HBase快速查询
HBase能提供实时计算服务主要原因是由其架构和底层的数据结构决定的,即由LSM-Tree(Log-Structured Merge-Tree) + region分区 + Cache决定——客户端可以直接定位到要查数据所在的HRegion server服务器,然后直接在服务器的一个region上查找要匹配的数据,并且这些数据部分是经过cache缓存的。
HBase会将数据保存到内存中,在内存中的数据是有序的,如果内存空间满了,会刷写到HFile中,而在HFile中保存的内容也是有序的。当数据写入HFile后,内存中的数据会被丢弃。HFile文件为磁盘顺序读取做了优化,按页存储。多次刷写后会产生很多小文件,后台线程会合并小文件组成大文件,这样磁盘查找会限制在少数几个数据存储文件中。HBase的写入速度快是因为它其实并不是真的立即写入文件中,而是先写入内存,随后异步刷入HFile。所以在客户端看来,写入速度很快。另外,写入时候将随机写入转换成顺序写,数据写入速度也很稳定。
而读取速度快是因为它使用了LSM树型结构,而不是B或B+树。磁盘的顺序读取速度很快,但是相比而言,寻找磁道的速度就要慢很多。HBase的存储结构导致它需要磁盘寻道时间在可预测范围内,并且读取与所要查询的rowkey连续的任意数量的记录都不会引发额外的寻道开销。比如有5个存储文件,那么最多需要5次磁盘寻道就可以。而关系型数据库,即使有索引,也无法确定磁盘寻道次数。而且,HBase读取首先会会从内存中的MemStore中查找,如果中没找到,在缓存(BlockCache)中查找,它采用了LRU(最近最少使用算法),只有这两个地方都找不到时,才会加载HFile中的内容,而上文也提到了读取HFile速度也会很快,因为节省了寻道开销。
快速查询(从磁盘读数据)
HBase是根据rowkey查询的,只要能快速的定位rowkey, 就能实现快速的查询,主要是以下因素:
- HBase是可划分成多个region,你可以简单的理解为关系型数据库的多个分区
- 键是排好序了的
- 按列存储的
首先,能快速找到行所在的region(分区),假设表有10亿条记录,占空间1TB,分列成了500个region,1个region占2个G。最多读取2G的记录,就能找到对应记录
其次,是按列存储的,其实是列族,假设分为3个列族,每个列族就是666M, 如果要查询的东西在其中1个列族上,1个列族包含1个或者多个HStoreFile,假设一个HStoreFile是128M, 该列族包含5个HStoreFile在磁盘上。剩下的在内存中
然后,是排好序了的,要的记录有可能在最前面,也有可能在最后面,假设在中间,只需遍历2.5个HStoreFile共300M
最后,每个HStoreFile(HFile的封装),是以键值对(key-value)方式存储,只要遍历一个个数据块中的key的位置,并判断符合条件可以了。 一般key是有限的长度,假设跟value是1:19(忽略HFile上其它块),最终只需要15M就可获取的对应的记录,按照磁盘的访问100M/S,只需0.15秒。 加上块缓存机制(LRU原则),会取得更高的效率。
实时查询
实时查询,可以认为是从内存中查询,一般响应时间在1秒内。HBase的机制是数据先写入到内存中,当数据量达到一定的量(如128M),再写入磁盘中, 在内存中,是不进行数据的更新或合并操作的,只增加数据,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。
实时查询,即反应根据当前时间的数据,可以认为这些数据始终是在内存的,保证了数据的实时响应。
LSM树存储引擎
LSM树的设计思想:把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
数据首先会插入到内存中的树,为了防止数据丢失,写内存的同时需要暂时持久化到磁盘,即输入数据时数据会以完全有序的形式先存储在日志文件中(对应HBase的MemStore和HLog)。当日志文件被修改时,对应的更新会被先保存在内存中来加速查询。
当内存中树的数据达到阀值时,会进行合并操作。合并操作会从左至右遍历内存中的叶子节点与磁盘中树的叶子节点进行合并,当合并的数据量达到磁盘的存储页的大小时,会将合并的数据持久化到磁盘。同时更新父亲节点对叶子节点的指针。
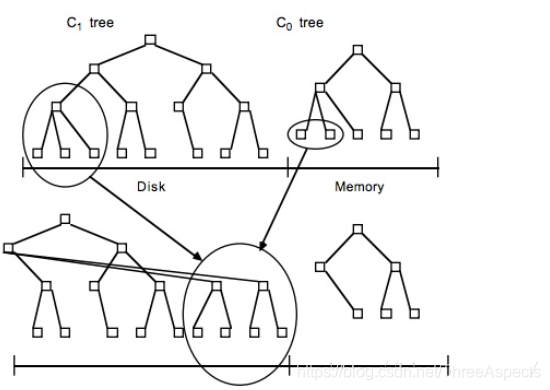
LSM树所有节点都是满的并按页存储,经过多次的flush会创建很多数据存储文件,后台线程会将小文件聚合成大文件,因此磁盘的寻道操作就会被限制在一定数目的数据存储文件中,以优化读性能。磁盘上的树结构也可以分割成多个存储文件,因为所有的存储数据都是按照Key有序排列的,因此在现有节点中插入新的关键字不需要重新排序。
LSM-Tree属于传输型,在磁盘传输速率上进行文件的排序和合并以及日志操作,可以更好的拓展到更大的数据规模上,因为它会使用日志文件和一个内存存储结构把随机写操作转化为顺序写,读写独立,不会产生两种操作的竞争。
LSM树在HBase中的应用
LSM树可以看成n层合并树。在HBase中,它把随机写转换成对MemStore和HFile的连续写。下图展示了LSM树数据写的过程。
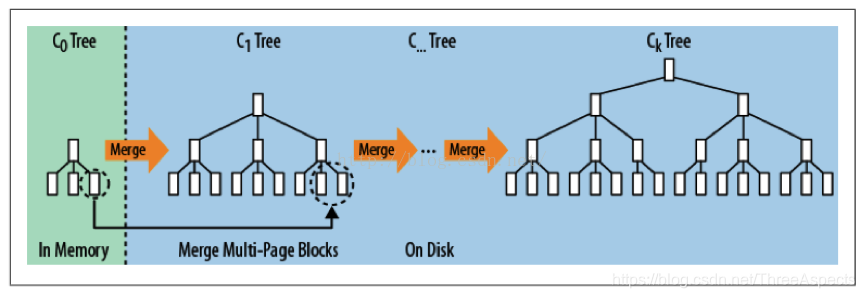
数据写
(插入,更新):数据首先顺序写如HLog(WAL),MemStore上的树达到一定大小之后,需要flush到HRegion磁盘中,这样MemStore就变成了DataNode上的磁盘文件StoreFile,定期HRegionServer对DataNode的数据做merge操作,彻底删除无效空间,多棵小树在这个时机合并成大树,来增强读性能。在StoreFile中,针对顺序磁盘操作进行优化。
数据读
:首先搜索MemStore,如果不在MemStore中,则到StoreFile中寻找。
数据删除
:不会去删除磁盘上的数据,而是为数据添加一个删除标记。在随后的major compaction中,被删除的数据和删除标记才会真的被删除。
LSM数据更新只在内存中操作,没有磁盘访问,因此比B+树要快。对于数据读来说,如果读取的是最近访问过的数据,LSM树能减少磁盘访问,提高性能。
针对LSM树读性能hbase的优化:
Bloom-filter:可以快速判断某一个小的有序结构里有没有指定数据的。于是就可以不用二分查找,而只需简单的计算几次就能知道数据是否在某个小集合里,效率得到了提升,但付出的是空间代价。
compact:小树合并为大树。因为小树性能有问题,所以要有个进程不断地将小树合并到大树上,这样大部分的老数据查询也可以直接使用log2N的方式找到,不需要再进行(N/m)*log2n的查询了。