一、安装
1、环境准备:
- 环境变量配置:
export JAVA_HOME=/usr/share/java/jdk1.8.0_131
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export HADOOP_HOME=/usr/hdp/3.1.0.0-78/hadoop/
export HADOOP_CONF=/usr/hdp/3.1.0.0-78/hadoop/conf
export PATH=$HADOOP_HOME/bin:$PATH
export HADOOP_CLASSPATH=`${
HADOOP_HOME}/bin/hadoop classpath`
- ssh配置
- flink的安装包:flink-1.10.0-bin-scala_2.12.tgz
2、安装
1、standalone模式
- 集群规划:daas4(master),daas5(slave),daas6(slave)
- 解压:`tar -zxvf flink-1.10.0-bin-scala_2.12.tgz
- 修改配置文件:
vi $FLINK_HOME/conf/flink-conf.yaml
#设置jm的地址
jobmanager.rpc.address: daas4
#修改目录的输出位置
env.log.dir: /var/log/flink
vi $FLINK_HOME/conf/master
daas4
vi $FLINK_HOME/conf/slaves
daas5
daas6
- 启动及关闭
启动:./bin/start-cluster.sh
停止:./bin/stop-cluster.sh
-
测试
(1)离线测试
准备测试数据:
因为是集群模式,所以任务可能在daas5或者daas6上执行,两台机器都要有/data/word.txt.或者上传到hdfs上。
运行命令:
$FLINK_HOME/bin/flink run $FLINK_HOME/examples/batch/WordCount.jar –input /data/word.txt –output /data/out.txt
(2)实时测试:
准备测试数据:daas6上 nc -l 9999产生数据
运行命令:
$FLINK_HOME/bin/flink run $FLINK_HOME/examples/streaming/SocketWindowWordCount.jar –host daas6 –port 9999
结果查看:webUI访问:daas4:8081


-
内部提交流程:

- client客户端提交任务给JobManager
- JobManager负责Flink集群计算资源管理,并分发任务给TaskManager执行
- TaskManager定期向JobManager汇报状态
-
如果需要配置HA
修改配置文件:
vi $FLINK_HOME/conf/flink-conf.yaml
high-availability: zookeeper
high-availability.zookeeper.quorum: daas3:2181,daas4:2181,daas5:2181
high-availability.storageDir: hdfs://daas/flink/recovery
执行流程:

-
容错配置 checkpoint & savepoint
修改配置文件:
vi $FLINK_HOME/conf/flink-conf.yaml
state.backend: rocksdb
#存储检查点的数据文件和元数据的默认目录
state.backend.fs.checkpointdir: hdfs://daas/flink/pointsdata/
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
# relative path is better for change your cluster
state.checkpoints.dir: hdfs://daas/flink/checkpoints/
# Default target directory for savepoints, optional.
#
#state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints
state.savepoints.dir: hdfs://daas/flink/savepoints/
#
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#开启增量checkpoint 全局有效
state.backend.incremental: true
#保存最近检查点的数量
state.checkpoints.num-retained: 3
2、yarn模式
准备工作:
需要将依赖hadoop的jar包及其他jar包放到flink/lib目录下
flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
以下三个jar包可以重新编译上面的hadoop包加入依赖,也可以直接加到flink的lib下
jersey-client-1.9.jar
jersey-common-2.9.jar
jersey-core-1.9.jar
运行在yarn上有两种方式:session与per-job方式
2.1 session 方式

共享dispatcher和resourceManager,共享资源即taskManager,适合规模小,执行时间较短的job.
使用步骤:
1、开启yarn-session ./bin/yarn-session.sh -n 2 -tm 800 -s 1
参数说明:
yarn-session.sh脚本可以携带的参数:
Required
-n,--container <arg> 分配多少个yarn容器 (=taskmanager的数量)
Optional
-D <arg> 动态属性
-d,--detached 会自己关闭cient客户端
-jm,--jobManagerMemory <arg> JobManager的内存 [in MB]
-nm,--name 在YARN上为一个自定义的应用设置一个名字
-at,--applicationType Set a custom application type on YARN
-q,--query 显示yarn中可用的资源 (内存, cpu核数)
-qu,--queue <arg> 指定YARN队列
-s,--slots <arg> 每个TaskManager使用的slots数量
-tm,--taskManagerMemory <arg> 每个TaskManager的内存 [in MB]
-z,--zookeeperNamespace <arg> 针对HA模式在zookeeper上创建NameSpace
开启后下面会显示jobmanager启动的位置,用于下面的任务提交:
2、准备数据:daas6: nc -l 9999
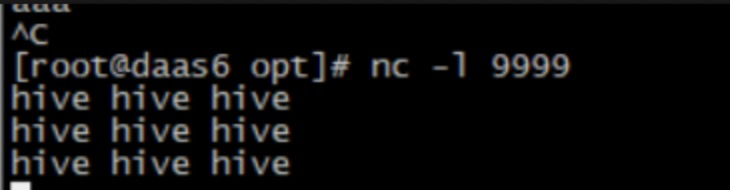
3、提交任务:
$FLINK_HOME/bin/flink run -m daas6:38037 $FLINK_HOME/examples/streaming/SocketWindowWordCount.jar –host daas6 –port 9999

4、查看结果:

2.2 Per-job方式:

独享dispatcher和resourceManager,独享资源即taskManager,适合执行时间长的大job.
使用步骤:
1、 测试数据:socket发送消息:nc -l 9999
2、提交任务:/var/opt/flink/bin/flink run -m yarn-cluster -d /var/opt/flink/examples/streaming/SocketWindowWordCount.jar –host daas6 –port 9999
4、查看结果:

5、关闭任务:
echo “stop” | ./bin/yarn-session.sh -id
2.3 内部运行流程:

- 检查资源是否存在,上传jar包和配置文件到HDFS集群上
- 申请资源和请求AppMaster容器
-
Yarn分配资源AppMaster容器,并启动JobManager
• JobManager和ApplicationMaster运行在同一个container上。
• 一旦他们被成功启动,AppMaster就知道JobManager的地址(AM它自己所在的机器)。
• 它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager)。
• 这个配置文件也被上传到HDFS上。
• 此外,AppMaster容器也提供了Flink的web服务接口。YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink - 申请worker资源,启动TaskManager
-
拓展:flink内部流程


二、Flink的应用(主要为flink sql)
1、sql-client方式:
-
准备数据:/data/video.csv
-
准备启动的环境配置文件:也可以不配置,将sql直接写在sql-client中

- 启动sql-client: ./bin/sql-client.sh embedded -e ./envConf/myTab.yaml
- 执行语句:select * from video_search;
-
查看结果:

2、JAVA API方式
2.1 准备测试数据:生成数据,发送到kafka的topic
pom.xml依赖如下:
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.1</version>
</dependency