最近也在系统化的学习数据结构,今天就分享下自己的一些学习心得,希望对大家有帮助;
首先我们先讨论下(虚拟数据类型)链表存在的意义
相比于链表首先想到的便是数组,作为同样都是顺序表,他们最大区别便是内存是否连续,
这里贴一张素组与链表的图片,很明显数组的内存地址是连续的,而链表更像是一个个的岛屿,通过指针联系起来的,而其内存地址很明显不连续;
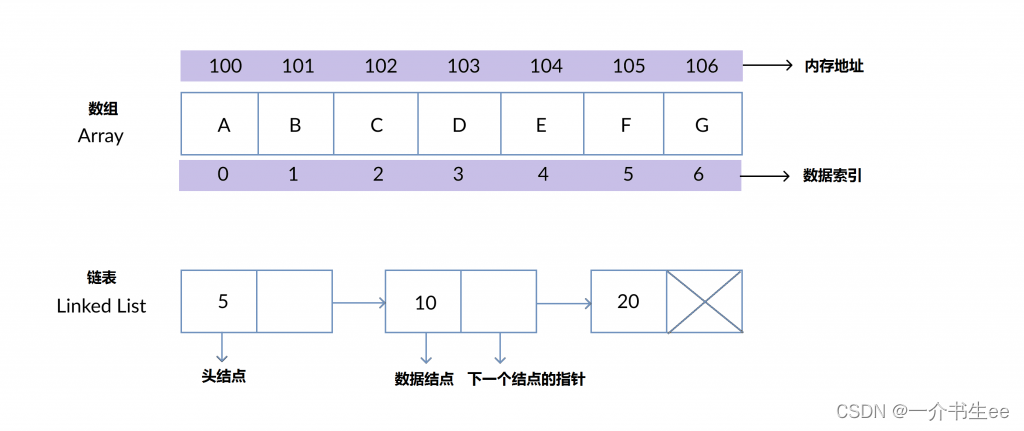
对于数组中的每个元素,我们只要知道首元素地址,实际就是数组地址,我们就可以array[i],来找到任意元素,因为每一个元素都是一个挨着一个,那么访问任意元素的时间复杂度便是O(1);
而链表的数据结构形式如下
typedef struct Node {
int data;
struct Node * next;
}Node;
其中有两个域,包括数据域和指针域,这个指针就是指向下一个节点;
那比如访问上面链表20的元素,就需要先根据头节点找到数据5,在向后遍历找到10,在向后遍历找到20,其访问数据需要一个接着一个的访问,那么最坏的情况下我需要遍历整个链表,因此时间复杂度为O(N);
由此可见对于元素的访问数组的方便程度是要大于链表的,而且链表的实现还要麻烦为什么要有链表呢?
实际上链表和数组都是各有优势,比如我需要申请一个内存存放一组数据,但是我不知道这组数据有多长,而我们在C中声明一个数组需要指定他的大小,下边的数组申请是
编译不通过
的;
#include <stdio.h>
#include <stdlib.h>
int main (int argc , char *argv[]){
len = atoi(argv[1]);
int arr[len];
}
当然有同学可能会想到动态内存申请,当然这样是可以实现的,但是我们这里先讨论链表,
那我们初始化链表时候可以不指定他的大小
typedef struct Node {
int data;
struct Node * next;
}Node;
Node * initList(void){
Node *list = (Node *)malloc(sizeof(Node));
list->data = 0;
list->next = list;
return list;
}
int main (void){
Node * L = initList();
}
像这样初始化链表,会给我返回一个Node类型的指针,然后调用下边的函数进行插入节点。
void headInsert(Node *list , int data){
Node *node = (Node *)malloc(sizeof(Node));
node->data = data;
node->next = list->next;
list->next = node;
list->data ++;
}
void tailInsert(Node *list , int data){
Node *node = (Node *)malloc(sizeof(Node));
node->data = data;
Node *temp = list;
while(temp->next != list){
temp = temp->next;
}
node->next = temp->next;
temp->next = node;
list->data ++;
}
void printfList(Node *list){
Node *temp = list;
temp = temp->next;
while(temp != list){
printf("%d -> ",temp->data);
temp = temp->next;
}
printf("Head\n");
printf("node num:%d\n",list->data);
}
int deletList(Node *list , int data){
Node *temp = list->next;
Node *ptr = list;
while(temp != list ){
if(temp->data == data){
ptr->next = temp->next;
free(temp);
list->data --;
return 0;
}
ptr = temp;
temp = temp->next;
}
return -1;
}
由此链表的的大小是可以实现动态的,如果我想继续向链表里面放数据,只需要插入一个节点便可以,他相比于数据是有很大优势的,
一个数组我当然可以向里面写入数据,但是数组大小是固定的,一旦超出了数组的大小,我就需要去创建一个更大的数组,然后吧数组里面的数据拷贝到新的数组里面去,这些操作是我们不希望看到的
;
另外,如果我们删除数组中的任意元素,因为数组需要保持连续性,比如我删除索引2位置的数据,那么就需要索引2 – 索引结尾的数据依次向前移动,同样添加也是,因此删除和添加对于
数组时间复杂度实际O( N )
;而链表的头插法只需要移动相应的指针便可,
链表的插入删除时间复杂度为O( 1 )
;
因此数组和链表他们各有优缺点:
数组 :优点:
特性上内存连续 访问方便直接arr [ i ] 便可访问某一元素
缺点:
插入和删除不方便,需要删除后任然保持内存的连续性,因此需要移动索引后 面的所有元素
链表:优点:
特性上内存不连续,有更高的内存利用率,插入和删除比较方便,只需要移动 相应指针
缺点:
创建起来没有数组那么方便,访问某一元素需要从头依次遍历,才能找到指定 的元素,最坏的情况下需要遍历整个链表
ok 这便是本次全部的内容了,下次会给大家讨论下程序运行时内存是如何变化的,能够更加理解栈区,静态区,堆区;