目录
1.由来
trino的前身是Presto,后面创始人和facebook闹翻,被迫改名叫了trino。
2.基本概念
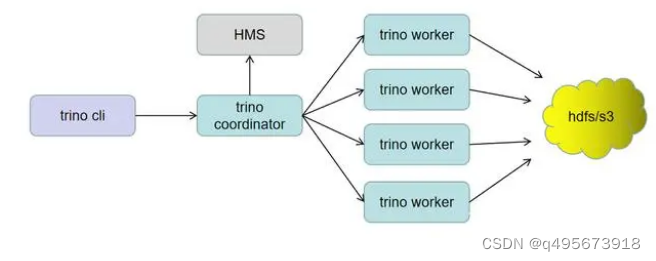
trino是一个计算引擎,没有自己的存储。他可以运行在sql-on-anthing。其存储与计算分离的核心就是通过连接器实现的。trino提供了Hive,Mysql等连接器,也可以自定义实现连接器。
trino的服务器有2种角色,coordinators和workers。
| coordinators | 相当于master,负责解析语句,分配任务和管理workers |
| workers | 负责任务的真正执行 |
3.应用场景
trino适合多数据源的即席查询,它是把数据通过connector拉取回来,然后使用自己的引擎进行关联运算,所以其速度必然受限于传输速度,不适合跨网络的大数据量的关联查询。像spark之类的查询引擎我们都是把尽量分发到数据存储的机器上,trino是把数据拿回来,这就是他们的差异所在。
另外在执行mysql的时候会使用到mysql引擎的计算能力
例如执行 select * from table order by xx limit 100000,10的时候就会先在mysql根据这个语句先把数据处理好然后在传到trino
如果是执行 select xx from table group by xx那在mysql执行的就是select xx from table 而不会去聚合运算。
如果是在hive执行的话,猜测没有使用hive的计算能力,而是把文件直接丢给了trino
4.安装
1.下 载
wget https://repo1.maven.org/maven2/io/trino/trino-server/400/trino-server-400.tar.gz
2.解压
将压缩包解压至trino-server-400,我们称之为安装目录
tar -xzvf trino-server-400.tar.gz
3.配置
在安装目录中中创建etc目录,在目录中创建以下配置文件
- node.properties:特定于每个节点的环境配置。
- jvm.config:Java 虚拟机的命令行选项。
- config.properties: Trino 服务器的配置。
- log.properties:日志属性。
- 目录属性:数据源的配置。
1.节点属性
node.properties是节点属性文件,基本配置如下
node.environment=production
node.id=node1
node.data-dir=**/trino-server-400/data- node.environment:环境名称。集群中所有的trino节点环境名称必须相同
- node.id:trino的唯一标识符,每个节点的node.id必须是唯一的
- node.data-dir:数据目录的位置。存储日志和其他数据
2.JVM配置
JVM 配置文件etc/jvm.config包含用于启动 Java 虚拟机的命令行选项列表。基本配置如下
-server
-Xmx16G
-XX:InitialRAMPercentage=80
-XX:MaxRAMPercentage=80
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-XX:+UnlockDiagnosticVMOptions
-XX:+UseAESCTRIntrinsics
3.配置属性
配置属性文件etc/config.properties包含 Trino 服务器的配置。每台 Trino 服务器都可以充当协调器和工作器,但是专用一台机器只执行协调工作可以在更大的集群上提供最佳性能。
coordinator的基本配置如下。如果是单机的node-scheduler.include-coordinator设为true
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
//下面的8080就是上面http-server.http.port的值
discovery.uri=http://example.net:8080worker的基本配置如下
coordinator=false
http-server.http.port=8080
discovery.uri=http://example.net:8080
4.日志级别
日志级别文件etc/log.properties,基本信息如下
io.trino=INFO
5.Catalog属性
Trino访问数据通过connector,它配置在catalog目录内,我们创建etc/catalog目录
hive源配置如下,我们在catalog目录下创建文件hive.properties,core-site.xml,hdfs-site.xml可以从hadoop集群复制一份然后放到配置文件中。catalog就是hive.properties中的hive文件名
connector.name=hive
hive.metastore.uri=thrift://ip:9083
hive.config.resources=**/etc/core-site.xml,**/etc/hdfs-site.xmlmysql源配置如下,我们在catalog目录下创建mysql.properties
connector.name=mysql
connection-url=jdbc:mysql://example.net:3306?useUnicode=true&useSSL=false&characterEncoding=UTF-8&serverTimezone=UTC
connection-user=root
connection-password=secret
6.配置jdk
因为trino-400官网建议使用jdk17,所以我们现在之后上传到trino目录,然后解压。作为临时使用,我们以前的机器是使用的jdk8,我们不做升级。修改启动脚本使其使用jdk17
PATH=**/trino/jdk-17.0.4.1/bin/:$PATH
java -version
exec "$(dirname "$0")/launcher.py" "$@"
4.服务端启动
./trino-server-400/bin/launcher start
5.客户端
1.下载
下载之后将trino-cli-400-executable.jar改成trino-cli,并给trino-cli添加可执行权限
wget https://repo1.maven.org/maven2/io/trino/trino-cli/400/trino-cli-400-executable.jarwget https://repo1.maven.org/maven2/io/trino/trino-cli/400/trino-cli-400-executable.jar
2.客户端启动
./trino-cli --server localhost:8080
6.使用
1.web访问地址
http://localhost:8080
2.查询
//如果查询失败显示没有查询权限 那trino目录权限就需要改成有hive查询权限的账号 然后重启
select * from catalog.schema.table
3.常用命令
显示所有的catalog
show catalogs;
查看所有的schemas
show schemas from mysql
退出客户端
quit;