1. 常见排序算法分类
十种常见排序算法一般分为以下几种:
1)非线性时间比较类排序:交换类排序(快速排序和冒泡排序)、插入类排序(简单插入排序和希尔排序)、选择类排序(简单选择排序和堆排序)、归并排序(二路归并排序和多路归并排序);
2)线性时间非比较类排序:计数排序、基数排序和桶排序。
总结:
1)在比较类排序中,归并排序最快,其次是快速排序和堆排序,两者不相伯仲,但是有一点需要注意,数据初始排序状态对堆排序不会产生太大的影响,而快速排序却恰恰相反。
2)线性时间非比较类排序一般要优于非线性时间比较类排序,但前者对待排序元素的要求较为严格,比如计数排序要求待排序数的最大值不能太大,桶排序要求元素按照hash分桶后桶内元素的数量要均匀。线性时间非比较类排序的典型特点是以空间换时间。
注:本博文的示例代码均已递增排序为目的。
2. 算法描述与实现
2.1 交换类排序
交换排序的基本方法是:两两比较待排序记录的排序码,交换不满足顺序要求的偶对,直到全部满足位置。常见的冒泡排序和快速排序就属于交换类排序。
2.1.1 冒泡排序
算法思想:
从数组中第一个数开始,依次遍历数组中的每一个数,通过相邻比较交换,每一轮循环下来找出剩余未排序数的中的最大数并“冒泡”至数列的顶端。
算法步骤:
1)从数组中第一个数开始,依次与下一个数比较并且交换比自己小的数,直到最后一个数。如果发生交换,则继续下面的步骤,如果未发生交换,则数组有序,排序结束,此时时间复杂度为
;
2)每一轮“冒泡”结束后,最大的数将出现在乱序数列的最后一位。重复步骤(1)。
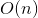
稳定性:
稳定排序。
时间复杂度:
至
,平均时间复杂度为
。
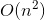
最好的情况:如果待排序数据序列为正序,则一趟冒泡就可完成排序,排序码的比较次数为n-1次,且没有移动,时间复杂度为
。
最坏的情况:如果待排序数据序列为逆序,则冒泡排序需要n-1次趟起泡,每趟进行n-i次排序码的比较和移动,即比较和移动次数均达到最大值:
比较次数:
移动次数等于比较次数,因此最坏时间复杂度为
。
示例代码:
void bubbleSort(int array[],int len){
//循环的次数为数组长度减一,剩下的一个数不需要排序
for(int i=0;i<len-1;++i){
bool noswap=true;
//循环次数为待排序数第一位数冒泡至最高位的比较次数
for(int j=0;j<len-i-1;++j){
if(array[j]>array[j+1]){
array[j]=array[j]+array[j+1];
array[j+1]=array[j]-array[j+1];
array[j]=array[j]-array[j+1];
//交换或者使用如下方式
//a=a^b;
//b=b^a;
//a=a^b;
noswap=false;
}
}
if(noswap) break;
}
}
2.1.2 快速排序
冒泡排序是在相邻的两个记录进行比较和交换,每次交换只能上移或下移一个位置,导致总的比较与移动次数较多。快速排序又称分区交换排序,是对冒泡排序的改进,快速排序采用的思想是分治思想。
算法原理:
1)从待排序的n个记录中任意选取一个记录(通常选取第一个记录)为分区标准;
2)把所有小于该排序列的记录移动到左边,把所有大于该排序码的记录移动到右边,中间放所选记录,称之为第一趟排序;
3)然后对前后两个子序列分别重复上述过程,直到所有记录都排好序。
稳定性:
不稳定排序。
时间复杂度:
至
,平均时间复杂度为
。
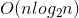
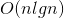
最好的情况:是每趟排序结束后,每次划分使两个子文件的长度大致相等,时间复杂度为
。
最坏的情况:是待排序记录已经排好序,第一趟经过n-1次比较后第一个记录保持位置不变,并得到一个n-1个元素的子记录;第二趟经过n-2次比较,将第二个记录定位在原来的位置上,并得到一个包括n-2个记录的子文件,依次类推,这样总的比较次数是:
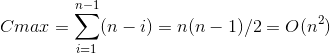
示例代码:
//a:待排序数组,low:最低位的下标,high:最高位的下标
void quickSort(int a[],int low, int high)
{
if(low>=high)
{
return;
}
int left=low;
int right=high;
int key=a[left]; /*用数组的第一个记录作为分区元素*/
while(left!=right){
while(left<right&&a[right]>=key) /*从右向左扫描,找第一个码值小于key的记录,并交换到key*/
--right;
a[left]=a[right];
while(left<right&&a[left]<=key)
++left;
a[right]=a[left]; /*从左向右扫描,找第一个码值大于key的记录,并交换到右边*/
}
a[left]=key; /*分区元素放到正确位置*/
quickSort(a,low,left-1);
quickSort(a,left+1,high);
}
2.2 插入类排序
插入排序的基本方法是:每步将一个待排序的记录,按其排序码大小,插到前面已经排序的文件中的适当位置,直到全部插入完为止。
2.2.1 直接插入排序
原理:
从待排序的n个记录中的第二个记录开始,依次与前面的记录比较并寻找插入的位置,每次外循环结束后,将当前的数插入到合适的位置。
稳定性:
稳定排序。
时间复杂度:
至
,平均时间复杂度为
。
最好情况:当待排序记录已经有序,这时需要比较的次数是
。
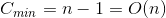
最坏情况:如果待排序记录为逆序,则最多的比较次数为
。
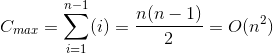
示例代码:
//A:输入数组,len:数组长度
void insertSort(int A[],int len)
{
int temp;
for(int i=1;i<len;i++)
{
int j=i-1;
temp=A[i];
//查找到要插入的位置
while(j>=0&&A[j]>temp)
{
A[j+1]=A[j];
j--;
}
if(j!=i-1)
A[j+1]=temp;
}
}
2.2.2 Shell排序
Shell 排序又称缩小增量排序, 由D. L. Shell在1959年提出,是对直接插入排序的改进。
原理:
Shell排序法是对相邻指定距离(称为增量)的元素进行比较,并不断把增量缩小至1,完成排序。
Shell排序开始时增量较大,分组较多,每组的记录数目较少,故在各组内采用直接插入排序较快,后来增量
逐渐缩小,分组数减少,各组的记录数增多,但由于已经按
分组排序,文件叫接近于有序状态,所以新的一趟排序过程较快。因此Shell排序在效率上比直接插入排序有较大的改进。
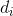
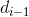
在直接插入排序的基础上,将直接插入排序中的1全部改变成增量d即可,因为Shell排序最后一轮的增量d就为1。
稳定性:
不稳定排序。
时间复杂度:
到
。Shell排序算法的时间复杂度分析比较复杂,实际所需的时间取决于各次排序时增量的个数和增量的取值。研究证明,若增量的取值比较合理,Shell排序算法的时间复杂度约为
。
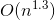
对于增量的选择,Shell 最初建议增量选择为n/2,并且对增量取半直到 1;D. Knuth教授建议
序列。
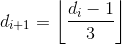
//A:输入数组,len:数组长度,d:初始增量(分组数)
void shellSort(int A[],int len, int d)
{
for(int inc=d;inc>0;inc/=2){ //循环的次数为增量缩小至1的次数
for(int i=inc;i<len;++i){ //循环的次数为第一个分组的第二个元素到数组的结束
int j=i-inc;
int temp=A[i];
while(j>=0&&A[j]>temp)
{
A[j+inc]=A[j];
j=j-inc;
}
if((j+inc)!=i)//防止自我插入
A[j+inc]=temp;//插入记录
}
}
}
注意:
从代码中可以看出,增量每次变化取前一次增量的一般,当增量d等于1时,shell排序就退化成了直接插入排序了。
2.3 选择类排序
选择类排序的基本方法是:每步从待排序记录中选出排序码最小的记录,顺序放在已排序的记录序列的后面,直到全部排完。
2.3.1 简单选择排序(又称直接选择排序)
原理:
从所有记录中选出最小的一个数据元素与第一个位置的记录交换;然后在剩下的记录当中再找最小的与第二个位置的记录交换,循环到只剩下最后一个数据元素为止。
稳定性:
不稳定排序。
时间复杂度:
最坏和最好平均复杂度均为
,因此,简单选择排序也是常见排序算法中性能最差的排序算法。简单选择排序的比较次数与文件的初始状态没有关系,在第i趟排序中选出最小排序码的记录,需要做n-i次比较,因此总的比较次数是:
。
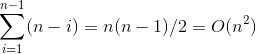
示例代码:
void selectSort(int A[],int len)
{
int i,j,k;
for(i=0;i<len;i++){
k=i;
for(j=i+1;j<len;j++){
if(A[j]<A[k])
k=j;
}
if(i!=k){
A[i]=A[i]+A[k];
A[k]=A[i]-A[k];
A[i]=A[i]-A[k];
}
}
}
2.3.2 堆排序
直接选择排序中,第一次选择经过了n-1次比较,只是从排序码序列中选出了一个最小的排序码,而没有保存其他中间比较结果。所以后一趟排序时又要重复许多比较操作,降低了效率。J. Willioms和Floyd在1964年提出了堆排序方法,避免这一缺点。
2.3.2.1 堆的性质
1)性质:堆是一棵完全二叉树,完全二叉树不一定是堆;
2)分类:大顶堆:父节点不小于子节点键值,小顶堆:父节点不大于子节点键值;下图展示了一个小顶堆:
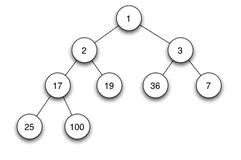
3)左右孩子:没有大小的顺序。
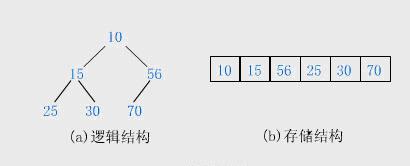
4)堆的存储:一般都用数组来存储堆,i结点的父结点下标就为
。它的左右子结点下标分别为
和
。如第0个结点左右子结点下标分别为1和2。
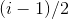
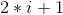
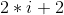
2.3.2.2 堆的基本操作
1)建立
以最小堆为例,如果以数组存储元素时,一个数组具有对应的树表示形式,但树并不满足堆的条件,需要重新排列元素,可以建立“堆化”的树。
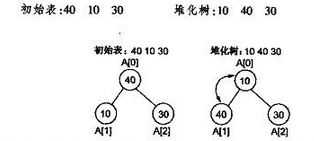
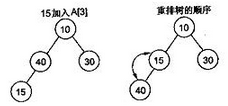
2)插入
将一个新元素插入到表尾,即数组末尾时,如果新构成的二叉树不满足堆的性质,需要重新排列元素,下图演示了插入15时,堆的调整。
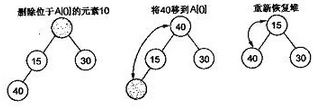
3)删除。
堆排序中,删除一个元素总是发生在堆顶,因为堆顶的元素是最小的(小顶堆中)。表中最后一个元素用来填补空缺位置,结果树被更新以满足堆条件。
2.3.2.3 堆操作实现
1)插入代码实现
每次插入都是将新数据放在数组最后。可以发现从这个新数据的父结点到根结点必然为一个有序的数列,现在的任务是将这个新数据插入到这个有序数据中,这就类似于直接插入排序中将一个数据并入到有序区间中,这是节点“上浮”调整。不难写出插入一个新数据时堆的调整代码:
//新加入i结点,其父结点为(i-1)/2
//参数:a:数组,i:新插入元素在数组中的下标
void minHeapFixUp(int a[], int i)
{
int j, temp;
temp = a[i];
j = (i-1)/2; //父结点
while (j >= 0 && i != 0)
{
if (a[j] <= temp)//如果父节点不大于新插入的元素,停止寻找
break;
a[i]=a[j]; //把较大的子结点往下移动,替换它的子结点
i = j;
j = (i-1)/2;
}
a[i] = temp;
} 因此,插入数据到最小堆时:
//在最小堆中加入新的数据data
//a:数组,index:插入的下标,
void minHeapAddNumber(int a[], int index, int data)
{
a[index] = data;
minHeapFixUp(a, index);
}
2)删除代码实现
按定义,堆中每次都只能删除第0个数据。为了便于重建堆,实际的操作是将数组最后一个数据与根结点,然后再从根结点开始进行一次从上向下的调整。
调整时先在左右儿子结点中找最小的,如果父结点不大于这个最小的子结点说明不需要调整了,反之将最小的子节点换到父结点的位置。此时父节点实际上并不需要换到最小子节点的位置,因为这不是父节点的最终位置。但逻辑上父节点替换了最小的子节点,然后再考虑父节点对后面的结点的影响。相当于从根结点将一个数据的“下沉”过程。下面给出代码:
//a为数组,从index节点开始调整,len为节点总数 从0开始计算index节点的子节点为 2*index+1, 2*index+2,len/2-1为最后一个非叶子节点
void minHeapFixDown(int a[],int len,int index)
{
if(index>(len/2-1))//index为叶子节点不用调整
return;
int tmp=a[index];
lastIndex=index;
while(index<=len/2-1) //当下沉到叶子节点时,就不用调整了
{
if(a[2*index+1]<tmp) //如果左子节点小于待调整节点
{
lastIndex = 2*index+1;
}
//如果存在右子节点且小于左子节点和待调整节点
if(2*index+2<len && a[2*index+2]<a[2*index+1]&& a[2*index+2]<tmp)
{
lastIndex=2*index+2;
}
//如果左右子节点有一个小于待调整节点,选择最小子节点进行上浮
if(lastIndex!=index)
{
a[index]=a[lastIndex];
index=lastIndex;
}
else break; //否则待调整节点不用下沉调整
}
a[lastIndex]=tmp; //将待调整节点放到最后的位置
}
根据思想,可以有不同版本的代码实现。个人体会,这里建议大家根据对堆调整的过程的理解,写出自己的代码,切勿看示例代码去理解算法,而是理解算法思想写出代码,否则很快就会忘记。
3)建堆
有了堆的插入和删除后,再考虑下如何对一个数据进行堆化操作。要一个一个的从数组中取出数据来建立堆吧,不用!先看一个数组,如下图:
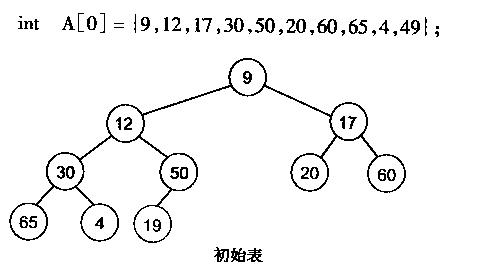
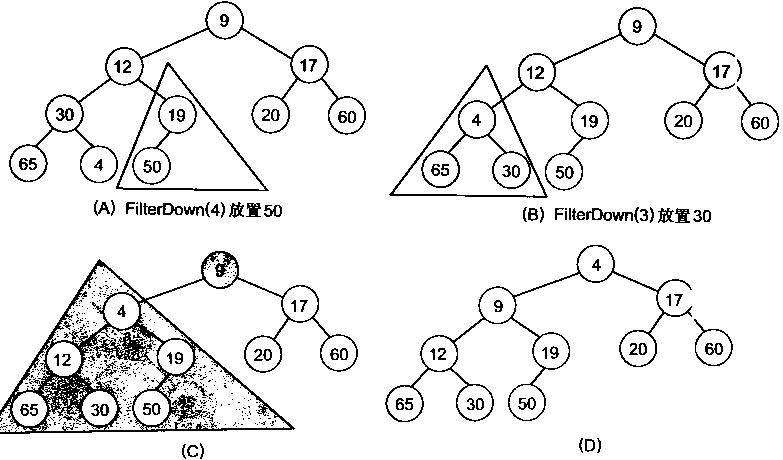
很明显,对叶子结点来说,可以认为它已经是一个合法的堆了即20,60, 65, 4, 49都分别是一个合法的堆。只要从A[4]=50开始向下调整就可以了。然后再取A[3]=30,A[2] = 17,A[1] = 12,A[0] = 9分别作一次向下调整操作就可以了。下图展示了这些步骤:
写出堆化数组的代码:
//建立最小堆
//a:数组,n:数组长度
void makeMinHeap(int a[], int n)
{
for (int i = n/2-1; i >= 0; i--)
minHeapFixDown(a, i, n);
}
2.3.2.4 堆排序的实现
由于堆也是用数组来存储的,故对数组进行堆化后,第一次将A[0]与A[n – 1]交换,再对A[0…n-2]重新恢复堆。第二次将A[0]与A[n – 2]交换,再对A[0…n – 3]重新恢复堆,重复这样的操作直到A[0]与A[1]交换。由于每次都是将最小的数据并入到后面的有序区间,故操作完成后整个数组就有序了。有点类似于直接选择排序。
因此,完成堆排序并没有用到前面说明的插入操作,只用到了建堆和节点向下调整的操作,堆排序的操作如下:
//array:待排序数组,len:数组长度
void heapSort(int array[],int len)
{
//建堆
makeMinHeap(array,len);
//最后一个叶子节点和根节点交换,并进行堆调整,交换次数为len-1次
for(int i=len-1;i>0;--i)
{
//最后一个叶子节点交换
array[i]=array[i]+array[0];
array[0]=array[i]-array[0];
array[i]=array[i]-array[0];
//堆调整
minHeapFixDown(array, 0, len-i-1);
}
} 1)稳定性:不稳定排序。
2)堆排序性能分析
由于每次重新恢复堆的时间复杂度为O(logN),共N – 1次堆调整操作,再加上前面建立堆时N / 2次向下调整,每次调整时间复杂度也为O(logN)。两次操作时间相加还是O(N * logN)。故堆排序的时间复杂度为O(N * logN)。
最坏情况:如果待排序数组是有序的,仍然需要O(N * logN)复杂度的比较操作,只是少了移动的操作;
最好情况:如果待排序数组是逆序的,不仅需要O(N * logN)复杂度的比较操作,而且需要O(N * logN)复杂度的交换操作。总的时间复杂度还是O(N * logN)。
因此,堆排序和快速排序在效率上是差不多的,但是堆排序一般优于快速排序的重要一点是,数据的初始分布情况对堆排序的效率没有大的影响。
2.4 归并排序
2.4.1 算法思想
归并排序属于比较类非线性时间排序,比较类排序中性能佳者,应用较为广泛。
归并排序是分治法(Divide and Conquer)的一个典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。一般情况,归并排序指的二路归并排序。
2.4.2 二路归并排序过程描述
设有数列{16,
23
,100,3,38,128,23}
初始状态:16,
23
,100,3,38,128,23
第一次归并后:{6,
23
},{3,100},{38,128},{23};
第二次归并后:{3,6,
23
,100},{23,38,128};
第三次归并后:{3,6,23,
23
,38,100,128}。
完成排序。
2.4.3 二路归并复杂度分析
时间复杂度:最坏、最好和平均时间复杂度都是O(nlgn),排序性能不受待排序的数据的混乱程度影响,比较稳定,这也是相对于快排的优势所在。
空间复杂度为:O(n)。
稳定性:稳定排序算法,从上文排序过程中可以看出,黑体23一直在前面。
2.4.4 二路归并实现
2.4.4.1 C/C++串行实现
/************************************************
*函数名称:mergearray
*参数:a:待归并数组;first:开始下标;mid:中间下标;
* last:结束下标;temp:临时数组
*说明:将有二个有序数列a[first...mid]和a[mid...last]合并
*************************************************/
void mergearray(int a[], int first, int mid, int last, int temp[])
{
int i = first, j = mid + 1,k =0;
while (i <= mid && j <= last)
{
if (a[i] <= a[j])
temp[k++] = a[i++];
else
temp[k++] = a[j++];
}
while (i<= mid)
temp[k++] = a[i++];
while (j <= last)
temp[k++] = a[j++];
for (i=0; i < k; i++)
a[first+i] = temp[i];
}
/************************************************
*函数名称:mergesort
*参数:a:待归并数组;first:开始下标;
* last:结束下标;temp:临时数组
*说明:实现给定数组区间的二路归并排序
*************************************************/
void mergesort(int a[], int first, int last, int temp[])
{
if (first < last)
{
int mid = (first + last) / 2;
mergesort(a, first, mid, temp); //左边有序
mergesort(a, mid + 1, last, temp); //右边有序
mergearray(a, first, mid, last, temp); //再将二个有序数列合并
}
}
2.4.4.2 C/C++并行实现
将待排序数组通过偏移量进行逻辑切分为多块,将每个块传递给多个线程调用二路归并排序函数进行排序。待各个块内有序后,再合并各个块整合成有序数列。
2)并行代码
线程函数,供创建出来的线程调用。
/*******************************************
*函数名称:merge_exec
*参数: para指针,用于接收线程下边,表示第几个线程
*说明: 调用二路归并排序
*******************************************/
void* merge_exec(void *para)
{
int threadIndex=*(int*)para;
int blockLen=DataNum/threadNum;
int* temp=new int[blockLen];
int offset=threadIndex*blockLen;
mergesort(randInt,offset,offset+blockLen-1,temp);
}合并多个已经排好序的块。代码如下:
/***********************************************
*函数名称:mergeBlocks
*参数: pDataArray:块内有序的数组 arrayLen:数组长度
* blockNum:块数 resultArray:存放排序的结果
*说明: 合并有序的块
************************************************/
inline void mergeBlocks(int* const pDataArray,int arrayLen,const int blockNum,int* const resultArray)
{
int blockLen=arrayLen/blockNum;
int blockIndex[blockNum];//各个块中元素在数组中的下标,VC可能不支持变量作为数组的长度,解决办法可使用宏定义
for(int i=0;i<blockNum;++i)//初始化块内元素起始下标
{
blockIndex[i]=i*blockLen;
}
int smallest=0;
for(int i=0;i<arrayLen;++i)//扫描所有块内的所有元素
{
for(int j=0;j<blockNum;++j)//以第一个未扫描完的块内元素作为最小数
{
if(blockIndex[j]<(j*blockLen+blockLen))
{
smallest=pDataArray[blockIndex[j]];
break;
}
}
for(int j=0;j<blockNum;++j)//扫描各个块,寻找最小数
{
if((blockIndex[j]<(j*blockLen+blockLen))&&(pDataArray[blockIndex[j]]<smallest))
{
smallest=pDataArray[blockIndex[j]];
}
}
for(int j=0;j<blockNum;++j)//确定哪个块内元素下标进行自增
{
if((blockIndex[j]<(j*blockLen+blockLen))&&(pDataArray[blockIndex[j]]==smallest))
{
++blockIndex[j];
break;
}
}
resultArray[i]=smallest;//本次循环最小数放入结果数组
}
}main函数中创建多线程完成并行排序,代码如下:
int main(int argc,char* argv[])
{
int threadBum=8;
int blockNum=threadNum;
struct timeval ts,te;
srand(time(NULL));
for(int i=0;i<DataNum;++i)
{
randInt[i]=rand();
}
pthread_t tid[blockNum],ret[blockNum],threadIndex[blockNum];
//--------Two-way Merge Sort-------
gettimeofday(&ts,NULL);
for(int i = 0; i < threadNum; ++i)
{
threadIndex[i]=i;
ret[i] = pthread_create(&tid[i], NULL,merge_exec,(void *)(threadIndex+i));
if(ret[i] != 0){
cout<<"thread "<<i<<" create error!"<<endl;
break;
}
}
for(int i = 0; i <threadNum; ++i)
{
pthread_join(tid[i], NULL);
}
mergeBlocks(randInt,DataNum,threadNum,resultInt);
gettimeofday(&te,NULL);
cout<<"MergeSort time: "<<(te.tv_sec-ts.tv_sec)*1000+(te.tv_usec-ts.tv_usec)/1000<<"ms"<<endl;
}
2.5 线性时间非比较类排序
2.5.1 计数排序
计数排序是一个非基于比较的排序算法,该算法于1954年由 Harold H. Seward 提出,它的优势在于在对于较小范围内的整数排序。它的复杂度为Ο(n+k)(其中k是待排序数的范围),快于任何比较排序算法,缺点就是非常消耗空间。很明显,如果而且当O(k)>O(n*log(n))的时候其效率反而不如基于比较的排序,比如堆排序、归并排序和快速排序。
算法原理:
基本思想是对于给定的输入序列中的每一个元素x,确定该序列中值小于x的元素的个数。一旦有了这个信息,就可以将x直接存放到最终的输出序列的正确位置上。例如,如果输入序列中只有17个元素的值小于x的值,则x可以直接存放在输出序列的第18个位置上。当然,如果有多个元素具有相同的值时,我们不能将这些元素放在输出序列的同一个位置上,在代码中作适当的修改即可。
算法步骤:
1)找出待排序的数组中最大的元素;
2)统计数组中每个值为i的元素出现的次数,存入数组C的第i项;
3)对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);
4)反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。
时间复杂度:
Ο(n+k)。
空间复杂度:
Ο(k)。
要求:
待排序数中最大数值不能太大。
稳定性:
稳定。
代码示例:
#define MAXNUM 20 //待排序数的最大个数
#define MAX 100 //待排序数的最大值
int sorted_arr[MAXNUM]={0};
//计算排序
//arr:待排序数组,sorted_arr:排好序的数组,n:待排序数组长度
void countSort(int *arr, int *sorted_arr, int n)
{
int i;
int *count_arr = (int *)malloc(sizeof(int) * (MAX+1));
//初始化计数数组
memset(count_arr,0,sizeof(int) * (MAX+1));
//统计i的次数
for(i = 0;i<n;i++)
count_arr[arr[i]]++;
//对所有的计数累加,作用是统计arr数组值和小于小于arr数组值出现的个数
for(i = 1; i<=MAX; i++)
count_arr[i] += count_arr[i-1];
//逆向遍历源数组(保证稳定性),根据计数数组中对应的值填充到新的数组中
for(i = n-1; i>=0; i--)
{
//count_arr[arr[i]]表示arr数组中包括arr[i]和小于arr[i]的总数
sorted_arr[count_arr[arr[i]]-1] = arr[i];
//如果arr数组中有相同的数,arr[i]的下标减一
count_arr[arr[i]]--;
}
free(count_arr);
}注意:计数排序是典型的以空间换时间的排序算法,对待排序的数据有严格的要求,比如待排序的数值中包含负数,最大值都有限制,请谨慎使用。
2.5.2 基数排序
2.5.2.1 算法思想
基数排序属于“分配式排序”(distribution sort),是非比较类线性时间排序的一种,又称“桶子法”(bucket sort)。顾名思义,它是透过键值的部分信息,将要排序的元素分配至某些“桶”中,藉以达到排序的作用。
2.5.2.2
算法过程描述
基数排序(以整形为例),将整形10进制按每位拆分,然后从低位到高位依次比较各个位。主要分为两个过程:
1)分配,先从个位开始,根据位值(0-9)分别放到0~9号桶中(比如64,个位为4,则放入4号桶中);
2)收集,再将放置在0~9号桶中的数据按顺序放到数组中;
重复(1)(2)过程,从个位到最高位(比如32位无符号整形最大数4294967296,最高位为第10位)。基数排序的方式可以采用LSD(Least significant digital)或MSD(Most significant digital),LSD的排序方式由键值的最右边开始,而MSD则相反,由键值的最左边开始。
以【520 350 72 383 15 442 352 86 158 352】序列为例,排序过程描述如下:



排序完毕!
2.5.2.2
复杂度分析
平均时间复杂度:O(dn)(d即表示整形的最高位数)。
空间复杂度:O(10n) (10表示0~9,用于存储临时的序列) 。
稳定性:稳定。(代码实现参考
基数排序简介及其并行化
)
2.5.3 桶排序
桶排序也是分配排序的一种,但其是基于比较排序的,这也是与基数排序最大的区别所在。
思想:
桶排序算法想法类似于散列表。首先要假设待排序的元素输入符合某种均匀分布,例如数据均匀分布在[ 0,1)区间上,则可将此区间划分为10个小区间,称为桶,对散布到同一个桶中的元素再排序。
要求:
待排序数长度一致。
排序过程:
1)设置一个定量的数组当作空桶子;
2)寻访序列,并且把记录一个一个放到对应的桶子去;
3)对每个不是空的桶子进行排序。
4)从不是空的桶子里把项目再放回原来的序列中。
例如待排序列K= {49、 38 、 35、 97 、 76、 73 、 27、 49 }。这些数据全部在1—100之间。因此我们定制10个桶,然后确定映射函数f(k)=k/10。则第一个关键字49将定位到第4个桶中(49/10=4)。依次将所有关键字全部堆入桶中,并在每个非空的桶中进行快速排序。
时间复杂度:
对N个关键字进行桶排序的时间复杂度分为两个部分:
1) 循环计算每个关键字的桶映射函数,这个时间复杂度是O(N)。
2) 利用先进的比较排序算法对每个桶内的所有数据进行排序,对于N个待排数据,M个桶,平均每个桶[N/M]个数据,则桶内排序的时间复杂度为
。其中
为第i个桶的数据量。
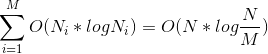
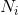
因此,平均时间复杂度为线性的O(N+C),C为桶内排序所花费的时间。当每个桶只有一个数,则最好的时间复杂度为:O(N)。
示例代码:
typedef struct node
{
int keyNum;//桶中数的数量
int key; //存储的元素
struct node * next;
}KeyNode;
//keys待排序数组,size数组长度,bucket_size桶的数量
void inc_sort(int keys[],int size,int bucket_size)
{
KeyNode* k=(KeyNode *)malloc(sizeof(KeyNode)); //用于控制打印
int i,j,b;
KeyNode **bucket_table=(KeyNode **)malloc(bucket_size*sizeof(KeyNode *));
for(i=0;i<bucket_size;i++)
{
bucket_table[i]=(KeyNode *)malloc(sizeof(KeyNode));
bucket_table[i]->keyNum=0;//记录当前桶中是否有数据
bucket_table[i]->key=0; //记录当前桶中的数据
bucket_table[i]->next=NULL;
}
for(j=0;j<size;j++)
{
int index;
KeyNode *p;
KeyNode *node=(KeyNode *)malloc(sizeof(KeyNode));
node->key=keys[j];
node->next=NULL;
index=keys[j]/10; //映射函数计算桶号
p=bucket_table[index]; //初始化P成为桶中数据链表的头指针
if(p->keyNum==0)//该桶中还没有数据
{
bucket_table[index]->next=node;
(bucket_table[index]->keyNum)++; //桶的头结点记录桶内元素各数,此处加一
}
else//该桶中已有数据
{
//链表结构的插入排序
while(p->next!=NULL&&p->next->key<=node->key)
p=p->next;
node->next=p->next;
p->next=node;
(bucket_table[index]->keyNum)++;
}
}
//打印结果
for(b=0;b<bucket_size;b++)
//判断条件是跳过桶的头结点,桶的下个节点为元素节点不为空
for(k=bucket_table[b];k->next!=NULL;k=k->next)
{
printf("%d ",k->next->key);
}
}
———————
转自:
https://blog.csdn.net/K346K346/article/details/50791102