【提示】
点击每一关
参考答案
可以快速复制。
目录
第1关:函数的查询、描述和调用
任务描述
本关任务:查一下
add
函数的用法,并尝试使用它。
相关知识
本关我们将学习
Hive
中函数的基本用法。
函数的查询
Hive
中的函数比较多,我们不需要记住所有函数的意义和用法。当需要使用某个函数的时候,可以直接在
Hive
交互界面查询。
首先,在命令行输入
hive
进入交互模式,如下: (以下所有图片中的红色箭头均表示用户的输入)

成功进入后如下:
查看Hive的所有函数
查看所有函数的命令是:
show functions结果如下:
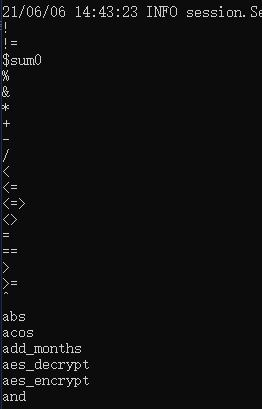
当然,结果非常多,上图只展示了极少的部分。
查看某个函数的含义和用法
以上图中的
abs
函数为例子: 查看函数含义:
desc function abs结果如下:

上面的英文的意思是:
abs
函数的含义是返回
x
的绝对值。
我们还可以看下这个函数使用的例子:
desc extended function abs

到这里,这个函数是干什么的、以及怎么用,就一目了然了。
函数的调用
上面给出了函数具体使用的例子,但是我们毕竟没有亲自用过,俗话说“实践出真知”,那就试用下
abs
函数。
一些不得不做的准备工作
首先,例子里给的
src
其实是一个表,所以我们需要先建一个表,名字就叫
test_table
吧,没必要和例子一模一样:
create table test_table(id int,name string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
然后,往表里插入一些数据,要不然
select
查不出任何东西。
hive
没有
insert
关键字,插入数据需要从磁盘中导入。在当前命令行所在的目录下新建一个
a.txt
文件,内容如下:

一行内的分隔符是
\t
,这个分隔符我们在建表的时候实际上已经指定了。
然后执行下面的语句就导入了:
load data local inpath 'a.txt' into table test_table;通过
select * from test_table看下有没有导入成功:

我这里是成功了,如果没有成功,你得重新尝试。
开始实践
一番折腾后,现在,可以来试试
abs
函数了:
select abs(0) from test_table limit 1;看下输出:

没错,结果是
0
。
再来看下负数的
abs
,如下:
select abs(-2) from test_table limit 1;输出:

这一关是教大家如何去了解并实践一个函数,就不再给例子了,需要大家多多尝试。
编程要求
根据提示,在右侧编辑器
Begin
和
End
之间补充代码,使用
Hive
中的
ceil
函数求数字
66666
的
ceil
的结果,我们已经准备了表
test_table
,而且表中已经有若干的数据。
测试说明
平台会执行你补充的
sql
文件,然后将输出和正确的结果进行对比,从而判断你的程序是否正确。
无输入,正确的输出如下:
66666
参考答案
#代码文件
drop table if exists test_table;
create table test_table(id int,name string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
load data local inpath 'step1/data.txt' into table test_table;
--------- Begin ---------
select ceil(66666) from test_table limit 1;
--------- End ---------
第2关:Hive标准函数
任务描述
本关任务:按要求查询数据。
相关知识
本关将学习
Hive
中的一些最基本的函数。
先准备一些数据
我们需要先准备一些数据,使用的表还是第一关中介绍的
test_table
表,向其中导入如下的数据,导入方法见第一关。
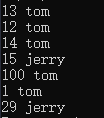
第一列对应
test_table
表的
id
,第二列对应
name
。
关系函数
关系函数作用在
where
条件子句中,用来筛选符合要求的列。
相等关系
判断两个值是否相等使用
=
即可,如下,查找
id
等于
15
的数据:
select * from test_table where id=15;结果如下: (以下所有截图中的红色箭头均为后期添加,表示运行的结果)。

查找名字为
tom
的数据:
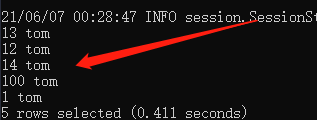
select * from test_table where name='tom';字符串类型必须放在单引号中。
结果如下:
不等关系
不等于使用
<>
来表示,比如查找所有
id
不等于
100
的数据:
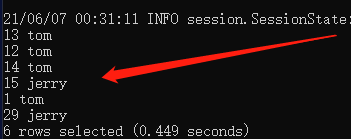
select * from test_table where id<>100;结果如下:
其它的诸如大于、小于、大于等于,符号和数学基本相同,用法和上面相同。
like比较
对于字符串来说,很多时候还需要用到正则表达式的比较,在
hive
中通过
like
关键字来实现:
select * from test_table where name like 't%';
表示查找名字以
t
开头的记录,其结果如下:
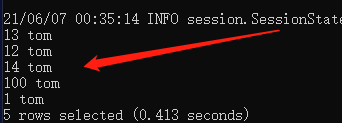
%
表示匹配任意数量的字符串,而
_
表示匹配单个字符串。
算数运算
Hive
中还可以执行算数运算,如下是加法:
select 1+2 from test_table limit 1;结果如下:
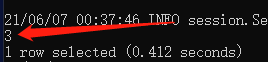
还可以是位运算,比如按位与:
select 4&8 from test_table limit 1;结果如下:
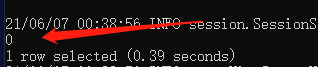
编程要求
在右侧的编辑器的
Begin
和
End
之间补充代码,查询表
test_table
中所有的
name
不等于
jerry
的记录。表中的数据和上面开始准备的数据完全相同。
测试说明
平台会执行你补充的
sql
文件,然后查看运算结果是否符合正确的结果。
没有输入,正确的输出如下:
13 tom
12 tom
14 tom
100 tom
1 tom
参考答案
#代码文件
drop table if exists test_table;
create table test_table(id int,name string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
load data local inpath 'step2/data.txt' into table test_table;
---- 求名字不等于jerry的所有记录 ----
--------- Begin ---------
select * from test_table where name<>'jerry';
--------- End ---------
第3关:Hive聚合函数
任务描述
本关任务:求
id
大于
12
的所有行的
id
的和。
相关知识
本关将学习
Hive
中的聚合函数。什么是聚合函数,简单来说,就是求一组数据的最大值、最小值、数量、平均值等反映数据集体特征的函数。
下面我们一个一个来学习。
先准备一些数据
我们需要先准备一些数据,使用的表还是第一关中介绍的
test_table
表,向其中导入如下的数据,导入方法见第一关。

第一列对应
test_table
表的
id
,第二列对应
name
。
计数函数
count
常规用法
count
用来统计
select
语句查出来的记录的数量,比如,统计
test_table
表当前的数据的数量:
select count(1) from test_table;
这里的语法很简单,
select
表示查询数据,
from
后面跟着你要查询的表的名字。如果只想查询指定的行,还可以使用
where
来控制查询条件。
运行结果如下: (本关的所有图片中,红色箭头均指向输出,下不赘述)

可以看到,结果正确。
这里的
count
和
mysql
中的
count
原理完全不同,它使用的是
Hadoop
中的
MapReduce
计算模型。这就是为什么安装
Hive
之前必须得安装
Hadoop
。
需要特别提醒的是,如果你是在
Windows
系统下使用的
hive
,需要用管理员身份打开
hadoop
下的
sbin
目录下的
start-all.cmd
。否则会报错。
求指定的列
上面说了,我们可以使用
where
来控制查询指定的列,比如我们只想知道
id
大于
10
的列的数量,则命令如下:
select count(1) from test_table where id>10;结果如下:

本关的剩余部分介绍的所有函数,都可以使用
where
子句来查询指定的行,篇幅限制,我们不再给每一个函数提供
where
的例子。
求最大值和求最小值
求年龄字段的最大值的命令如下:
select max(id) from test_table;求年龄字段的最小值的命令如下:
select min(id) from test_table;
这里的语法也很简单,
max
和
min
分别是求最大和求最小的关键字,括号里面是要求的列。
运行结果如下: 求最大:

求最小:
求均值
求均值的命令如下:
select avg(id) from test_table;
avg
是求均值关键字,括号里是需要被计算均值的列的名字。
结果如下:

我们可以手工演算一下,结果正确。
求和
我们还可以求所有的行中,同一列的和,命令如下:
select sum(id) from test_table;它的运行结果如下:

分组聚合函数
group by
有的时候,我们需要对数据分组,再查它的聚合特征,比如下面的数据:

我们要查
name
分别为
tom
和
jerry
的所有
id
的和,显然,可以使用
where
先查
tom
,再去查
jerry
,但是有更简单的办法:
select sum(id),name from test_table group by name;
group by name
的意思是先使用
name
字段将所有的数据分为两组:
name
为
tom
的为一组,
name
为
jerry
的为一组,然后对这两组,分别执行求和操作。
结果如下:
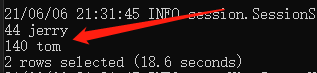
可以看到,我们一次性求出了
tom
和
jerry
旗下的
id
的和。
编程要求
在右侧的编辑器的
Begin
和
End
之间补充代码,求表
test_table
中所有的
id
大于
12
的记录的
id
的和。表中的数据如下:
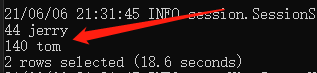
测试说明
平台会执行你补充的
sql
文件,然后将输出和正确的结果进行对比,从而判断你的程序是否正确。
无输入,正确的输出如下:
171
参考答案
#代码文件
drop table if exists test_table;
create table test_table(id int,name string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
load data local inpath 'step3/data.txt' into table test_table;
---- 求id大于12的记录的id值的和 ----
--------- Begin ---------
select sum(id) from test_table where id > 12;
--------- End ---------
第4关:Hive日期函数
任务描述
本关任务:将指定的时间戳转换为普通的时间。
相关知识
本关我们将学习
Hive
中日期函数的基本用法。所谓日期函数,即用来进行日期计算的函数。
使用的表还是上面几关中出现了很多次的
test_table
。
将时间戳转换为普通时间
时间戳:从
1970
年
1
月
1
日
0
点
0
分
0
秒距指定时间的秒数。比如
1463308943
指的实际上是
2016
年
5
月
15
号
18
点
42
分
23
秒。就是说这两个时间之间相距
1463308943
秒钟。
转换命令如下:
select from_unixtime(1463308943,'yyyyMMdd HH:mm:ss') from test_table limit 1;
其中
yyyy
表示结果中的年份将以
2016
这种四位数的形式展现,
MM
表示月份以
05
这种两位数的形式展现,
dd
表示两位数的天,
HH
表示
24
小时制,
mm
和
ss
分别表示分钟和秒钟以两位数的形式展示。
运行结果如下:

普通时间转时间戳
接着上面的讨论,怎么反过来将普通时间转为时间戳:
select unix_timestamp('20210606 13:01:03','yyyyMMdd HH:mm:ss') from test_table;同样,这里需要说明普通时间的格式。
最终的转换结果如下:

求当前时间
获取当前的时间戳的命令如下:
select unix_timestamp() from test_table;它的输出如下:

计算相差天数
我们还可以使用
Hive
计算两个时间相差的天数:
select datediff('2019-12-08','2012-05-09') from test_table;结果是:

对时间进行加或者减
对指定的日期减去一天:
select date_sub('2021-06-06',1) from test_table;结果如下:
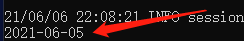
指定日期加上
100
天:
select date_add('2021-06-06',100) from test_table;结果如下:
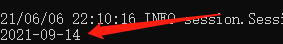
编程要求
根据提示,在右侧编辑器
Begin
和
End
之间补充代码,将时间戳
1463308946
转换为类似
2012-02-02 02:02:02
格式的普通时间。
我们已经在系统中创建了表
test_table
以供执行
sql
。
测试说明
平台会执行你补充的
sql
文件,然后将输出和正确的结果进行对比,从而判断你的程序是否正确。
无输入,正确的输出如下:
2016-05-15 10:42:26
参考答案
#代码文件
drop table if exists test_table;
create table test_table(id int,name string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
load data local inpath 'step4/data.txt' into table test_table;
---- 将1463308946转换为格式类似 2012-02-02 02:02:02 的普通时间 ----
--------- Begin ---------
select from_unixtime(1463308946,'yyyy-MM-dd HH:mm:ss') from test_table limit 1;
--------- End ---------
第5关:表生成函数
任务描述
本关任务:修改指定表的字段的名字。
相关知识
本关,我们将学习在
Hive
中如何创建表、更新表和删除表。
创建表
表是
Hive
中的基本单位,一个表用来表示现实世界中的一类事物,比如学生表、教师表、课程表等。
表由若干个字段组成,每一个字段有自己的名字和类型。
比如学生表有名字为
name
的字段,表示学生的名字,它的类型是
string
,即字符串。我们的
hive
是在
mysql
数据库的基础上使用的,它可以用的字段类型如下所示:
| mysql | hive | 含义 |
|---|---|---|
| varchar | string | 字符串 |
| int | int | 4Byte有符号整数 |
| bigint | bigint | 8Byte有符号整数 |
| tinyint | tinyint | 1Byte有符号整数 |
| float | float | 单精度浮点数 |
| timestamp | timestamp | 时间 |
建立一个学生表:学生名字,字符串;学生年龄,整数;出生日期:时间戳。
则命令如下:
create table student(name string, age int, birth timestamp);
语法也很简单,
create
关键字后面跟着表的名字,括号里面是字段,字段第一部分是名字,后面是类型,空格隔开。
运行之后,可以通过:
desc student;看下我们的表有没有建好,如下:
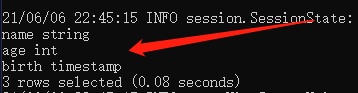
这样的输出就表示表建好了。
删除表
全部删除
可以通过
drop
关键字来删除表,这样表里的数据和表本身都会被删除:
drop table if exists student;
怎么验证删除是否成功,老办法,还是用
desc student;
命令,结果如下:

报错了,找不到表
student
,所以删除成功了。
只删除数据
还可以通过关键字
truncate
删除表中的全部数据,但是保留表本身:
truncate table if exists student;这里我们不给演示的例子了,大家可以自己试试,记得尝试之间要先往表里导入一些数据。
调整表的结构
建立好的表,还可以修改其中的字段或者表的名字。
改名字
将
student
表名字改为
stud
:
alter table student rename to stud;看下现存的所有的表:
show tables;如下:

所以,名字改成功了!
改字段
将
stud
中的
birth
的名字改为
birthday
:
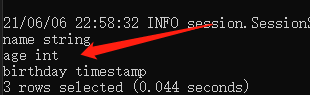
alter table stud change column birth birthday timestamp;
其中
column
后面跟着的依次是原来的字段的名字、新的字段名、新的字段类型。
看下结果:
编程要求
在右侧的编辑器的
Begin
和
End
之间补充代码,将表
test_table
的字段
id
的名字改为
age
,类型不变。
测试说明
平台会执行你补充的
sql
文件,然后将输出和正确的结果进行对比,从而判断你的程序是否正确。
无输入,正确的输出如下:
age int
name string
参考答案
#代码文件
drop table if exists test_table;
create table test_table(id int,name string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
---- 把列id的名字改为age,类型不变----
--------- Begin ---------
alter table test_table change column id age int;
--------- End ---------
desc test_table;
第6关:分组排序取TopN
任务描述
本关任务:编写一个分组排序的
Hive
。
相关知识
本关将学习在
Hive
中如何对数据进行分组和排序。
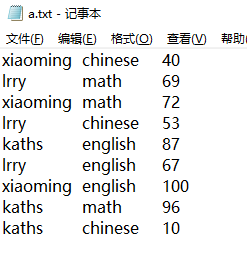
我们使用的表的结构如下所示:

这三列分别表示名字、学科和成绩。
我们插入的数据如下所示:
每一行从左到右分别是名字、学科和成绩。
使用
row_number
的分组排序
不同于传统的
mysql
语法,在
hive
中可以使用
row_number
关键字同时完成分组和排序,它的语法如下所示:
row_number() over (partition by column_a order by column_b)
含义是先根据列
column_a
进行分组,然后根据列
column_b
进行排序。我们先来看下排序。
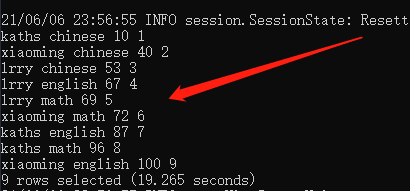
先排序
对于上面的数据,我们先按照成绩排序:
select *, row_number() over (order by score) as rn from student_grades;结果如下:
再分组
然后我们再按照学科分组,按照成绩排序:
select *, row_number() over (partition by course order by score) as rn from student_grades;看下结果:
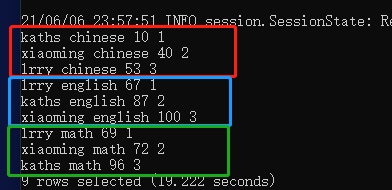
结果正确,我们用不同颜色的框把不同的学科标示出来了。
特别注意下,每个分组后面还有一个序号,这个后面会用到。
取
TopN
那么,如何取
TopN
呢,比如我们只想知道每一个学科的前两名和成绩,则命令如下:
select * from
(
select
*, row_number() over (partition by course order by score desc) as rn
from student_grades
)
temp_table
where temp_table.rn <=2;
这个
sql
看起来复杂,其实也好理解。
首先,括号里面先执行,结果就是我们上面看到的,总共有四列,第四列的名字就是
rn
;
然后我们把这个运算结果看作一个新的表
temp_table
,使用
select
从这个新的表里进行选择,并且指定列
rn
的值小于等于
2
,这个实际上就取出了前两名。
看下结果:
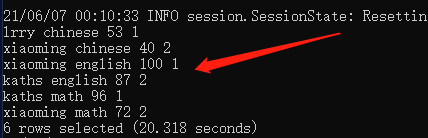
编程要求
根据提示,在右侧编辑器
Begin
和
End
之间补充代码,实现对本例中开头部分给出的数据,按照
name
分组,然后
select
出前两名的全部信息以及序号(
row_number()
生成的数字)。
测试说明
平台会执行这一条命令,将获得的输出和正确的输出进行对比,从而判断你的程序是否正确。
测试输入:(无); 预期输出:
kaths math 96 1
kaths english 87 2
lrry math 69 1
lrry english 67 2
xiaoming english 100 1
xiaoming math 72 2输出首先按照名字分组,然后取出这个名字下的成绩的前两名。
参考答案
#代码文件
drop table if exists student_grades;
create table student_grades(name string, course string, score int) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
load data local inpath 'step6/data.txt' into table student_grades;
---- 按name分组,取出前两名的信息----
--------- Begin ---------
select * from
(
select
*, row_number() over (partition by name order by score desc) as rn
from student_grades
)
temp_table
where temp_table.rn <=2;
--------- End ---------
至此,所有内容都完成辣。如果存在任何问题欢迎大佬指教?!