
其实,CPU执行指令本身也是带分支预测功能的,就是根据多次执行指令的情况,来动态预测来哪一部分的指令更可能执行,然后就将这部分指令提前加载到Cache中。
那再回到likely.c程序,如果程序员事先从业务逻辑上已经知道了哪一个分支更可能发生,通过likely告诉编译器,编译器可以在编译生成CPU执行指令时,通过改变指令在可执行二进制文件中的顺序,特意让CPU提前加载更有可能发生的分支指令到Cache中,从而来提高CPU的执行效率。
4、CPU的流水线工作机制
CPU除了会提前对指令预取以外,其实它还是流水线作业的,什么意思呢?就是为了提高性能,避免串行执行指令的等待,CPU执行指令的多个步骤,其实是同步开展的。
CPU 执行一条指令的过程大致如下:
-
取指:CPU 从内存中取出下一条指令。
-
解码:CPU 识别出指令的类型和操作数。
-
执行:根据指令的类型和操作数,CPU 进行相应的运算或数据传送。
-
访存:将数据从存储器读出或写入存储器
-
写回:将运算结果写回到内存或寄存器中。
CPU流水线工作示意图如下:
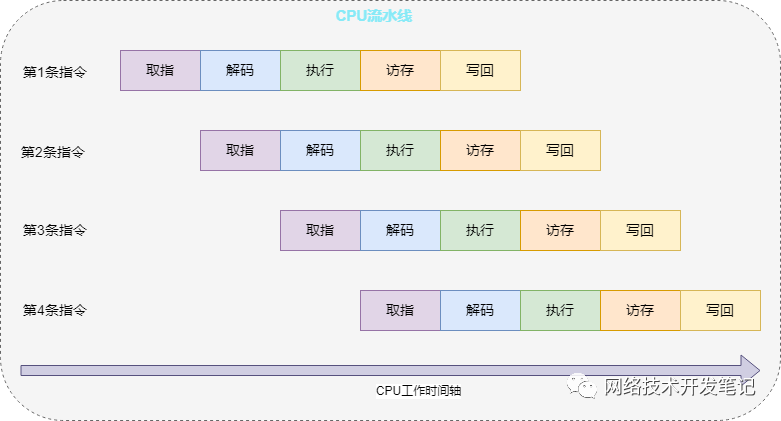
所以,在对if条件进行判断时,其实CPU已经开始在执行条件分支里面的指令了,如果分支预测失败,那么,这些指令的执行都是无效的,对数据的计算操作都要擦除重来,所以对CPU的性能影响还是挺大的。
5、需要注意的问题
现代CPU的分支预测准确率可以到90%以上。既然准确率不是100%,就意味着有失败的时候。
如果CPU发现预测错误,会把所有预测之后的指令执行结果全部抛弃,然后从预测分支那里重新开始执行,相当于很多指令白跑了。
预测失败的代价很高,正常一条指令执行需要10-20个指令周期,预测失败的话可能额外多出30-40个指令周期。
因此在分支发生概率严重倾斜、追求极致性能的场景下,使用likely/unlikely才具有较大意义。
怎么样,看了上面的分析,小伙伴们有没有什么想法?是不是没想到,我们写的代码里面,很小很小的一个细节,竟然暗藏有这么深的玄机。小伙伴们对这种类型的文章感不感兴趣呢?要不要小智再给大家多扒一扒?要的话,大家点个分享、在看和点赞,我就知道了,哈哈~~
我的号没有留言功能,不过并不妨碍小伙伴认真仔细读我的文章,上一篇文章
《什么是NUMA,我们为什么要了解NUMA》
有一处很明显的错误,有小伙伴马上加我wx(ID: coderxiaozhi),给我指出来了,真的非常感谢他。
希望有更多的小伙伴看到我的文章,跟我讨论,指出我的问题,这样大家才能一起学习进步。另外,我还建了一个交流群,大家一起交流技术,划水、八卦都可以。