用scrapy框架实现对网页的爬取:
实现的步骤:
1.使用cmd命令行找到你要搭建框架的目录下
2.在cmd命令行中输入scrapy startproject +你想要的项目名
3.在cmd命令行中输入scrapy +genspider + 你想要的主程序名 + 你想要爬取的网站名
这样系统就会给你搭建一个scrapy框架
4.当框架搭建好后 使用浏览器的F12 功能找原网页的代码
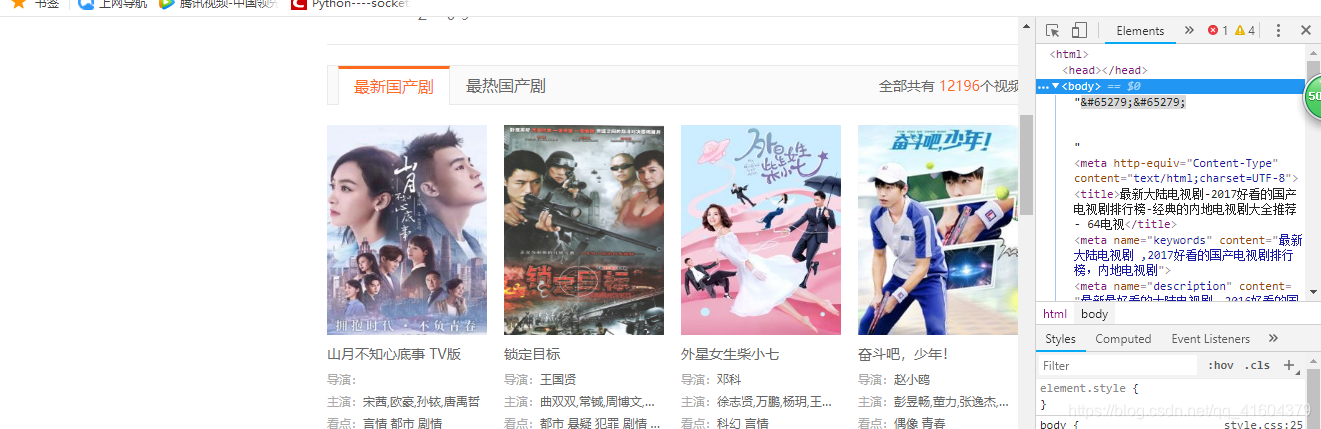
像这样一样寻找你要的数据代码
5.然后用
movieitems = response.xpath("//ul[@class='fcb-ul fcb-ul4']/li")
response.xpath这样找到选择器
提取你需要的数据
6.用系统的提供的item方法把你的数据封装
class SpidertaobaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moviename = scrapy.Field()
moviedirect = scrapy.Field()
movieact = scrapy.Field()
movielook = scrapy.Field()
movie_state = scrapy.Field()
nextUrl = scrapy.Field()
# movie_state = scrapy.Field()
task_id = scrapy.Field()
pass
```前面的名字为key值 把你所需要的数据封装成了字典
7.在主程序中使用你的封装类,把你所封装的数据通过yield生成器返回给系统给你提供的管道
8通过管道传给数据库
上面就是使用scrapy框架完成网页爬取到数据库的基本步骤
源代码:
主程序:
# -*- coding: utf-8 -*-
import scrapy
from Project.day23.spidertaobao.spidertaobao.items import SpidertaobaoItem
count = 0
class TaobaospiderSpider(scrapy.Spider):
name = 'taobaospider'
# allowed_domains = ['https://www.64ds.com/move9/']
# start_urls = ['https://www.64ds.com/move9/']
start_urls = []
def __init__(self, start_urls=None, taskid=0, *args, **kwargs):
super(TaobaospiderSpider, self).__init__(*args, **kwargs)
self.start_urls.append(start_urls)
self.taskid = taskid
pass
def parse(self, response):
global count
movieitems = response.xpath("//ul[@class='fcb-ul fcb-ul4']/li")
print(movieitems)
movielen = len(movieitems)
movcount = 0
for movie in movieitems:
movcount+=1
sItem = SpidertaobaoItem()
sItem['task_id']=self.taskid
moviename = movie.xpath("div[@class='movie-headline1']/a/text()").extract()
if moviename:
sItem['moviename']=moviename
moviedirec = movie.xpath("p")
if movcount==1:
detailUrl = movie.xpath("a/@href")
for item in moviedirec:
if count==0:
item.xpath('span/text()').extract()
moviedirect=item.xpath('text()').extract()
sItem['moviedirect'] = moviedirect
count+=1
elif count==1:
item.xpath('span/text()').extract()
movieact=item.xpath('text()').extract()
sItem['movieact']=movieact
count+=1
elif count==2:
item.xpath('span/text()').extract()
movielook = item.xpath('a/text()').extract()
sItem['movielook'] = movielook
count=0
nextUrl = response.xpath("//li/a[@class='next pagegbk']/@href").extract()
nextText =response.xpath("//li/a[@class='next pagegbk']/text()").extract()
if nextUrl[0] and nextText[0].strip() =='下一页':
url = response.urljoin(nextUrl[0])
sItem['nextUrl'] = url
detailURL = detailUrl.extract()
# print(item.xpath('span/text()').extract())
# print(item.xpath('text()').extract())
# print(item.xpath('a/text()').extract())
detailURL = 'https://www.64ds.com' + detailURL[0]
yield scrapy.Request(url=detailURL, callback=self.parseDetail,
meta={'item': sItem, 'movielen': movielen, 'movcount': movcount}, dont_filter=True)
def parseDetail(self,response):
sItem = response.meta['item']
movielen = response.meta['movielen']
movcount = response.meta['movcount']
movie_state = response.xpath("//div[@class='vod_t']/text()").extract()
sItem['movie_state'] = movie_state
if sItem:
yield sItem
print(movielen, movcount)
print(movielen == movcount)
if movielen == movcount:
if sItem['nextUrl']:
yield scrapy.Request(sItem['nextUrl'], self.parse, dont_filter=True)
dao层:
BaseDao:
#引入pymysql
import pymysql
import json
import logging
class BaseDao():#DAO:database access object
def __init__(self,configPath='pymysql.json'):
self.__connection = None
self.__cursor = None
self.__config = json.load(open(configPath,'r'))#通过json配置文件获得数据库的连接信息
print(self.__config)
pass
#获取数据库连接
def getConnection(self):
#当有连接对象是返回连接对象
if self.__connection:
return self.__connection
#否则建立新的连接对象
#获得数据库连接
try:
self.__connection=pymysql.connect(**self.__config)
return self.__connection
except pymysql.MySQLError as e:
print('Exception:',e)
#执行SQL语句的通用方法,#sql注入
def execute(self,sql,params):
try:
self.__cursor = self.getConnection().cursor()
result = self.__cursor.execute(sql,params)
return result
except (pymysql.MySQLError, pymysql.DatabaseError,Exception) as e:
print('出现数据库异常:'+str(e))
self.rollback()
def fetch(self):
if self.__cursor:
return self.__cursor.fetchall()
pass
def commit(self):
if self.__cursor:
self.__connection.commit()
def rollback(self):
if self.__cursor:
self.__connection.rollback()
def close(self):
if self.__cursor:
self.__cursor.close()
if self.__connection:
self.__connection.close()
def getLastRowId(self):
if self.__cursor:
return self.__cursor.lastrowid
pass
MovieDao:
#引入pymysql
import pymysql
import json
import logging
class BaseDao():#DAO:database access object
def __init__(self,configPath='pymysql.json'):
self.__connection = None
self.__cursor = None
self.__config = json.load(open(configPath,'r'))#通过json配置文件获得数据库的连接信息
print(self.__config)
pass
#获取数据库连接
def getConnection(self):
#当有连接对象是返回连接对象
if self.__connection:
return self.__connection
#否则建立新的连接对象
#获得数据库连接
try:
self.__connection=pymysql.connect(**self.__config)
return self.__connection
except pymysql.MySQLError as e:
print('Exception:',e)
#执行SQL语句的通用方法,#sql注入
def execute(self,sql,params):
try:
self.__cursor = self.getConnection().cursor()
result = self.__cursor.execute(sql,params)
return result
except (pymysql.MySQLError, pymysql.DatabaseError,Exception) as e:
print('出现数据库异常:'+str(e))
self.rollback()
def fetch(self):
if self.__cursor:
return self.__cursor.fetchall()
pass
def commit(self):
if self.__cursor:
self.__connection.commit()
def rollback(self):
if self.__cursor:
self.__connection.rollback()
def close(self):
if self.__cursor:
self.__cursor.close()
if self.__connection:
self.__connection.close()
def getLastRowId(self):
if self.__cursor:
return self.__cursor.lastrowid
pass
taskDao:
from .basedao import BaseDao
class TaskDao(BaseDao):
def create(self,params):
sql = 'insert into movie_task(task_title,task_url) values (%s,%s)'
result=self.execute(sql,params)
lastRowId = self.getLastRowId()
self.commit()
self.close()
return result,lastRowId
pass
pass
管道:
from .dao.moviedao import MovieDao
class Spiderershouche(object):
def process_item(self, item, spider):
print('管道输出'+str(item['moviename']))
print(item['moviedirect'])
print(item['movieact'])
print(item['movielook'])
mo = MovieDao()
result,lastrowid = mo.create((str(item['moviename']).replace('[','').replace(']', '').replace('\'',''),str(item['moviedirect']).replace('[','').replace(']', '').replace('\'',''),str(item['movieact']).replace('[','').replace(']', '').replace('\'',''),str(item['movielook']).replace('[','').replace(']', '').replace('\'','')))
mo.create1((str(item['movie_state']).replace('[','').replace(']', '').replace('\'','').replace('r','').replace('n','').replace('\\',''),lastrowid))
mo.close()
return item
输出程序:
#脚本是爬虫启动脚本
from scrapy.cmdline import execute
from Project.day23.spidertaobao.spidertaobao.dao.taskdao import TaskDao
#启动爬虫
td = TaskDao()
result,teskId = td.create(('最新大陆电视剧采集','https://www.64ds.com/move9/'))
if result:
execute(['scarpy','crawl','taobaospider',
'-a','start_urls=https://www.64ds.com/move9/',
'-a','taskid='+str(teskId)])
版权声明:本文为qq_41604379原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。