redis是一个内存数据库,因此不可能出现内存中找不到,磁盘中找到的情况,
是一个key-value型数据库
柔性数组,创建时不占用空间,不需要单独free :char buf[] ;s = malloc(sizeof(struct buf) + 64);free(s – sizeof(struct buf))
提供了非常丰富的数据接口,常用的string(二进制安全字符串,不以\0作为结尾)、list(双向链表,插入有序性)、hash、zset(有序)、set(无序,唯一)
zset底层使用跳表实现,set如果存储的是字符串,使用hash实现
redis pipeline 阻塞io 先组成好的数据包先执行,按执行顺序返回
acid:原子性,一致性,隔离性,持久性
数据内容一致性、数据类型一致性,redis里调用lua脚本,不满足一致性和持久性
线上redis使用scan命令遍历,
因为keys *会造成阻塞
scan采用二进制高位进位加法的方法进行遍历,确保在扩缩容时不重复,不遗漏的遍历
1000 -> 0100 -> 1100 -> 0010…
redis有16个db,可以用select选择
redis高效的原因
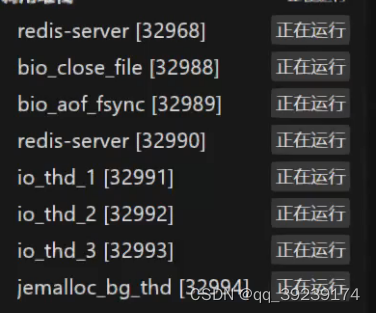
bio_close_file 后台关闭文件,文件过大时启用这个线程关闭文件
bio_aof_fsync 异步刷盘,持久化
jemalloc_bg_thd 异步管理大块内存
单线程是指 命令的处理是在一个线程中
redis-server是主线程,耗时的操作在别的线程中运行,数据结构高效,根据不同的情况进行切换,执行效率与空间占用保持平衡
是一个内存数据库,对内存的操作远比对磁盘的操作要快
为什么不采用多线程:加锁复杂,粒度不好控制,多线程涉及到线程的调度和CPU的上下文切换,没有了单线程的优势
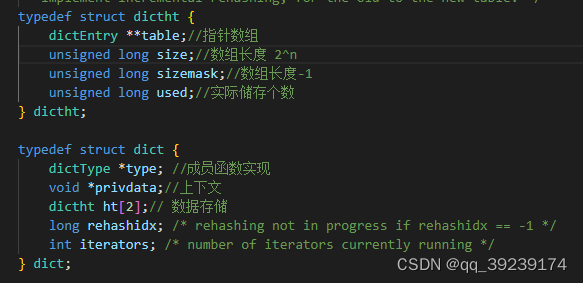
寻址方式:hash(key)%size = index;因为取余要用到除法运算,为提高效率,优化成 hash(key)&sizemask
ht[2],当负载因子大于或者小于指定值时,会发生扩容或者缩容,哈希的算法发生改变,需要进行rehash,数据量大时,一次性rehash会造成线程的阻塞,所以采用
渐进式rehash
,ht[1]直接翻倍,ht[0]的索引分批rehash到ht[1],rehash完成之后,释放ht[0]
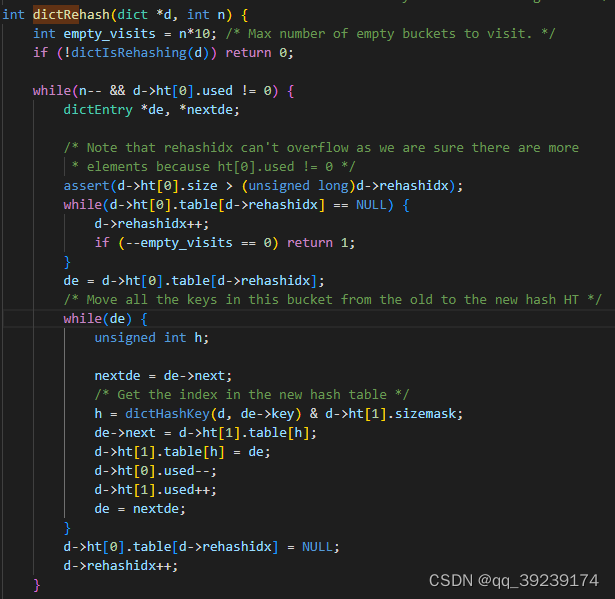
渐进式rehash有两种方式,
按槽位进行:在对dict增删改查的时候rehash一个槽位,适合在cpu密集的场景下使用
按时间进行:采用定时器对数据进行操作,每次操作执行一定时间