论文题目:
Unifified Structure Generation for Universal Information Extraction
论文:
https://arxiv.org/pdf/2203.12277.pdf
代码:
https://github.com/universal-ie/UIE
本文
创新点
:
- 提出了一个
统一的text-to-structure生成架构
,可以对不同的信息抽取(IE)任务进行建模,自适应地生成目标结构,并从不同的知识资源学习通用的信息抽取能力。是第一个text-to-structure预训练抽取模型。- 设计了一个
统一的结构生成网络
,通过结构抽取语言(structural extraction language)将异构的信息抽取结构编码成统一的表示,并通过结构模式(structural schema instructor)指导机制控制UIE模型的识别、关联和生成。
不同的IE任务可以分解为一系列原子文本到结构的转换,所有IE模型共享相同的底层发现和关联能力。
- 为了对异构IE结构进行建模,论文设计了一种结构提取语言(SEL),该语言可以有效地将不同的IE结构编码为统一的表示,从而可以在相同的文本到结构生成框架中对各种IE任务进行通用建模。
设计结构化提取语言(
SEL
):将实体、关系、事件编码为统一表示。

- 为了自适应地为不同的IE任务生成目标结构,论文提出了结构模式指导器(SSI),这是一种基于模式的prompt机制,用于控制UIE中要发现的内容、要关联的内容以及要生成的内容。
结构模式指导器(SSI)
,这是一种基于模式(schema)的提示(prompt)机制,用于控制不同的生成需求:
在Text前拼接上相应的Schema Prompt
,输出相应的SEL结构语言。
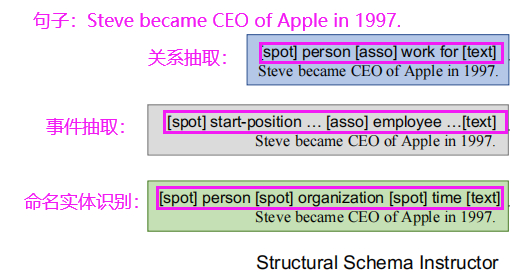
经过转化,a中的各个任务就可以结构化为b中的格式。
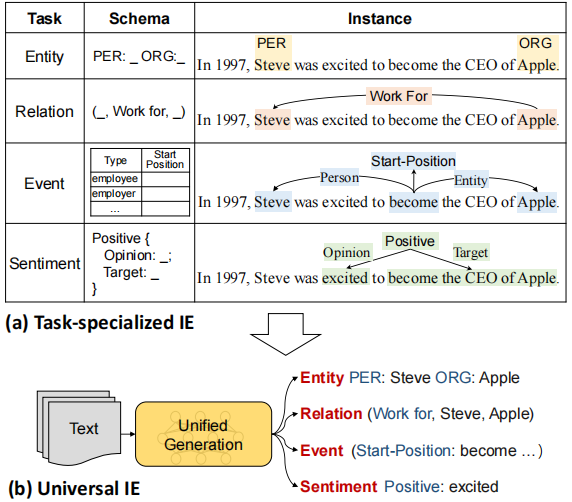
UIE的整体框架为:

本文在13个IE基准上进行了实验,涉及4个很有代表性的IE任务(包括实体提取、关系提取、事件提取、结构化情感提取)及其组合(例如,联合实体-关系提取)。结果如下:
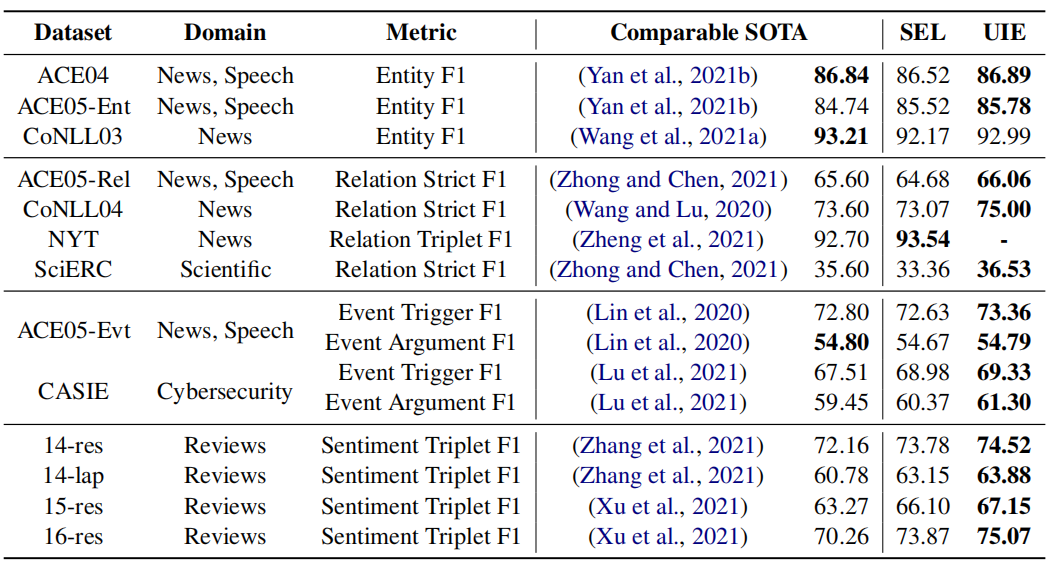
最右边的SEL列是指基于T5-v1.1-large进行微调得到的结果(没有预训练的UIE模型),UIE是指基于UIE-large进行微调的结果,可以看到几乎在全部数据集上都取得了SOTA的结果,但是通过对比SEL和UIE发现预训练部分对结果的提升并不大,通过这个可以看出作者设计的SEL语法和SSI还是很强大的,另一方面也说明T5本身的生成能力就很强大。
另外,下图是few-shot的效果,如下:

UIE真正强大的地方是小样本情况下,泛化能力非常强,远超基于T5的微调结果,在全监督设置下预训练部分的能力没有体现出来,但在低资源下针对性的预训练可以非常好的提升泛化能力。
题目:X-Gear: Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction
论文:
https://arxiv.org/pdf/2203.08308.pdf
创新点:利用
多语言预训练的生成模型
进行
零样本跨语言事件论元提取
,并提出了X-GEAR(
Cross
-lingual
G
enerative
E
vent
A
rgument extracto
R
)。
给定一个输入段落(input passage)和一个精心设计的提示符(prompt),其中包含一个事件触发词和相应的语言无关模板,X-GEAR被训练生成一个句子,用论元填充语言无关模板的句子。
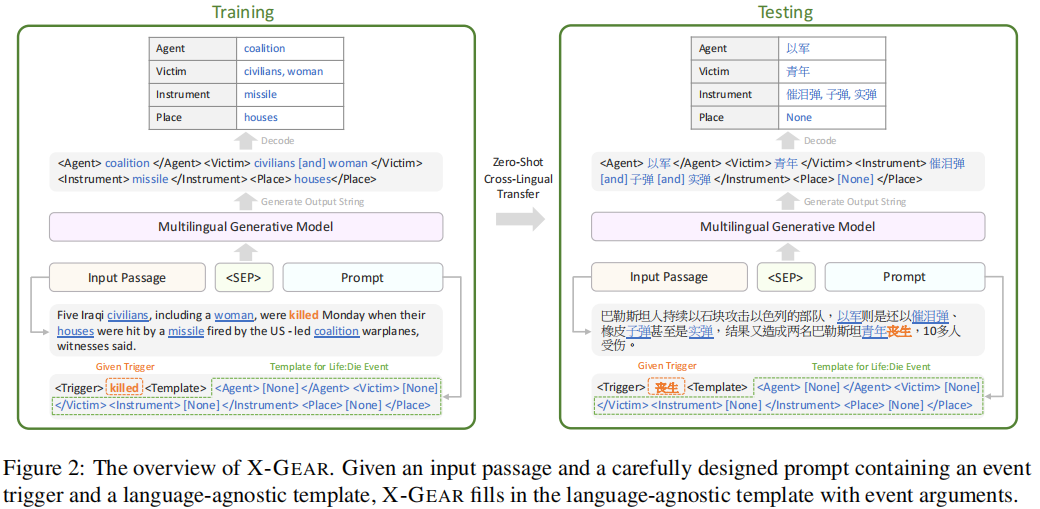
X-GEAR继承了基于生成模型的优势,它比基于分类的模型能更好地捕获事件结构和实体之间的依赖关系。此外,预训练的解码器固有地将命名实体识别为事件论元的候选对象,并且不需要额外的命名实体识别模块。语言无关的模板防止模型与源语言的词汇过拟合,并促进跨语言迁移。
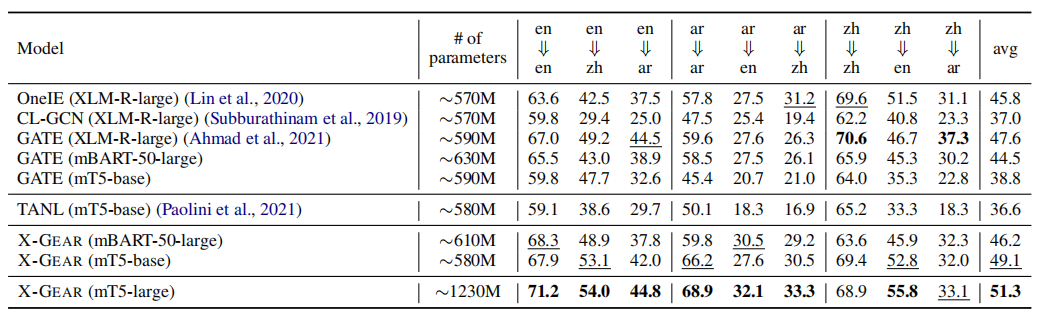
在ACE2005上的F1值
题目:Query and Extract: Refining Event Extractionas Type-oriented Binary Decoding
论文:
https://arxiv.org/pdf/2110.07476v1.pdf
代码:
GitHub – VT-NLP/Event_Query_Extract
创新点
- 将事件提取作为一种查询和提取范式来细化,它比以前的自上而下的分类方法或基于QA的方法更一般化和有效。
- 设计了一个新的事件提取模型,它利用了事件类型和论元角色的丰富语义,提高了准确性和通用性。
(1)用于触发词检测,根据每个事件类型的类型名和原型触发词的短列表将其表示为查询,并基于其查询感知对每个token进行二进制解码嵌入;
(2)用于论元提取,将每个事件类型下定义的所有论元角色放在一起作为查询,然后采用多路注意机制,通过一次性编码提取每个事件提到的所有论元,每个论元预测为二进制解码。
- 将每个事件类型作为对该句子的query来识别每个事件类型的候选触发词。
每个事件类型,都用一个自然语言文本表示,如Attack,包括它的类型名和原型触发词的候选名单,如invaded和airstrikes,是从训练例子中选择的。
- 将输入的句子与事件类型的query连接起来,用一个预先训练好的BERT编码词对它们进行编码
计算每个输入token的事件类型query的顺序表示上的attention分布;
- 将每个token分类为一个二进制标签,表明其是否为特定事件类型的触发词候选。

实验

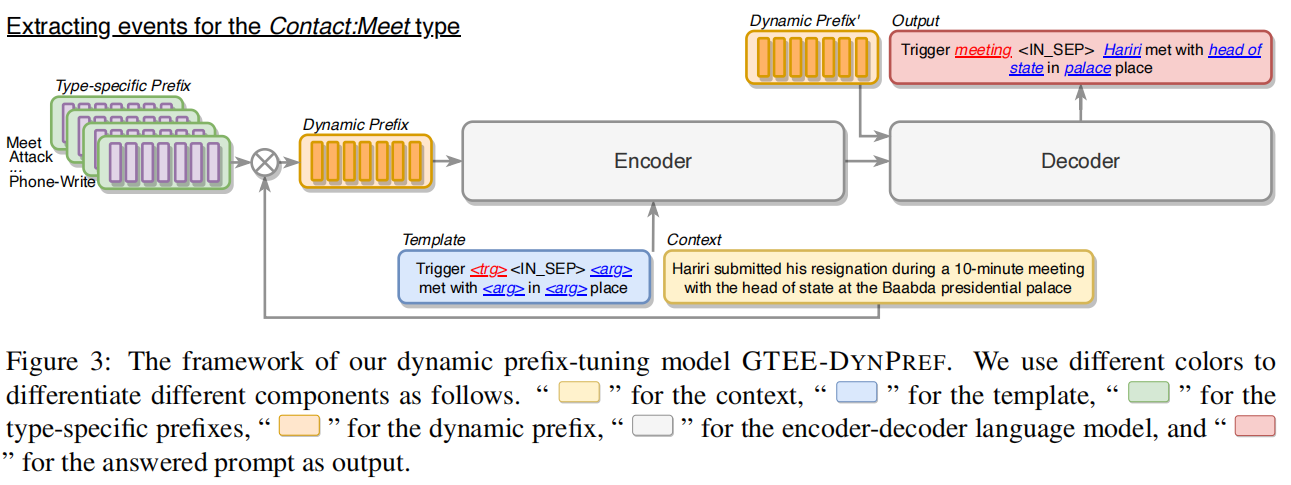
题目:Dynamic Prefix-Tuning for Generative Template-based Event Extraction
论文:
https://arxiv.org/pdf/2205.06166.pdf
代码:未找到
使用预训练的编码-解码器语言模型BART,按一种类型提取事件记录进行条件生成。对于每个事件类型,首先初始化一个特定于类型的前缀,它由一个可调向量序列组成,作为transformer 的历史值。特定于类型的前缀为单一类型提供了可调的事件类型信息。然后,将上下文信息与所有特定于类型的前缀集成起来,以学习特定于上下文的前缀,并动态地组合所有可能的事件类型信息。
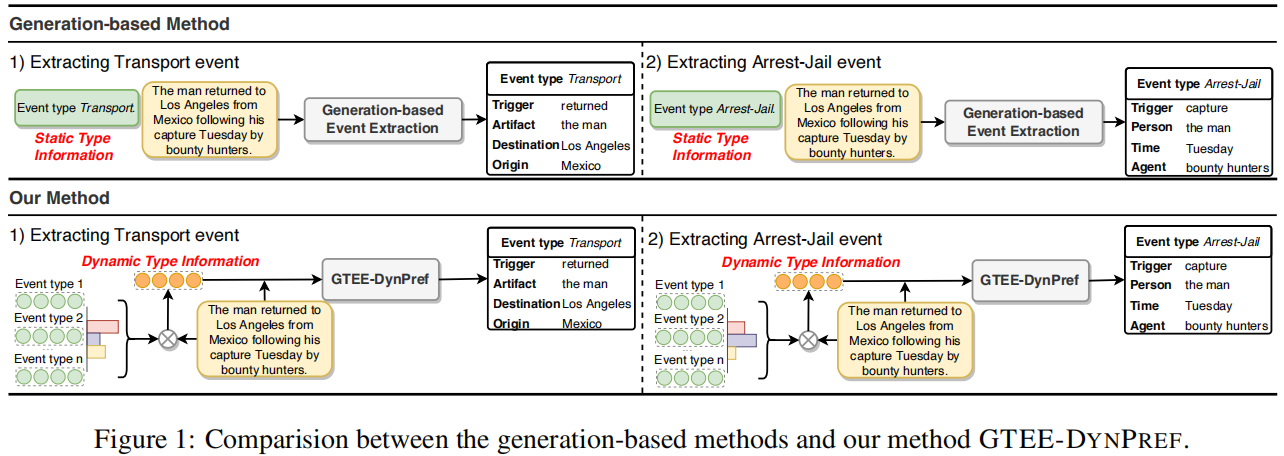
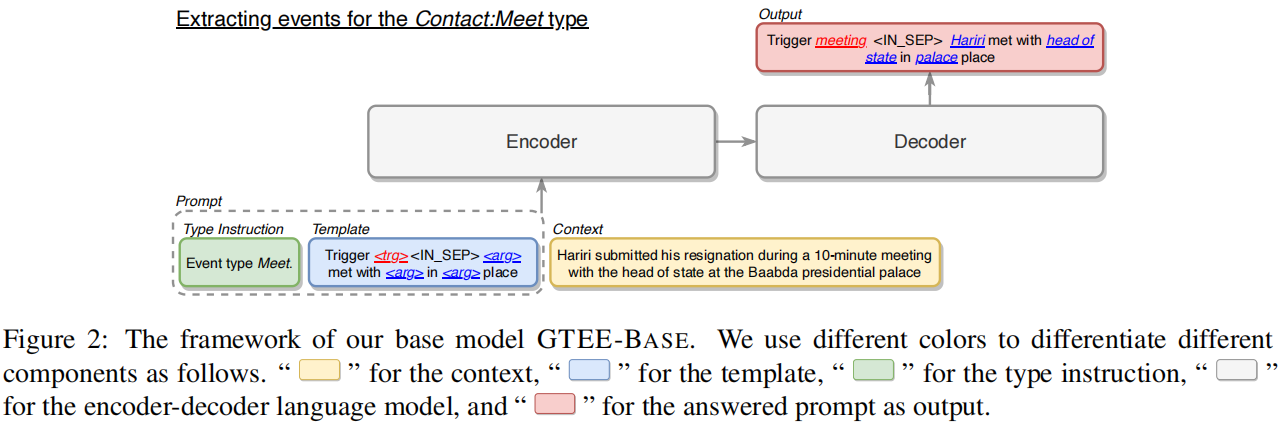
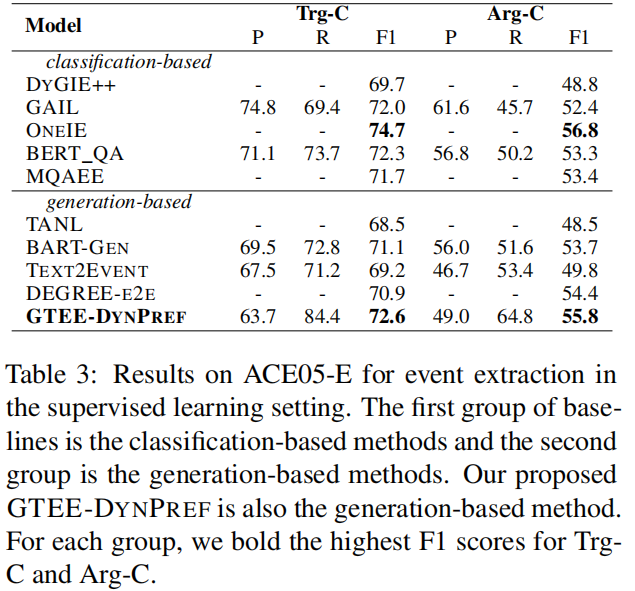
实验结果:
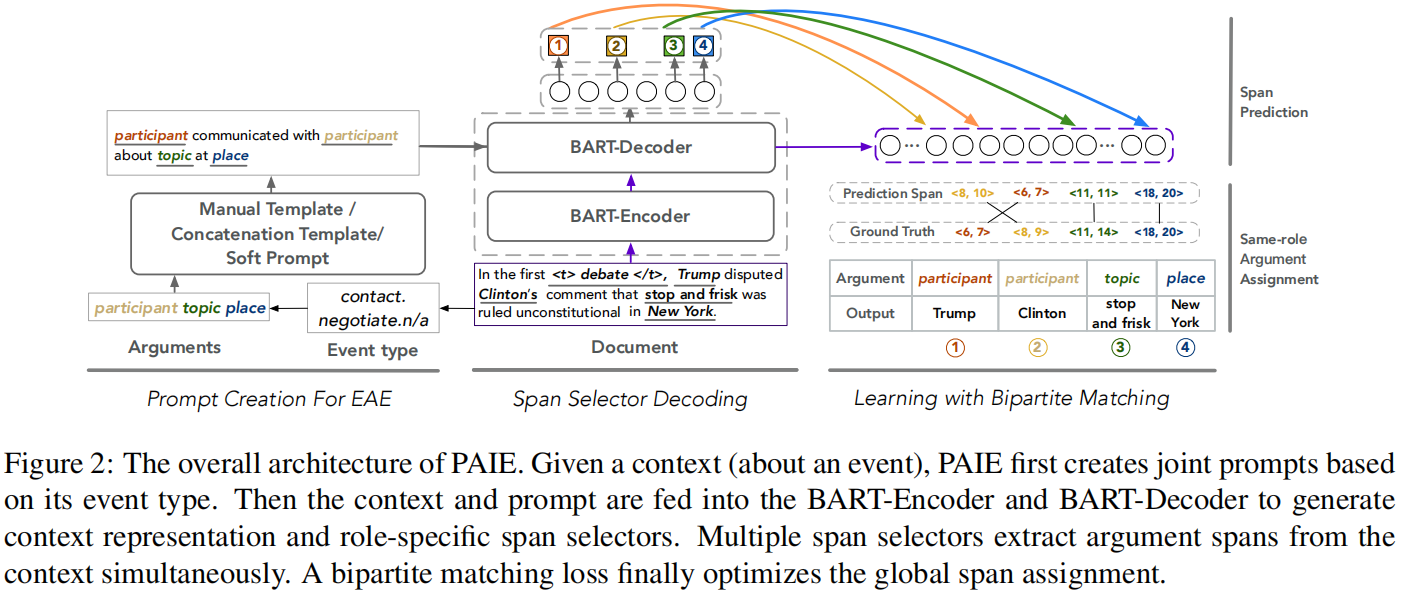
题目:Prompt for Extraction? PAIE: Prompting Argument Interaction for Event Argument Extraction
论文:
https://arxiv.org/pdf/2202.12109.pdf
代码:
https://github.com/mayubo2333/PAIE
创新点:
- 提出了一个有效且高效的句子级和文档级事件论元抽取模型PAIE
- 引入两个span选择器,根据prompt在每个角色的输入文本中选择开始和结束token
- 通过多角色prompt捕获论元交互,并通过二分匹配损失进行最有span分配的联合优化
通过设计一个二分图匹配损失(bipartite matching loss)来prompt论元交互来指导plm和优化多重论元检测,不仅提高了对长距离论元依赖关系的理解,而且通过基于提示的学习享有一个有效的过程。
| 最左边的prompt creation是利用事件类型、事件角色来构建模版,构建好的模版会作为decoder的输入。 |
中间的span selector decoding,主要是 利用Bart的 模型,结构上没有做创新。encoder的输入是文档或句子,decoder输出是event role的特征表示。 |
最右边的span prediction,负责预测论元对应的的起始和结束坐标。 |
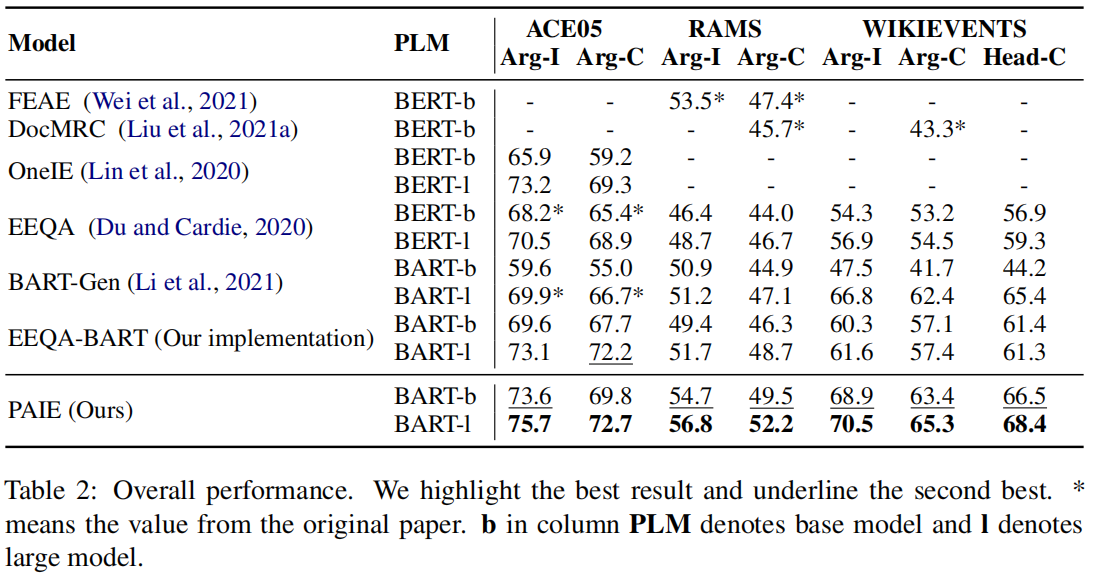
实验结果:
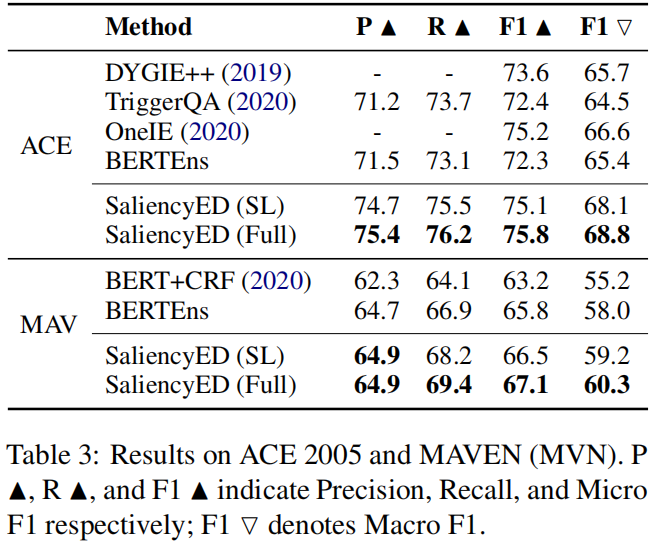
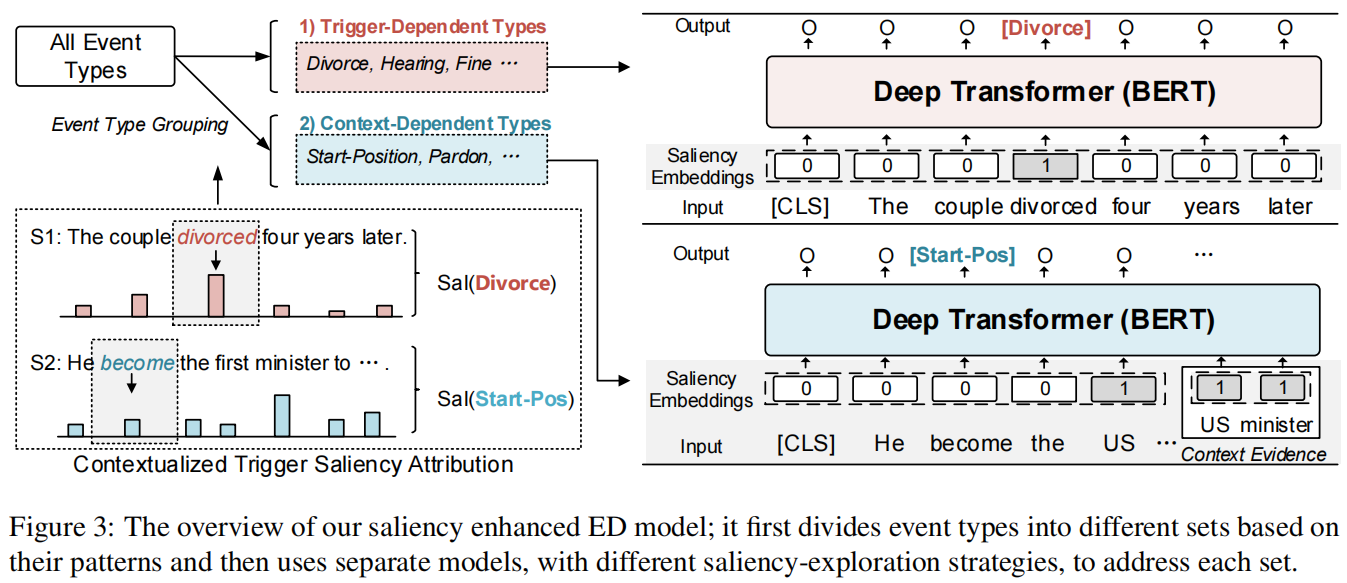
题目:Saliency as Evidence: Event Detection with Trigger Saliency Attribution
论文:
https://aclanthology.org/2022.acl-long.313.pdf
代码:
jianliu-ml/SaliencyED · GitHub
创新点:
- 引入了触发词显著性归因(
trigger saliency attribu
tion)
的brandy新概念,它可以明确地量化一个事件的上下文模式(本文应该是第一个将FA引入ED的工作,用于量化基础事件模式。)
提出了一种新的基于触发显著性归因的ED训练机制
,它在两个基准测试上取得了良好的结果,特别是在处理上下文相关的事件类型时。
触发词显著性归因的方法,该方法包含三个步骤:句子级事件分类(sentence-level event classifification)、单词级显著性估计(word-level saliency estimation)、类型显著性估计(type-level saliency estimation)。

在基于触发显著性归因的基础上,设计了一种新的ED训练范式,可以区分具有相似学习模式的事件类型,并取得了良好的效果。如图3所示。
实验结果: