(3)、随机森林模型
随机森林属于一种集成算法,指的是利用多棵树对样本进行训练并预测的一种分类器。随机森林的混淆矩阵如表格 6所示。
表格 6
|
|
|
||
|
类=0 |
类=1 |
||
|
|
类=0 |
545(TP) |
498(FN) |
|
类=1 |
421(FP) |
1185(TN) |
|
随机森林的ROC曲线如图 9所示。
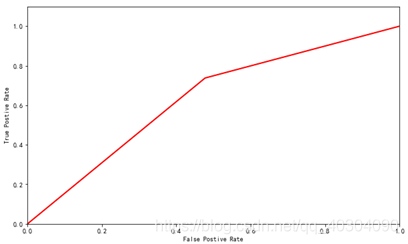
图 9
(4)、SVM模型
支持向量机(support vector machine,SVM)已经是一种备受关注的分类技术。这种技术具有坚实的统计学理论基础,并在许多实际应用(如手写数字的识别、文本分类等)中展示了大有可为的实践效用。此外,SVM可以很好地应用于高维数据,避免了维灾难问题。这种方法有个特点,它使用训练的一个子集来表示决策边界,该子集称为支持向量。
为了解释SVM的基本思想,需要了解最大边缘超平面的概念及选择它的基本原理;在线性可分的数据上怎样训练一个线性的SVM,从而明确地找到这种最大边缘超平面;将SVM方法扩展到非线性可分的数据上。本次SVM的混淆矩阵如表格 7所示。
表格 7
|
|
|
||
|
类=0 |
类=1 |
||
|
|
类=0 |
496(TP) |
547(FN) |
|
类=1 |
325(FP) |
1281(TN) |
|
SVM的ROC曲线如图 10所示。
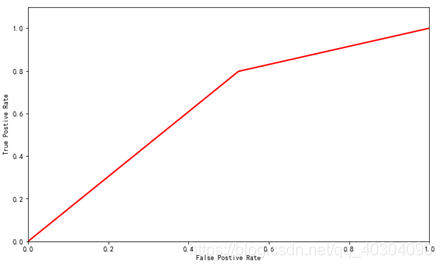
图 10
(5)、神经网络模型
神经网络主要包括:神经信息处理的基本原理、感知器、反向传播网络、自组织网络、递归网络、径向基函数网络、核函数方法、神经网络集成、模糊神经网络、概率神经网络、脉冲耦合神经网络、神经场理论、神经元集群以及神经计算机。神经网络是通过对人脑或生物神经网络的抽象和建模,它以脑科学和认知神经科学的研究成果为基础,拓展智能信息处理的方法,为解决复杂问题和智能控制提供有效的途径,是智能科学和计算智能的重要部分。
神经网络的混淆矩阵如表格 8所示。
表格 8
|
|
|
||
|
类=0 |
类=1 |
||
|
|
类=0 |
548(TP) |
495(FN) |
|
类=1 |
360(FP) |
1246(TN) |
|
神经网络的ROC曲线如图 11所示。
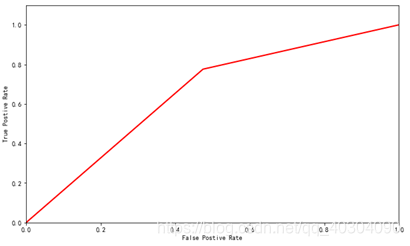
图 11
(6)、KNN分类模型
邻近算法,或者说K最近邻(kNN,k-Nearest Neighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。近朱者赤,近墨者黑。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最近邻)的样本中大多数属于某个类别,则该样本也属于这个类别。
kNN算法虽然从原理上依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于kNN算法主要依靠有限的邻近样本,而不是靠判别类域的方法来确定所属类别,因此对于类域的交叉或重叠较多的待分样本集来说,kNN算法比其他算法更合适。
行业应用:客户流失预测、图像识别、欺诈侦测等(更适合于稀有事件的分类问题)。
KNN的K的选择对于KNN模型的效果影响最大,这里将K从1到30进行建模,图 12可以看出选择K为10时,模型效果可以达到最佳。
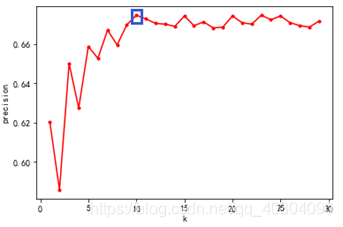
图 12
KNN的混淆矩阵如表格 9所示。
表格 9
|
|
|
||
|
类=0 |
类=1 |
||
|
|
类=0 |
609(TP) |
434(FN) |
|
类=1 |
428(FP) |
1178(TN) |
|
KNN的ROC曲线如图 13所示。
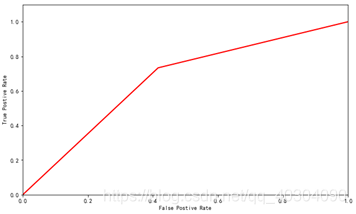
图 13
4.2 模型结果对比分析
在通过聚类算法和各种分类算法构建用户流失模型之后,模型的评价指标如表格 10所示。里面分别计算了它们的准确率、精确率、召回率和F1值。
表格 10
|
|
|
|
|
|
|
kmean聚类 |
58.73 |
None |
None |
None |
|
决策树 |
68.02 |
71.48 |
78.64 |
74.89 |
|
随机森林 |
65.31 |
70.41 |
73.79 |
72.06 |
|
SVM |
67.08 |
70.08 |
79.76 |
74.61 |
|
神经网络 |
67.72 |
71.57 |
77.58 |
74.45 |
|
KNN分类(K=13) |
67.46 |
73.08 |
73.35 |
73.21 |
同时计算各个模型的ROC曲线下的面积AUC :假设总共有(m+n)个样本,其中正样本m个,负样本n个,总共有m*n个样本对,正样本预测为正样本的概率值大于负样本预测为正样本的概率值记为1,累加计数,然后除以(m*n)。发现各模型的AUC 均在AUC在0.7~0.8之间,都有一定准确性。
综合比较后,得出决策树算法模型更合适后续的应用实现。
Python用户流失系列文章一月一更!
文章未经博主同意,禁止转载!
