一、实验目的
KNN分类法是最简单的机器学习算法之一,可以用于分类和回归,是一种监督学习算法。朴素贝叶斯是一种基于概率理论的分类算法,以贝叶斯理论为理论基础,通过计算记录归属于不同类别的概率来进行分类,是一种经典的分类算法。本实验主要目的是培养学生能够掌握KNN和朴素贝叶斯,并用python程序实现KNN和朴素贝叶斯分类算法,在iris数据进行训练,并对测试记录进行分类。
二、实验要求
学习掌握数据分类方法中的KNN分类法和朴素贝叶斯分类法。
三、实验内容
不通过调用相关接口,动手实现KNN和朴素贝叶斯分类方法
。具体包括:
读取iris.csv数据集的函数;
将iris.csv数据集中的字符串型特征转换为浮点型,将字符串型类别转换为整型;
设计实现K折交叉验证;
使用5折交叉验证评估KNN算法(邻近性度量使用欧氏距离,最近邻的个数取5)和朴素贝叶斯算法(使用高斯概率密度函数估计条件概率)的准确率性能;
分别用训练好的KNN和朴素贝叶斯算法预测未知类别记录[5.7, 2.9, 4.2, 1.3]的类标号。
四、实验结果及分析
-
导入包
import csv
from collections import Counter
import numpy as np
import pandas as pd
from sklearn.model_selection import KFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.utils import shuffle-
KNN算法
# KNN算法
def classify(inX, dataSet, labels, k):
m, n = dataSet.shape # shape(m, n)m列n个特征
# 计算测试数据到每个点的欧式距离
distances = []
for i in range(m):
sum = 0
for j in range(n):
sum += (inX[j] - dataSet[i][j]) ** 2
distances.append(sum ** 0.5)
sortDist = sorted(distances)
# k 个最近的值所属的类别
classCount = {}
for i in range(k):
voteLabel = labels[distances.index(sortDist[i])]
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1 # 0:map default
sortedClass = sorted(classCount.items(), key=lambda d: d[1], reverse=True)
return sortedClass[0][0]-
朴素贝叶斯
# 朴素贝叶斯
class NaiveBayes:
def __init__(self, lamb=1):
self.lamb = lamb
self.prior = dict()
self.conditional = dict()
def training(self, features, target):
features = np.array(features)
target = np.array(target).reshape(features.shape[0], 1)
n, m = features.shape
labels = Counter(target.flatten().tolist()) # 计算各类别的样本个数
k = len(labels.keys()) # 类比个数
for label, amount in labels.items():
self.prior[label] = (amount + self.lamb) / (m + k * self.lamb) # 计算平滑处理后的先验概率
for feature in range(m): # 遍历每个特征
self.conditional[feature] = {}
values = np.unique(features[:, feature])
for value in values: # 遍历每个特征值
self.conditional[feature][value] = {}
for label, amount in labels.items(): # 遍历每种类别
feature_label = features[target[:, 0] == label, :] # 截取类别的数据集
c_label = Counter(feature_label[:, feature].flatten().tolist()) # 计算该类别下各特征值出现的次数
self.conditional[feature][value][label] = (c_label.get(value, 0) + self.lamb) / \
(amount + len(values) * self.lamb)
return
def predict(self, features):
best_poster, best_label = -np.inf, -1
for label in self.prior:
poster = np.log(self.prior[label])
for feature in range(features.shape[0]):
poster += np.log(self.conditional[feature][features[feature]][label])
if poster > best_poster:
best_poster = poster
best_label = label
return best_label-
主函数
-
读取文件
if __name__ == '__main__':
with open('./iris.csv') as f: # 读取文件
f_csv = csv.reader(f)
x = []
d = open('./iris2.csv', 'w')
d.close()
for row in f_csv:
row[0] = float(row[0].strip())
row[1] = float(row[1].strip())
row[2] = float(row[2].strip())
row[3] = float(row[3].strip())
if row[4] == 'Iris-setosa':
row[4] = 1
if row[4] == 'Iris-versicolor':
row[4] = 2
if row[4] == 'Iris-virginica':
row[4] = 3
with open('./iris2.csv', 'a', encoding='UTF8', newline='') as d:
writer = csv.writer(d)
writer.writerow(row)
f.close()-
使用5折交叉验证评估KNN算法的准确率性能:
inputfile = './iris2.csv'
data = pd.read_csv(inputfile, header=None)
x = data.iloc[:, :4].values.astype(float)
y = data.iloc[:, 4].values.astype(int)
# knn算法进行比对,使用三角形
r = classify([5.7, 2.9, 4.2, 1.3], x, y, 3)
print('KNN算法归类为:', r)
# knn算法的5折交叉验证
ks = [1, 3, 5, 7, 9, 11, 13, 15]
kf = KFold(n_splits=5, random_state=2001, shuffle=True)
# 保存当前最好的K值和对应的准确值
best_k = ks[0]
best_score = 0
# 循环每一个K值
for k in ks:
curr_score = 0
for train_index, valid_index in kf.split(x):
# 每一折的训练以及计算准确率
clf = KNeighborsClassifier(n_neighbors=k)
clf.fit(x[train_index], y[train_index])
curr_score = curr_score + clf.score(x[valid_index], y[valid_index])
# 求5折的平均准确率
avg_score = curr_score / 5
if avg_score > best_score:
best_k = k
best_score = avg_score
print("现在的最佳准确率:%.2f" % best_score, "现在的最佳K值 %d" % best_k)
print("最终最佳准确率:%.2f" % best_score, "最终的最佳K值 %d" % best_k)-
使用5折交叉验证评估朴素贝叶斯的准确率性能:
# 朴素贝叶斯进行比对
data = shuffle(data) # 打乱数据
features = data.iloc[:, :-1].values.astype(float)
target = data.iloc[:, -1:].values.astype(int)
nb = NaiveBayes()
nb.training(features, target)
prediction = []-
用训练好的KNN和朴素贝叶斯算法预测未知类别记录[5.7, 2.9, 4.2, 1.3]的类标号
result = nb.predict(np.array([5.7, 2.9, 4.2, 1.3])) # 预测数据结果
print('朴素贝叶斯归类为:', result)
for features in features:
prediction.append(nb.predict(features))
correct = [1 if a == b else 0 for a, b in zip(prediction, target)]
print('朴素贝叶斯准确率为:', correct.count(1) / len(correct)) # 计算准确率-
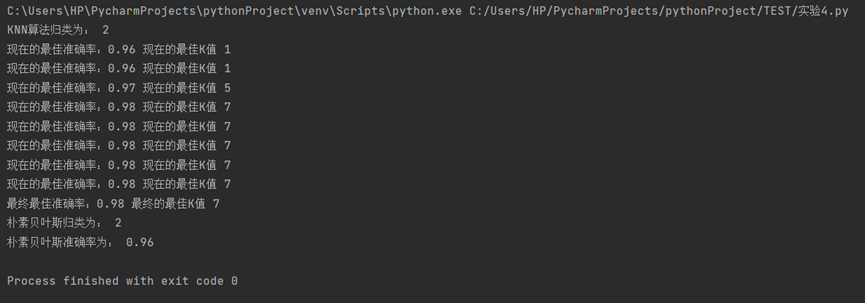
运行结果:
版权声明:本文为qq_56699753原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。