一.概述
我们知道,如果你的业务表,比如商品表数据达到千万级别甚至更高,数据库的查询等操作性能可能就会下降,这个时候就要对商品表进行分库分表操作。
一个表分成多个表后,增删改啥操作的路由逻辑如何实现?这个时候你就可以使用sharding-jdbc。
本文使用springboot2.1.4+shardingjdbc4.0.0-RC1+mybaitsPlus
1.1 sharding-jdbc身份介绍
sharding-jdbc是Apache ShardingSphere项目中的3个独立产品中的一个,Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,已于2020年4月16日成为 Apache 软件基金会的顶级项目。
ShardingSphere项目由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成:
- ShardingSphere-JDBC :定位为轻量级 Java 框架,以 jar 包形式提供服务;
- ShardingSphere-Proxy :定位为透明化的数据库代理端,是一个独立部署的应用;
- ShardingSphere-Sidecar(TODO):定位为 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问;
更详细说明见官方文档:
https://shardingsphere.apache.org/document/current/cn/overview/#shardingsphere-jdbc
1.1.1实现原理
Sharding-JDBC处于业务代码和数据库中间,通过拦截请求书库的sql,进行sql语意分析,然后改写sql完成分库分表等功能。

1.1.2 适用范围
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
本文针对ShardingSphere-JDBC的使用方式,结合具体demo展开说明。
1.2 sharding-jdbc版本
github上版本如下:
https://github.com/apache/shardingsphere/releases
注意:不同版本使用方式略有差异,注意别踩坑,本文使用4.0.0-RC1版本。
二.sharding-jdbc单库分表
官方叫法:数据分片,包括分表和分库,日常我们一般使用springboot项目,因为本文只记录springboot项目中sharding-jdbc的使用方式。
2.1 项目环境准备
2.1.1 maven依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
springboot使用2.1.4.RELEASE,sharding-jdbc使用4.0.0-RC1。
2.1.2 数据库
搞个user表,假设我们分3个表,因为本节只是测试分表,不管分库,所以这里在同一个数据库中。然后再创建一个Car表,关联user表,后面用来测试关联查询。
CREATE TABLE `user_0`(
id bigint(20) not null,
city varchar(20) not null,
name varchar(20) not null,
car_id bigint(20) not null,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `user_1`(
id bigint(20) not null,
city varchar(20) not null,
name varchar(20) not null,
car_id bigint(20) not null,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `user_2`(
id bigint(20) not null,
city varchar(20) not null,
name varchar(20) not null,
car_id bigint(20) not null,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `car`(
id bigint(20) not null,
name varchar(20) not null,
price int(10) not null,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.1.3 项目结构

2.2 application.properties文件配置
#数据源名称(随便起名,如果有多个库,逗号隔开 ds0,ds1,ds2)
spring.shardingsphere.datasource.names=ds0
# 数据源
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/ds_0?characterEncoding=utf-8
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
#分表策略配置
##表名枚举,其中的user是需要分表的表名;ds0.user_$->{0..2} 其中ds0表示数据源名称;user_$->{0..2} 表示从user_0到user_2
spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds0.user_$->{0..2}
##使用哪一列用作计算分表策略,我们就使用id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
##具体的分表路由策略,我们有3个user表,使用主键id取余3,余数0/1/2分表对应表user_0,user_2,user_2
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{id % 3}
##配置主键生成策略,因为多张表了,id不能在配置数据库自增,需要配置主键生成策略,user表主键名称是id
spring.shardingsphere.sharding.tables.user.key-generator.column=id
##id使用雪花算法,因为雪花算法生成的id具有全球唯一性,并且又有自增特性,适合mysql的innodb引擎
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
配置的每一行都添加了注释,整体思路是:
- 配置源,每个数据库对应一个数据源,如果有多个数据库,那么就配置多个数据源;
- 指定分表策略,就是你得配置一些规则,让sharding-jdbc知道你哪几个表要分表,然后具体的路由策略是什么。
特别说明:
对于主键生成策略,本文配置只是针对user表,但实际car表在插入数据的时候,也被使用了雪花算法,虽然car使用了主键自增策略。
2.3 分表测试demo
2.3.1 数据插入
@Test
public void addUser() {
User user = new User();
user.setName("张三");
user.setCity("上海");
user.setCarId(1L);
userMapper.insert(user);
}
我们 想插入的逻辑sql如下,是user表:

shardingJdbc实际执行的sql如下,是user_2表:

因为id是1408808826319298561L ,取余3后值是2,因此就路由到了user_2表。
2.3.2 查询数据
我们事先插入10条数据,分布在user_0,user_1,user_2三张表里如下:
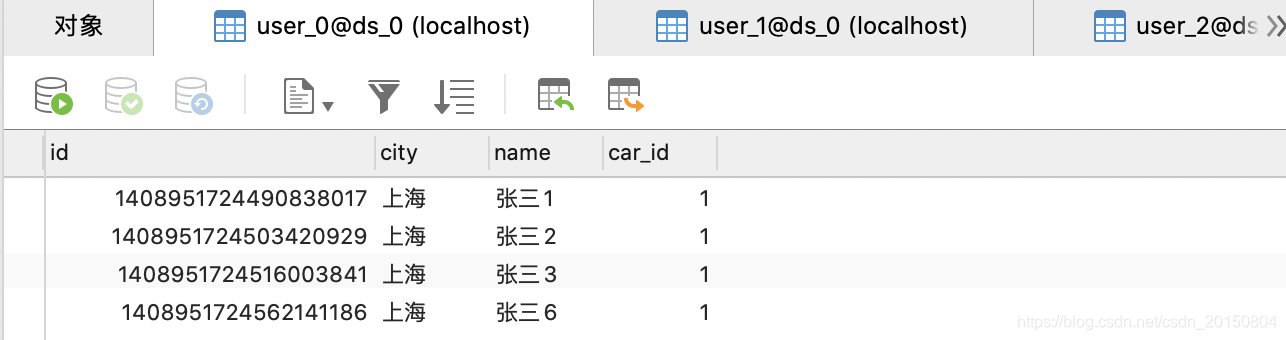
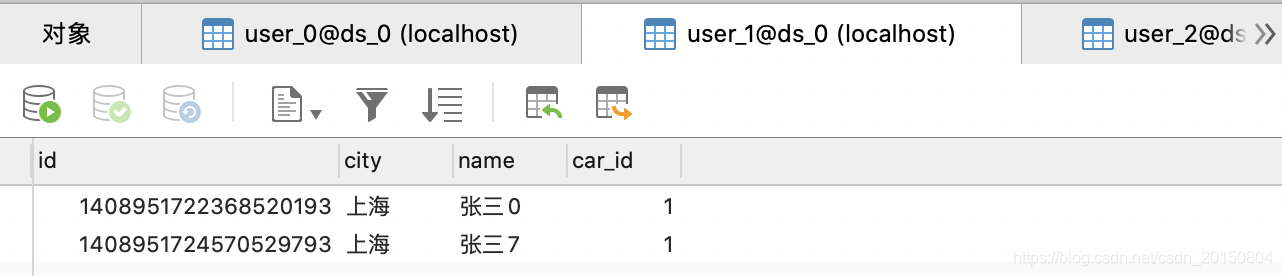
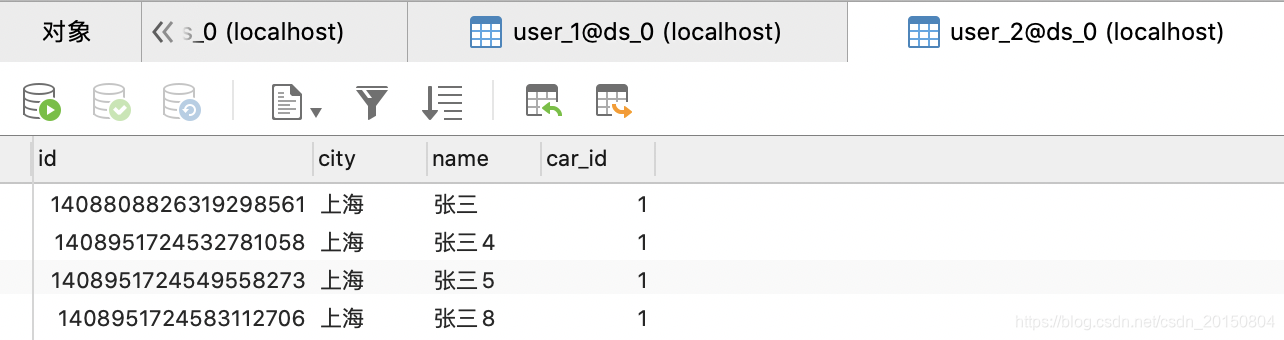
1.查询单条数据
我们查询user_2表中的1408808826319298561:
@Test
public void selectUser() {
userMapper.selectById(1408808826319298561L);
}
逻辑sql如下:

实际sql如下:

2.查询所有数据
查询car_id=1的数据,结果应该有10条:
@Test
public void selectUsers() {
QueryWrapper<User> q = new QueryWrapper<>();
q.eq("car_id", 1L);
userMapper.selectList(q);
}
逻辑sql如下,就是我们写的sql:

但是实际sql却执行了3条:
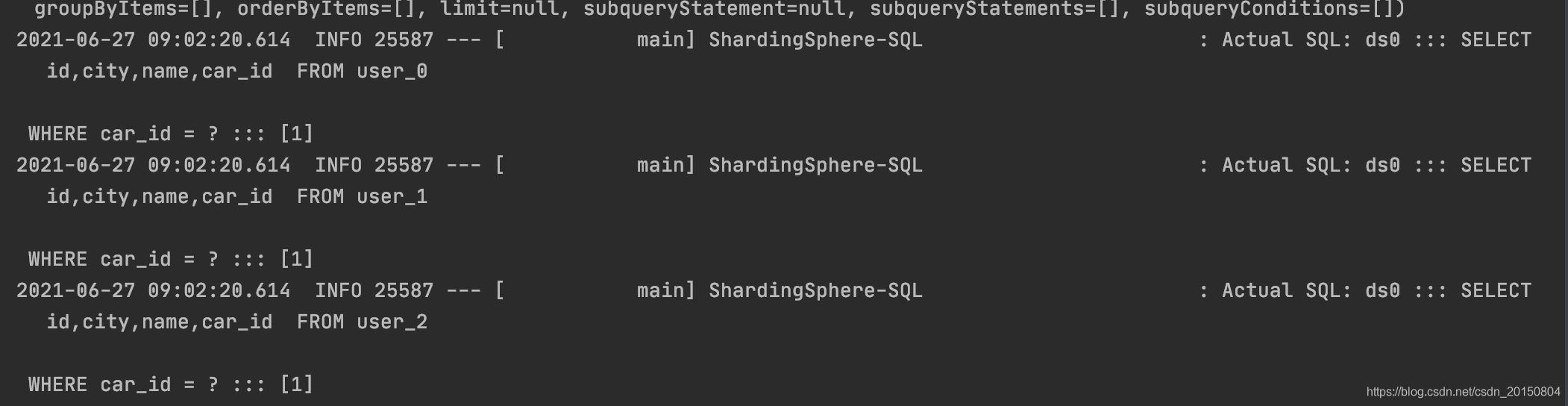
上述查询结果为预期的10条,sharding-jdbc去每个表都查询了carId=1的数据。
注意:
我们分表规则配置了3个user表,如果实际只有2个表,那么查询会报错,提示表不存在。
2.3.3 分页查询
表里总共10条数据,我们查询5条,并按照name字段排序,看看sql如何执行:
@Test
public void selectUsers() {
QueryWrapper<User> q = new QueryWrapper<>();
q.eq("car_id", 1L);
q.orderByAsc("name");
q.last("limit 5");
List<User> users = userMapper.selectList(q);
}
之际执行sql如下:
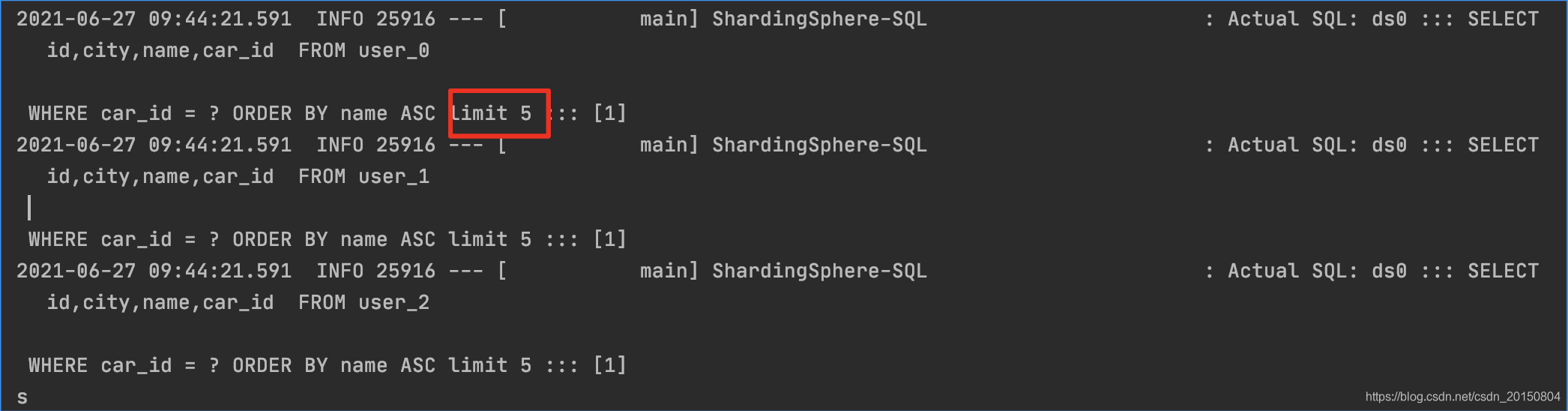
通过sql日志可以看出,sharding-jdbc是去每一张表都查询一页数据(5条),最后应该是使用这15条数据再次进行排序,最后筛选出5条。
实验到这里,我不禁怀疑,分表真的会提高查询效率吗,本来一次查询可以完成的,现在要查询多次;具体效率我们后续在测试吧,整体数据量大小决定了分表和不分表查询效率的不同。
2.3.4 使用mapper.xml
1.application.properties添加配置
##
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis-plus.mapper-locations=classpath:/mapper/xml/*Mapper.xml
mybatis-plus.typeAliasesPackage=com.example.sharding.entity
2.mapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.sharding.mapper.UserMapper">
<select id="getAllUsers" resultType="com.example.sharding.entity.User">
select * from user ;
</select>
</mapper>
3.结果
@Test
public void selectJoin() {
List<User> users = userMapper.getAllUsers();
}
上面我们搞了个最简单select查询,注意 表名是user,这样sharding-jdbc才能进行多表查询,如果写成具体的user_0,那实际就只能单独查询user_0.
查询结果如下:
2021-06-27 18:44:57.758 INFO 28649 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: select * from user_0 ;
2021-06-27 18:44:57.758 INFO 28649 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: select * from user_1 ;
2021-06-27 18:44:57.758 INFO 28649 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: select * from user_2 ;
<== Columns: id, city, name, car_id
<== Row: 1408951724490838017, 上海, 张三1, 1
<== Row: 1408951724503420929, 上海, 张三2, 1
<== Row: 1408951724516003841, 上海, 张三3, 1
<== Row: 1408951724562141186, 上海, 张三6, 1
<== Row: 1408951722368520193, 上海, 张三0, 1
<== Row: 1408951724570529793, 上海, 张三7, 1
<== Row: 1408808826319298561, 上海, 张三, 1
<== Row: 1408951724532781058, 上海, 张三4, 1
<== Row: 1408951724549558273, 上海, 张三5, 1
<== Row: 1408951724583112706, 上海, 张三8, 1
<== Total: 10
2.3.5 关联查询
1.xml sql
<select id="getUserVos" resultType="com.example.sharding.domain.vo.UserVO">
select u.* , c.name as carName from user u
left join car c on u.car_id=c.id
</select>
@Test
public void selectJoin() {
List<UserVO> users = userMapper.getUserVos();
}
2.结果如下:
2021-06-27 18:53:18.283 INFO 28688 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: select u.* , c.name as carName from user_0 u
left join car c on u.car_id=c.id
2021-06-27 18:53:18.283 INFO 28688 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: select u.* , c.name as carName from user_1 u
left join car c on u.car_id=c.id
2021-06-27 18:53:18.283 INFO 28688 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: select u.* , c.name as carName from user_2 u
left join car c on u.car_id=c.id
<== Columns: id, city, name, car_id, carName
<== Row: 1408951724490838017, 上海, 张三1, 1, 宝马
<== Row: 1408951724503420929, 上海, 张三2, 1, 宝马
<== Row: 1408951724516003841, 上海, 张三3, 1, 宝马
<== Row: 1408951724562141186, 上海, 张三6, 1, 宝马
<== Row: 1408951722368520193, 上海, 张三0, 1, 宝马
<== Row: 1408951724570529793, 上海, 张三7, 1, 宝马
<== Row: 1408808826319298561, 上海, 张三, 1, 宝马
<== Row: 1408951724532781058, 上海, 张三4, 1, 宝马
<== Row: 1408951724549558273, 上海, 张三5, 1, 宝马
<== Row: 1408951724583112706, 上海, 张三8, 1, 宝马
<== Total: 10
3.结果说明
从结果可以看出,join查询也是涉及3个表,每个表查询一次,最后把结果合并返回。
三.sharding-jdbc分库&&分表
上文中,我们只进行了分表操作,所有表在同一个数据库ds_0中,本节我们增加分库的内容。
3.1 项目环境准备
新增一个数据库ds_1,这样我们就有了两个库(两个库在同一个机器中与在多个机器上,效果一样),如下:

其他环境,比如项目工程和第二节一样。
3.2 application.properties
下面是分库分表完整配置:
#数据源名称(随便起名,如果有多个库,逗号隔开 ds0,ds1,ds2)
spring.shardingsphere.datasource.names=ds0,ds1
# 数据源ds0
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/ds_0?characterEncoding=utf-8
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
#数据源ds1
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/ds_1?characterEncoding=utf-8
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
#分库分表策略配置
##表名枚举,其中的user是需要分表的表名;ds$->{0..1}.user_$->{0..2} 其中ds$->{0..1}表示数据源从ds0到ds1;user_$->{0..2} 表示从user_0到user_2
spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds$->{0..1}.user_$->{0..2}
##分库路由策略,使用哪个字段作为路由规则
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=car_id
##分库路由策略,我们有2个库,使用car_id取余数2,余数0/1分别对于库ds0,ds1
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{car_id % 2}
##使用哪一列用作计算分表策略,我们就使用id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
##具体的分表路由策略,我们有3个user表,使用主键id取余3,余数0/1/2分表对应表user_0,user_2,user_2
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{id % 3}
##配置主键生成策略,因为多张表了,id不能在配置数据库自增,需要配置主键生成策略,user表主键名称是id
spring.shardingsphere.sharding.tables.user.key-generator.column=id
##id使用雪花算法,因为雪花算法生成的id具有全球唯一性,并且又有自增特性,适合mysql的innodb引擎
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
#允许一个entity实体对应多个表
spring.main.allow-bean-definition-overriding=true
#MybatisPlus配置
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis-plus.mapper-locations=classpath:/mapper/xml/*Mapper.xml
mybatis-plus.typeAliasesPackage=com.example.sharding.entity
说明:
以上配置大部分和单数据库多表配置是一样的,不同的部分是多了分库规则的配置,
区别如下:
1.数据源多了个ds1
#数据源名称(随便起名,如果有多个库,逗号隔开 ds0,ds1,ds2)
spring.shardingsphere.datasource.names=ds0,ds1
#!!!!数据源ds1
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/ds_1?characterEncoding=utf-8
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
2.多了分库策略配置
#分库分表策略配置
##!!!!表名枚举,其中的user是需要分表的表名;ds$->{0..1}.user_$->{0..2} 其中ds$->{0..1}表示数据源从ds0到ds1;user_$->{0..2} 表示从user_0到user_2
spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds$->{0..1}.user_$->{0..2}
##!!!!分库路由策略,使用哪个字段作为路由规则
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=car_id
##!!!!分库路由策略,我们有2个库,使用car_id取余数2,余数0/1分别对于库ds0,ds1
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{car_id % 2}
注意的是,用于分表的字段和分库的字段我们使用了俩字段,具体可以根据业务实际需求调整,一个也行。
3.3 分库测试demo
3.3.1 数据插入
因为分表的规则不变,这里我们主要是验证下分库的规则,
@Test
public void addUser() {
User user = new User();
user.setName("李四");
user.setCity("上海");
user.setCarId(3L);
userMapper.insert(user);
}
执行sql如下:
Actual SQL: ds1 ::: INSERT INTO user_2 (id, city, name, car_id) VALUES (?, ?, ?, ?) ::: [1409330347710259202, 上海, 李四, 3]
<== Updates: 1
从sql结果可以看出,最终查询的库是ds1,因为我们的分库规则是根据user表的car_id,这里car_id的值是3,取余2,结果是1,因此查询ds_1库。
3.3.2 数据查询
1.单条数据查询
@Test
public void selectUser() {
userMapper.selectById(1408808826319298561L);
}
执行sql如下:
INFO 37072 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: SELECT id,city,name,car_id FROM user_2 WHERE id=? ::: [1408808826319298561]
INFO 37072 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 ::: SELECT id,city,name,car_id FROM user_2 WHERE id=? ::: [1408808826319298561]
<== Columns: id, city, name, car_id
<== Row: 1408808826319298561, 上海, 张三, 1
<== Total: 1
因为指定了user的id,因此知道去user_2表查询,但是由于没指定分库的列值,因此两个库都查询了一遍,但是ds0库是查不到数据的。
2.查询所有user数据:
@Test
public void selectAllUsers() {
userMapper.getAllUsers();
}
执行sql如下:
11:11:40.654 INFO 37108 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: select * from user_0 ;
11:11:40.654 INFO 37108 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: select * from user_1 ;
11:11:40.654 INFO 37108 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: select * from user_2 ;
11:11:40.654 INFO 37108 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 ::: select * from user_0 ;
11:11:40.654 INFO 37108 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 ::: select * from user_1 ;
11:11:40.654 INFO 37108 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 ::: select * from user_2 ;
<== Columns: id, city, name, car_id
<== Row: 1408951724490838017, 上海, 张三1, 1
<== Row: 1408951724503420929, 上海, 张三2, 1
<== Row: 1408951724516003841, 上海, 张三3, 1
<== Row: 1408951724562141186, 上海, 张三6, 1
<== Row: 1408951722368520193, 上海, 张三0, 1
<== Row: 1408951724570529793, 上海, 张三7, 1
<== Row: 1408808826319298561, 上海, 张三, 1
<== Row: 1408951724532781058, 上海, 张三4, 1
<== Row: 1408951724549558273, 上海, 张三5, 1
<== Row: 1408951724583112706, 上海, 张三8, 1
<== Row: 1409330347710259202, 上海, 李四, 3
<== Total: 11
由于是查询所有数据,sharding-jdbc只能去2个库,每个库3个表,总共查询6次,最后把结果汇总。
本文就到这里。
最后有一点说明下,本文的路由规则使用了官方demo,也就是取余数的方式,这个不一定符合业务的实际需求,比如我想按照年分表,一年一个表,怎么整?
这个ShardingSphere是不支持配置的,需要我们自己去实现路由算法,具体操作就是实现如下接口:
PreciseShardingAlgorithm.java
RangeShardingAlgorithm.java
更多细节,后续在研究。