文章目录
一、前言
本系列为个人Dubbo学习笔记,内容基于《深度剖析Apache Dubbo 核心技术内幕》, 过程参考
官方源码分析文章
,仅用于个人笔记记录。本文分析基于Dubbo2.7.0版本,由于个人理解的局限性,若文中不免出现错误,感谢指正。
系列文章地址:
Dubbo源码分析:全集整理
通过之前的阅读,我们发现,无论是消费者还是生产者,在建立Netty 连接时都会注册 编码器和解码器Handler,用于编码和解码数据。简单来说,数据在网络上传播是按照某种格式传播,而这里的编码和解码就是在发送数据前将数据转化为规定的格式再发送,在接收数据时将数据从规定格式转换为我们可接收的格式。
本文没什么发挥空间,所以内容大部分都直接照搬书上内容。
二、 Dubbo 协议
在TCP协议栈中,每层协议都有自己的协议报文格式,比如TCP是网络七层模型中的传输层,是TCP协议报文格式;在TCP上层是应用层(应用层协议常见的有HTTP协议等),
Dubbo协议作为建立在TCP之上的一种应用层协议
,自然也有自己的协议报文格式。Dubbo协议也是参考了TCP协议栈中的协议,协议内容由header和body两部分组成,如下图:
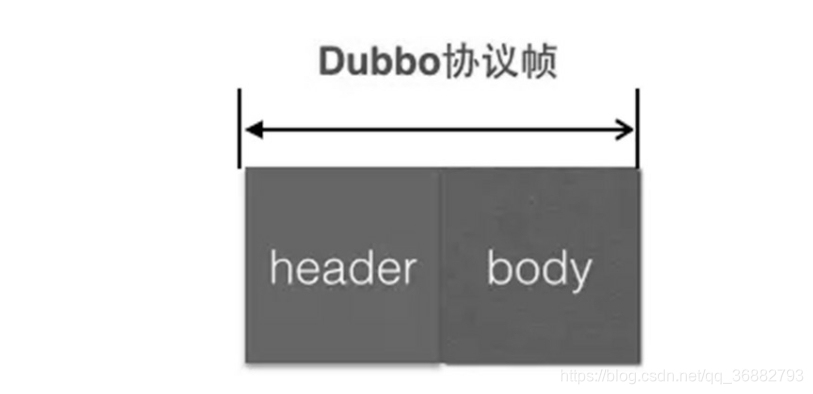
其中,协议头header格式如下图所示:

由上图可知,header总包含了16字节的数据。其中:
-
第一个和第二个字节为魔数,类似Class类文件里的魔数,这里用来标识一个帧的开始,固定为0xdabb,第一字节固定为0xda,第二字节固定为0xbb。
-
第三个字节是请求类型和序列化标记ID的组合结果:
requst flag|serializationId
。其中,高四位标示请求类型,其枚举值如下:org.apache.dubbo.remoting.exchange.codec.ExchangeCodec
// message flag. protected static final byte FLAG_REQUEST = (byte) 0x80; protected static final byte FLAG_TWOWAY = (byte) 0x40; protected static final byte FLAG_EVENT = (byte) 0x20;低四位标示序列化方式,其枚举值如下:
DubboSerialization:0001 FastJsonSerialization:0110 Hessian2Serialization:0010 JavaSerialization:0011 -
第四个字节是只在响应报文里才设置(在请求报文里不设置),用来标示响应的结果码,具体定义如下:
org.apache.dubbo.remoting.exchange.Response/** * ok. */ public static final byte OK = 20; /** * client side timeout. */ public static final byte CLIENT_TIMEOUT = 30; /** * server side timeout. */ public static final byte SERVER_TIMEOUT = 31; /** * channel inactive, directly return the unfinished requests. */ public static final byte CHANNEL_INACTIVE = 35; /** * request format error. */ public static final byte BAD_REQUEST = 40; /** * response format error. */ public static final byte BAD_RESPONSE = 50; /** * service not found. */ public static final byte SERVICE_NOT_FOUND = 60; /** * service error. */ public static final byte SERVICE_ERROR = 70; /** * internal server error. */ public static final byte SERVER_ERROR = 80; /** * internal server error. */ public static final byte CLIENT_ERROR = 90; /** * server side threadpool exhausted and quick return. */ public static final byte SERVER_THREADPOOL_EXHAUSTED_ERROR = 100; -
第五到第十二个字节是请求ID。
-
第十三到十六个字节是body内容的大小,也就是指定在协议头header内容后的多少字节是协议body的内容。
三、 编解码器的注入
1. 消费者的注入时机
在消费端启动时,NettyCodecAdapter管理的编解码器被设置到Netty链接的Channel管线里。
《深度剖析Apache Dubbo 核心技术内幕》 中关于 Netty流程描述如下
:
消费端发起一次调用后,最终会通过 DubboInvoker#doInvoke 方法内的远程调用客户端对象currentClient的request方法把请求发送出去。当网络传输使用Netty时,实际上是把请求转换为任务并投递到了NettyClient对应的Channel管理的异步队列里,这样当前的业务线程就会返回了,Netty会使用I/O线程去异步地执行该任务,把请求通过TCP链接发送出去
。
Netty异步处理的写入时序图如图
:
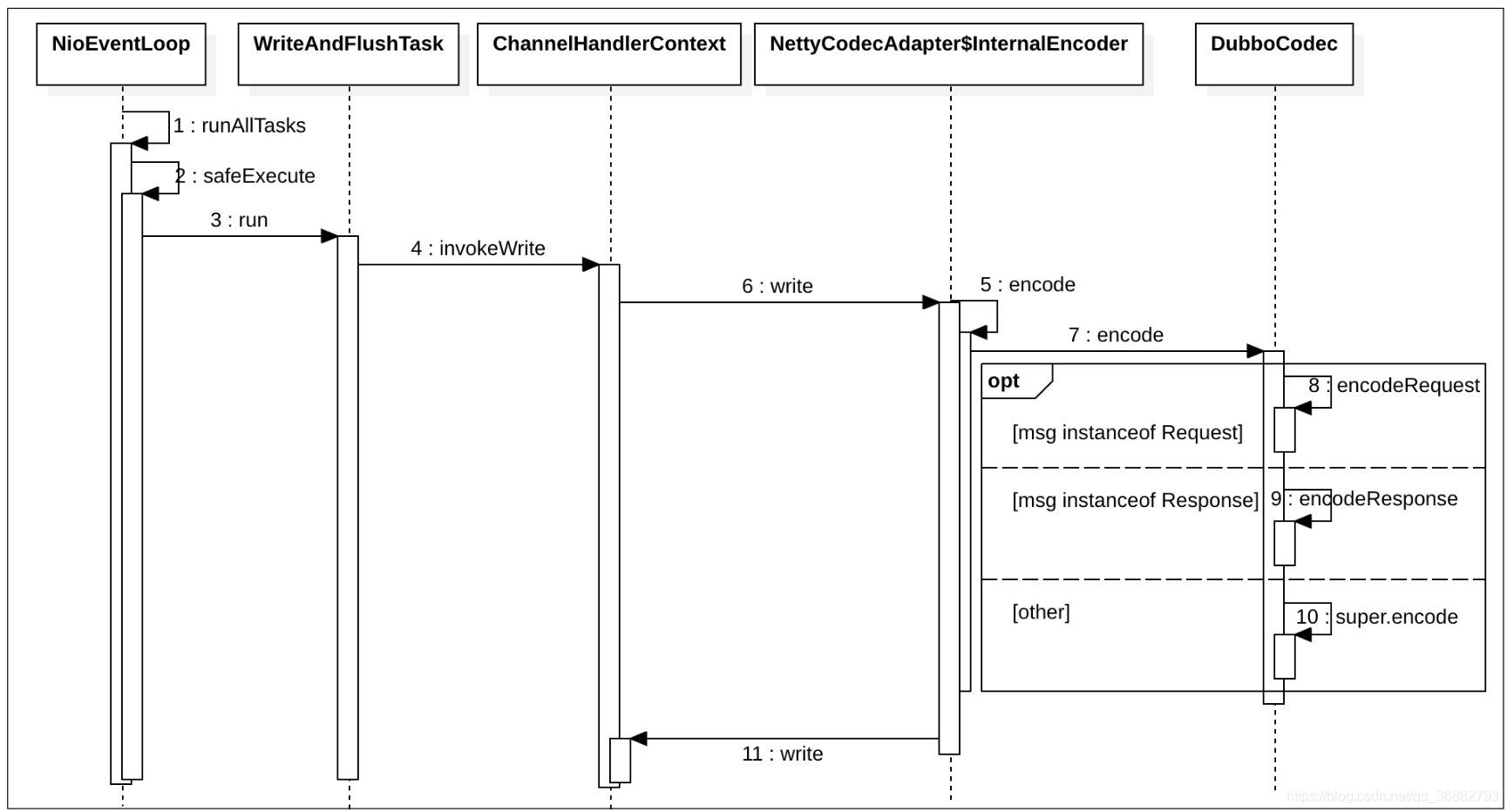
在Netty中,每个Channel(NioSocketChannel)与NioEventLoopGroup中的某一个NioEventLoop固定关联,业务线程就是异步地把请求转换为任务,并写入与当前Channel关联的NioEventLoop内部管理的异步队列中,然后NioEventLoop关联的线程就会去异步执行任务,上图就是使用NioEventLoop关联的线程异步地把请求发送出去
。
上图中 NioEventLoop关联的线程会把请求任务进行传递,即传递给该Channel管理的管线中的每个Handler,其中的一个Handler就是编解码处理器,也就是图中的InternalEncoder,它又把任务委托给DubboCodec对请求任务进行编码,编码完毕执行步骤11,让编码后的数据沿管线继续流转下去。这里我们主要看看DubboCodec是如何按照Dubbo协议对请求进行编码的。
在
Dubbo笔记 ⑩ : 消费者启动流程 – DubboProtocol#refer
,我们知道了 消费者会在 NettyClient 中建立 Netty 连接。其中 Netty#doOpen 实现如下:
@Override
protected void doOpen() throws Throwable {
final NettyClientHandler nettyClientHandler = new NettyClientHandler(getUrl(), this);
bootstrap = new Bootstrap();
bootstrap.group(nioEventLoopGroup)
.option(ChannelOption.SO_KEEPALIVE, true)
.option(ChannelOption.TCP_NODELAY, true)
.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
//.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, getTimeout())
.channel(NioSocketChannel.class);
if (getConnectTimeout() < 3000) {
bootstrap.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 3000);
} else {
bootstrap.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, getConnectTimeout());
}
bootstrap.handler(new ChannelInitializer() {
@Override
protected void initChannel(Channel ch) throws Exception {
// 使用 NettyCodecAdapter 适配器
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyClient.this);
ch.pipeline()//.addLast("logging",new LoggingHandler(LogLevel.INFO))//for debug
// 添加解码器 handler
.addLast("decoder", adapter.getDecoder())
// 添加编码器 handler
.addLast("encoder", adapter.getEncoder())
// 添加业务 handler
.addLast("handler", nettyClientHandler);
}
});
}
2. 提供者的注入时机
《深度剖析Apache Dubbo 核心技术内幕》 中关于 Netty流程描述如下
:
在客户端与服务端进行网络通信时,客户端会通过socket把需要发送的内容序列化为二进制流后发送出去,接着二进制流通过网络流向服务器端,服务端接收到该请求后会解析该请求包,然后反序列化后对请求进行处理。这看似是一个很简单的过程,但细细想来却会发现没有那么简单。下图显示的是客户端与服务端交互的流程。
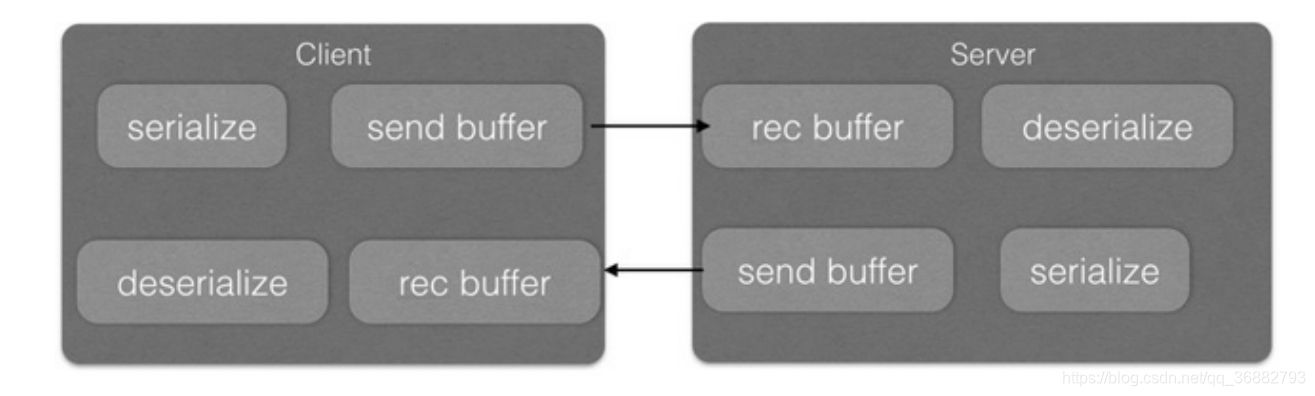
在客户端发送数据时,实际是把数据写入TCP发送缓存里,如果发送的包的大小比TCP发送缓存的容量大,那么这个数据包就会被分成多个包,通过socket多次发送到服务端。而服务端获取数据是从接收缓存里获取的,假设服务端第一次从接收缓存里获取的数据是整个包的一部分,这时就产生了半包现象。半包不是说只收到了全包的一半,是说收到了全包的一部分。
服务器读取到半包数据后,会对读取的二进制流进行解析,一般情况下会把二进制流反序列化为对象,但由于服务器只读取了客户端序列化对象后的一部分,所以反序列化会报错。
同理,如果发送的数据包大小比TCP发送缓存的容量小,并且假设TCP缓存可以存放多个包,那么客户端和服务端的一次通信就可能传递了多个包,这时服务端就可能从接收缓存一下读取了多个包,这样就出现了粘包现象。由于服务端从接收缓存获取的二进制流是多个对象转换来的,所以在后续的反序列化时肯定也会出错。
其实,出现粘包和半包的原因是TCP层不知道上层业务的包的概念,它只是简单地传递流,所以需要上层的应用层协议来识别读取的数据是不是一个完整的包。
在Netty中,每个Channel(NioSocketChannel)与NioEventLoopGroup中的某一个NioEventLoop固定关联,NettyServer会为每个接收的链接创建一个Channel对象,这个Channel对象也会与Worker NioEventLoopGroup中的某一个NioEventLoop固定关联。另外,每个NioEventLoop会管理一个Selector对象和一个线程,线程会不断检查注册到该Selector对象上的Channel是否有读取事件,如果有,则从TCP缓存读取数据
。
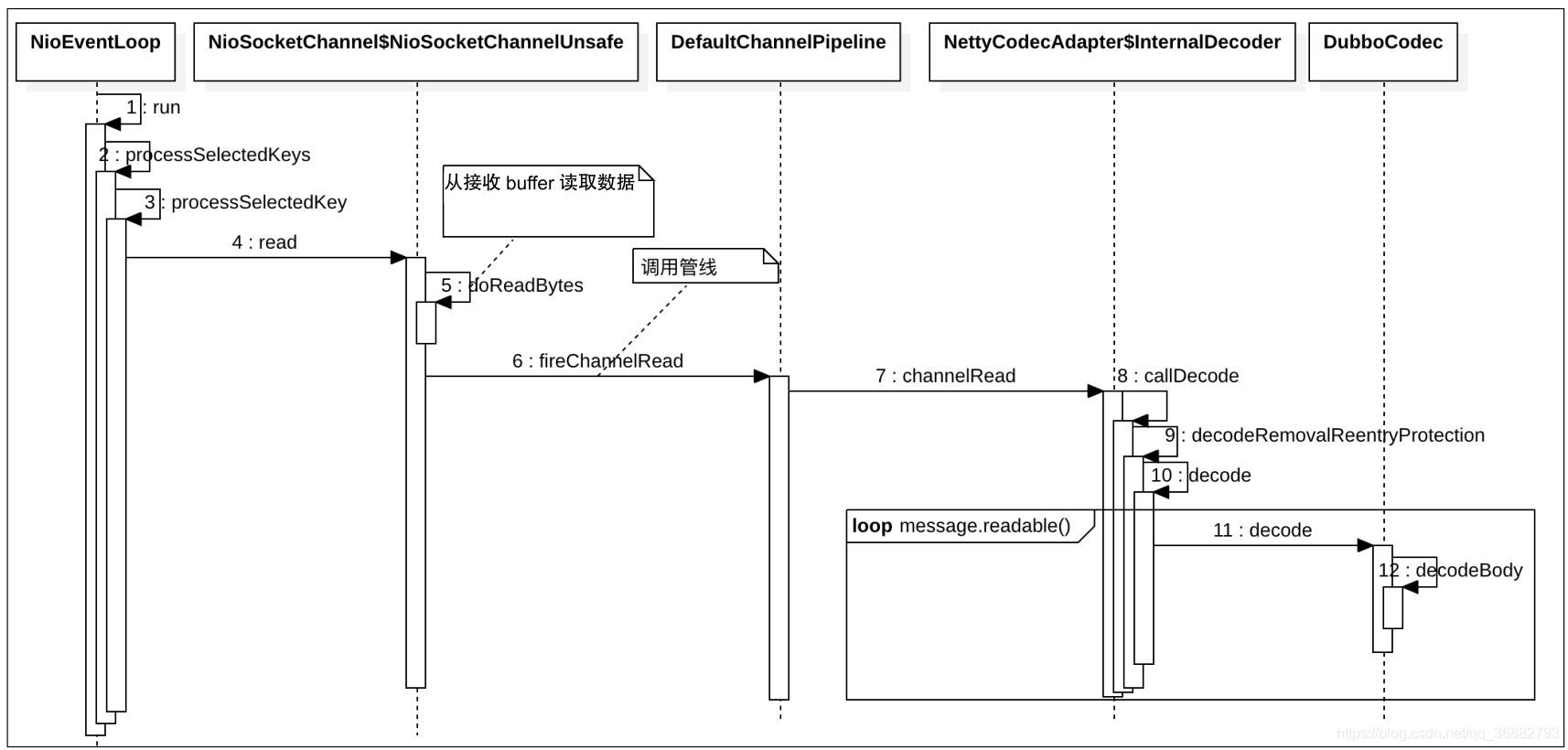
当有读取事件时,NioEventLoop关联的线程会从缓存读取数据,然后把数据传递给该Channel管理的管线中的handler,这里会把数据传递给NettyCodecAdapter的内部类InternalDecoder。
在
Dubbo笔记 ⑥ : 服务发布流程 – NettyServer
一文中,我们介绍了 Dubbo 提供者 启用 Netty 服务的过程。其中在 NettyServer#doOpen 方法中建立了Netty 服务,其实现如下:
@Override
protected void doOpen() throws Throwable {
bootstrap = new ServerBootstrap();
// 创建 boss 和 worker 线程池
bossGroup = new NioEventLoopGroup(1, new DefaultThreadFactory("NettyServerBoss", true));
workerGroup = new NioEventLoopGroup(getUrl().getPositiveParameter(Constants.IO_THREADS_KEY, Constants.DEFAULT_IO_THREADS),
new DefaultThreadFactory("NettyServerWorker", true));
// 业务 handler,这里将Netty 的各种请求分发给NettyServer 的方法,下面详述
final NettyServerHandler nettyServerHandler = new NettyServerHandler(getUrl(), this);
channels = nettyServerHandler.getChannels();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childOption(ChannelOption.TCP_NODELAY, Boolean.TRUE)
.childOption(ChannelOption.SO_REUSEADDR, Boolean.TRUE)
.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
// 创建 NettyCodecAdapter
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyServer.this);
ch.pipeline()//.addLast("logging",new LoggingHandler(LogLevel.INFO))//for debug
// 添加解码器 handler
.addLast("decoder", adapter.getDecoder())
// 添加编码器 handler
.addLast("encoder", adapter.getEncoder())
// 添加业务handler
.addLast("handler", nettyServerHandler);
}
});
// bind
// 绑定ip端口,启用netty服务
ChannelFuture channelFuture = bootstrap.bind(getBindAddress());
channelFuture.syncUninterruptibly();
channel = channelFuture.channel();
}
四、NettyCodecAdapter
上面我们发现,无论是消费者还是提供者,其编解码器都由 NettyCodecAdapter 来提供,下面我们来看 NettyCodecAdapter 的具体实现:
/**
* NettyCodecAdapter.
*/
final class NettyCodecAdapter {
/// 编码器:InternalEncoder 为 NettyCodecAdapter 内部类
private final ChannelHandler encoder = new InternalEncoder();
// 解码器 : InternalDecoder为 NettyCodecAdapter 内部类
private final ChannelHandler decoder = new InternalDecoder();
// SPI 接口。默认实现 DubboCountCodec
private final Codec2 codec;
....
public NettyCodecAdapter(Codec2 codec, URL url, org.apache.dubbo.remoting.ChannelHandler handler) {
this.codec = codec;
this.url = url;
this.handler = handler;
}
// 获取编码器
public ChannelHandler getEncoder() {
return encoder;
}
// 获取解码器
public ChannelHandler getDecoder() {
return decoder;
}
// 省略 InternalEncoder 和 InternalDecoder 两个内部类,下面会详细贴出分析
...
}
1. InternalEncoder
InternalEncoder 是 NettyCodecAdapter 的内部类,用于Dubbo协议编码。而 InternalEncoder 直接将编码过程委托给了 NettyCodecAdapter#codec 来处理。
// 内置编码器
private class InternalEncoder extends MessageToByteEncoder {
@Override
protected void encode(ChannelHandlerContext ctx, Object msg, ByteBuf out) throws Exception {
org.apache.dubbo.remoting.buffer.ChannelBuffer buffer = new NettyBackedChannelBuffer(out);
Channel ch = ctx.channel();
NettyChannel channel = NettyChannel.getOrAddChannel(ch, url, handler);
try {
//委托给 codec 来处理
codec.encode(channel, buffer, msg);
} finally {
NettyChannel.removeChannelIfDisconnected(ch);
}
}
}
1.1 调用时机
InternalEncoder#encode 将编码过程委托给了 NettyCodecAdapter#codec 来处理,我们上面提到过 NettyCodecAdapter#codec 的实现了是 DubboCountCodec。这里我们来看一下 InternalEncoder#encode 是什么时候调用的。
InternalEncoder 的结构如下图:
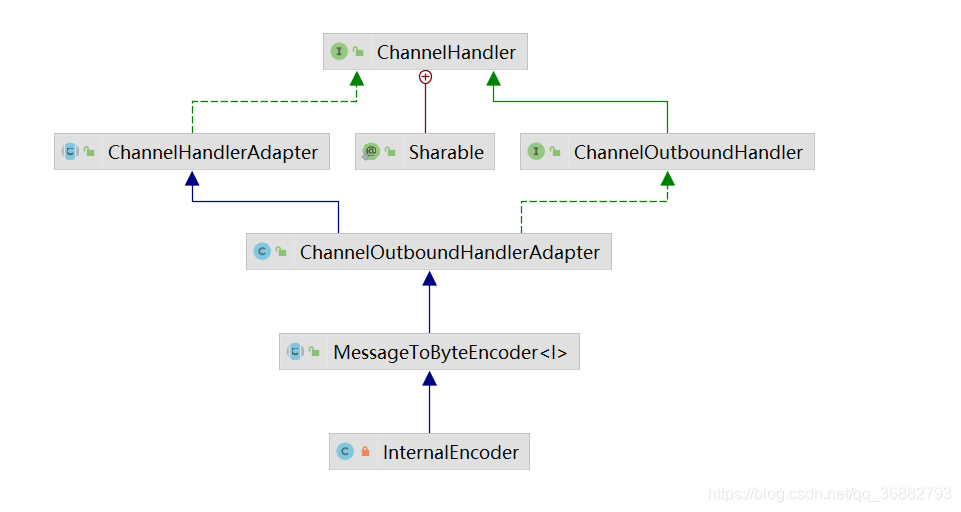
这里我们看到 InternalEncoder 继承了 ChannelOutboundHandlerAdapter 类,而通过 调用ChannelOutboundHandlerAdapter#write 方法我们可以向 Netty 通道中写入数据。而 MessageToByteEncoder 重写了 ChannelOutboundHandlerAdapter#write 方法。所以对于消费者来说要向通道中写数据(发送请求数据给提供者),则会调用MessageToByteEncoder#write 来写数据。
MessageToByteEncoder#write 如下:
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ByteBuf buf = null;
try {
if (acceptOutboundMessage(msg)) {
@SuppressWarnings("unchecked")
I cast = (I) msg;
buf = allocateBuffer(ctx, cast, preferDirect);
try {
// 调用 encode 方法 对消息进行编码。即 InternalEncoder#encode 方法
encode(ctx, cast, buf);
} finally {
ReferenceCountUtil.release(cast);
}
if (buf.isReadable()) {
ctx.write(buf, promise);
} else {
buf.release();
ctx.write(Unpooled.EMPTY_BUFFER, promise);
}
buf = null;
} else {
ctx.write(msg, promise);
}
}
...
}
上面我们看到 MessageToByteEncoder#write 中被调用了 InternalEncoder#encode 方法。即当消息被写入通道前会被 InternalEncoder#encode 进行编码。
2. InternalDecoder
InternalDecoder 是 NettyCodecAdapter 的内部类,用于Dubbo协议解码。由于要考虑半包的问题,InternalDecoder 的实现相较于InternalEncoder 更加复杂一下,如下:
// 内置解码器
private class InternalDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf input, List<Object> out) throws Exception {
ChannelBuffer message = new NettyBackedChannelBuffer(input);
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
Object msg;
int saveReaderIndex;
try {
// decode object.
// 具体解析二进制位的 Dubbo协议帧对象
do {
// 保存缓存的当下读取下标
saveReaderIndex = message.readerIndex();
try {
// 解码数据,解析二进制数据为对象
msg = codec.decode(channel, message);
} catch (IOException e) {
throw e;
}
// 如果返回 NEED_MORE_INPUT,则说明遇到了半包,重置缓存读取下标,跳出循环,等待后面数据达到
if (msg == Codec2.DecodeResult.NEED_MORE_INPUT) {
message.readerIndex(saveReaderIndex);
break;
} else {
//is it possible to go here ?
if (saveReaderIndex == message.readerIndex()) {
throw new IOException("Decode without read data.");
}
// 把解码成功的对象放入 out 列表
if (msg != null) {
out.add(msg);
}
}
// 如果message 仍有数据可读取,则继续循环
} while (message.readable());
} finally {
// 如果断连则移除通道
NettyChannel.removeChannelIfDisconnected(ctx.channel());
}
}
}
在上面我们提到了提供者在解析数据的时候可能会遇到半包的情况。如果遇到了半包,解码器会返回
Codec2.DecodeResult.NEED_MORE_INPUT
,此时则重置缓存读取下标,跳出循环,等待后面数据达到后一起读取。如果解码成功,则将结果保存到 out 集合中。
2.1 调用时机
InternalDecoder 的结构如下,同样 InternalDecoder 也继承了 ChannelInboundHandlerAdapter类,通过
ChannelOutboundHandlerAdapter#channelRead
方法可以实现在通道中读取数据。
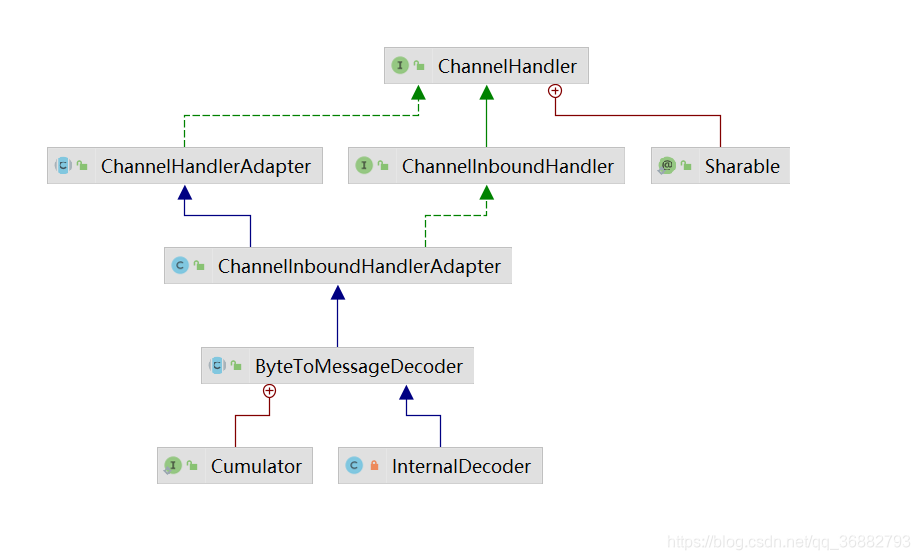
而 ByteToMessageDecoder 也重写了
ChannelInboundHandlerAdapter#channelRead
方法。如下:
// ByteToMessageDecoder#channelRead
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof ByteBuf) {
CodecOutputList out = CodecOutputList.newInstance();
try {
first = cumulation == null;
cumulation = cumulator.cumulate(ctx.alloc(),
first ? Unpooled.EMPTY_BUFFER : cumulation, (ByteBuf) msg);
// 尝试解码,解码后的数据会保存到 out 中
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Exception e) {
throw new DecoderException(e);
} finally {
if (cumulation != null && !cumulation.isReadable()) {
numReads = 0;
cumulation.release();
cumulation = null;
} else if (++ numReads >= discardAfterReads) {
// We did enough reads already try to discard some bytes so we not risk to see a OOME.
// See https://github.com/netty/netty/issues/4275
numReads = 0;
discardSomeReadBytes();
}
int size = out.size();
firedChannelRead |= out.insertSinceRecycled();
// 传播给下一个 Channel
fireChannelRead(ctx, out, size);
out.recycle();
}
} else {
ctx.fireChannelRead(msg);
}
}
这里可以看到,数据会通过
callDecode(ctx, cumulation, out);
方法解码,解码后通过
fireChannelRead(ctx, out, size);
方法传播给下一个 Channel。
其中
callDecode(ctx, cumulation, out);
调用的是 ByteToMessageDecoder#callDecode。 具体实现如下:
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
try {
// 使用循环,如果有可能则对多个 Dubbo帧进行解析
while (in.isReadable()) {
...
// 具体解析过程
decodeRemovalReentryProtection(ctx, in, out);
...
}
} catch (DecoderException e) {
throw e;
} catch (Exception cause) {
throw new DecoderException(cause);
}
}
final void decodeRemovalReentryProtection(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)
throws Exception {
decodeState = STATE_CALLING_CHILD_DECODE;
try {
// 调用 InternalDecoder#decode 进行解码
decode(ctx, in, out);
} finally {
boolean removePending = decodeState == STATE_HANDLER_REMOVED_PENDING;
decodeState = STATE_INIT;
if (removePending) {
fireChannelRead(ctx, out, out.size());
out.clear();
handlerRemoved(ctx);
}
}
}
3. NettyCodecAdapter#codec
上面 知道编解码分别是通过
NettyCodecAdapter#getEncoder
和
NettyCodecAdapter#getDecoder
两个方法获取。而这两个方法返回的是 NettyCodecAdapter 的内部类 InternalEncoder 和 InternalDecoder 。具体的编解码逻辑 InternalEncoder 和 InternalDecoder 都委托给了 NettyCodecAdapter#codec 来处理,那么我们需要确定一下 NettyCodecAdapter#codec 具体是哪个实现类。
NettyCodecAdapter#codec 是 SPI 接口,会通过SPI 适配器获取具体实现。
在 DubboProtocol#createServer 中会指定了编解码器协议为 dubbo。
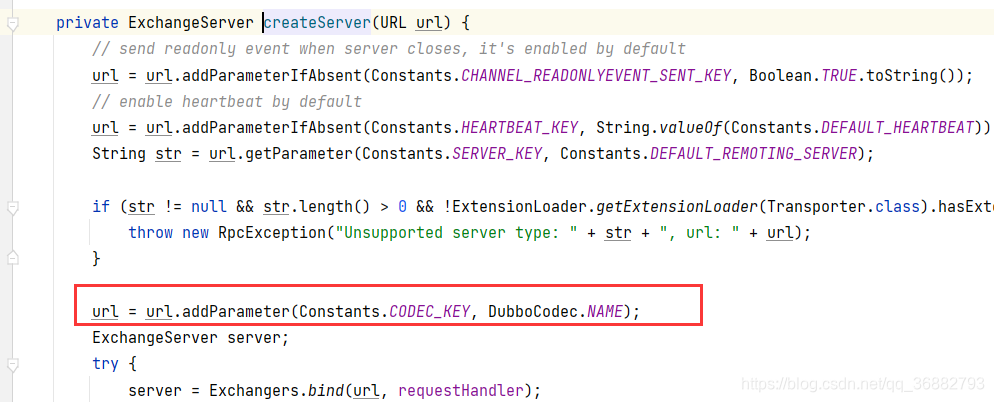
而 org.apache.dubbo.remoting.Codec2 SPI 文件中指定了 Dubbo协议对应 DubboCountCodec :
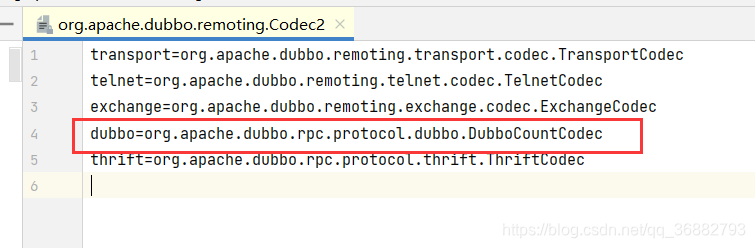
所以我们 NettyCodecAdapter#codec 对应的实现类是 DubboCountCodec 。
五、DubboCountCodec
上面我们介绍 InternalEncoder & InternalDecoder 两个类以及他们的编解码方法的调用时机,而 InternalEncoder & InternalDecoder 的编解码都委托给 DubboCountCodec 来处理,下面我们来看一下 DubboCountCodec 的实现。
public final class DubboCountCodec implements Codec2 {
private DubboCodec codec = new DubboCodec();
@Override
public void encode(Channel channel, ChannelBuffer buffer, Object msg) throws IOException {
codec.encode(channel, buffer, msg);
}
@Override
public Object decode(Channel channel, ChannelBuffer buffer) throws IOException {
int save = buffer.readerIndex();
MultiMessage result = MultiMessage.create();
do {
// 解码
Object obj = codec.decode(channel, buffer);
// 半包重置缓存下标
if (Codec2.DecodeResult.NEED_MORE_INPUT == obj) {
buffer.readerIndex(save);
break;
} else {
// 解码成功,则将解码结果保存到 result中
result.addMessage(obj);
// 记录解码后的消息长度
logMessageLength(obj, buffer.readerIndex() - save);
save = buffer.readerIndex();
}
} while (true);
if (result.isEmpty()) {
return Codec2.DecodeResult.NEED_MORE_INPUT;
}
if (result.size() == 1) {
return result.get(0);
}
return result;
}
// 记录消息长度
private void logMessageLength(Object result, int bytes) {
if (bytes <= 0) {
return;
}
if (result instanceof Request) {
try {
((RpcInvocation) ((Request) result).getData()).setAttachment(
Constants.INPUT_KEY, String.valueOf(bytes));
} catch (Throwable e) {
/* ignore */
}
} else if (result instanceof Response) {
try {
((RpcResult) ((Response) result).getResult()).setAttachment(
Constants.OUTPUT_KEY, String.valueOf(bytes));
} catch (Throwable e) {
/* ignore */
}
}
}
}
这里 DubboCountCodec#encode 和 DubboCountCodec#decode 都委托给了 DubboCodec 来处理(俄罗斯套娃)。
1. DubboCodec#encode
DubboCodec 中并没有 encode方法的实现,其具体实现在其父类 ExchangeCodec#encode中,如下:
// org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#encode
@Override
public void encode(Channel channel, ChannelBuffer buffer, Object msg) throws IOException {
// 请求信息编码
if (msg instanceof Request) {
encodeRequest(channel, buffer, (Request) msg);
} else if (msg instanceof Response) {
// 响应信息编码
encodeResponse(channel, buffer, (Response) msg);
} else {
// 其他信息编码
super.encode(channel, buffer, msg);
}
}
这里我们看到这里的编码分为请求信息编码和响应信息编码。其逻辑基本相同。下面我们来具体看。
1.1 ExchangeCodec#encodeRequest
ExchangeCodec#encodeRequest 完成了请求信息的编码,包括对 Dubbo协议头 和 内容的编码。具体如下:
protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {
// 1. 获取序列化扩展实现
Serialization serialization = getSerialization(channel);
// header.
// 2. 创建 Dubbo协议 Header 的字节数组,长度为 16
byte[] header = new byte[HEADER_LENGTH];
// set magic number.
// 3. 设置字节数据的魔数
Bytes.short2bytes(MAGIC, header);
// set request and serialization flag.
// 4. 设置请求类型和序列化类型标记到协议头第三个字节低四位
header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());
// 设置请求方式 到 高四位
if (req.isTwoWay()) {
header[2] |= FLAG_TWOWAY;
}
if (req.isEvent()) {
header[2] |= FLAG_EVENT;
}
// 5. 由于 是request类型,所以第4字节的响应码是不需要设置的
// 6. 把请求id写入协议头的 5-12 字节,
// set request id.
Bytes.long2bytes(req.getId(), header, 4);
// encode request data.
// 7. 使用上面获取的序列化方式对象数据部分进行编码,并把协议数据部分写入缓存(buffer)
int savedWriteIndex = buffer.writerIndex();
// 8. 设置 可写缓冲区 索引后移16位,为协议头预留空间
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
// 构建 输出流
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
// 序列化输出对象
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
// 9. 对事件消息 和请求消息的处理
if (req.isEvent()) {
encodeEventData(channel, out, req.getData());
} else {
encodeRequestData(channel, out, req.getData(), req.getVersion());
}
// 刷新缓存
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
bos.flush();
bos.close();
int len = bos.writtenBytes();
// 10. checkPayload检查协议数据部分是否超过了设置的大小,如果是则抛出异常
checkPayload(channel, len);
// 如果检查合法,则把协议数据部分的大小写入协议头的第12~16字节。
Bytes.int2bytes(len, header, 12);
// write
// 11. 将协议头写入缓存
// 首先把缓存的写入下标移动到写入协议数据前的位置。
// 然后把协议头写入缓存,这时缓存里存放了完整的Dubbo协议帧(协议头+协议数据体),
// 最后把缓存的写入下标设置为写入Dubbo协议帧后面的位置。
buffer.writerIndex(savedWriteIndex);
buffer.writeBytes(header); // write header.
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
}
我们这里按照注释顺序来分析:
-
1~6 步设置了Dubbo协议头的 前12个字节。
-
7~8 步是为了给协议头预留空间,如下图是 ChannelBuffer 的结构图。此处将 writerIndex 后移16字节,是为了预留空间将之后协议头写入进去。
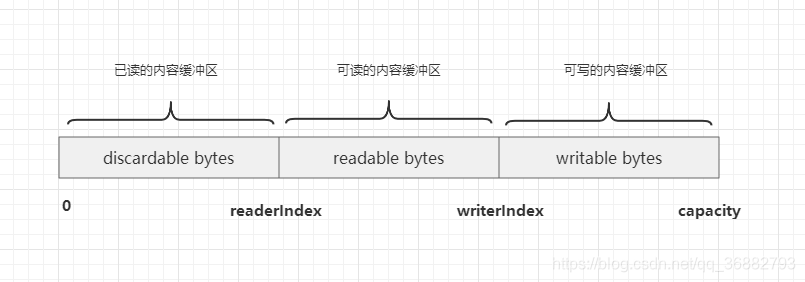
-
9步是用来处理协议内容,将协议内容写入到 ChannelBuffer 中。此处交由 encodeEventData 和 encodeRequestData 方法来处理,其中 encodeEventData 则是直接调用
out.writeObject(data);
将事件内容写入到out 。这里我们来看一下encodeRequestData 的实现,该方法调用的是 DubboCodec#encodeRequestData,如下:// DubboCodec#encodeRequestData @Override protected void encodeRequestData(Channel channel, ObjectOutput out, Object data, String version) throws IOException { RpcInvocation inv = (RpcInvocation) data; out.writeUTF(version); out.writeUTF(inv.getAttachment(Constants.PATH_KEY)); out.writeUTF(inv.getAttachment(Constants.VERSION_KEY)); out.writeUTF(inv.getMethodName()); out.writeUTF(ReflectUtils.getDesc(inv.getParameterTypes())); Object[] args = inv.getArguments(); if (args != null) { for (int i = 0; i < args.length; i++) { out.writeObject(encodeInvocationArgument(channel, inv, i)); } } out.writeObject(RpcUtils.getNecessaryAttachments(inv)); } -
10步 检查协议数据部分是否超过了设置的大小,如果是则抛出异常。其实现如下
// AbstractCodec#checkPayload protected static void checkPayload(Channel channel, long size) throws IOException { // 最大大小, 8M int payload = Constants.DEFAULT_PAYLOAD; if (channel != null && channel.getUrl() != null) { payload = channel.getUrl().getParameter(Constants.PAYLOAD_KEY, Constants.DEFAULT_PAYLOAD); } // 当前数据大小大于 8M 则抛出异常 if (payload > 0 && size > payload) { ExceedPayloadLimitException e = new ExceedPayloadLimitException("Data length too large: " + size + ", max payload: " + payload + ", channel: " + channel); logger.error(e); throw e; } } -
11步则将请求头写入到 ChannelBuffer 中。首先将 writerIndex 重置到 savedWriteIndex,然后再写入协议头,最后将 writerIndex 设置为
savedWriteIndex + HEADER_LENGTH + len
。
1.2 ExchangeCodec#encodeResponse
ExchangeCodec#encodeResponse 对响应信息进行编码与 ExchangeCodec#encodeRequest 代码类基本类似。不同之处在于,前者需要对协议头的第4字节写入响应类型,代码已有足够注释,这里不再赘述。
protected void encodeResponse(Channel channel, ChannelBuffer buffer, Response res) throws IOException {
int savedWriteIndex = buffer.writerIndex();
try {
// 1. 获取序列化扩展实现
Serialization serialization = getSerialization(channel);
// header.
// 2. 创建 Dubbo协议 Header 的字节数组,长度为 16
byte[] header = new byte[HEADER_LENGTH];
// set magic number.
// 3. 前两个字节设置字节数据的魔数
Bytes.short2bytes(MAGIC, header);
// set request and serialization flag.
// 4. 第三个字节设置请求类型和序列化类型标
header[2] = serialization.getContentTypeId();
if (res.isHeartbeat()) {
header[2] |= FLAG_EVENT;
}
// 5. 第四个字节设置响应类型
// set response status.
byte status = res.getStatus();
header[3] = status;
// set request id.
// 6. 把请求id写入协议头的 5-12 字节,
Bytes.long2bytes(res.getId(), header, 4);
// 7. 使用上面获取的序列化方式对象数据部分进行编码,并把协议数据部分写入缓存(buffer)
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
// 8. 设置 可写缓冲区 索引后移16位,为协议头预留空间
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
// encode response data or error message.
// 9. 如果响应状态为成功,则处理心跳消息 和响应消息内容
if (status == Response.OK) {
if (res.isHeartbeat()) {
encodeHeartbeatData(channel, out, res.getResult());
} else {
encodeResponseData(channel, out, res.getResult(), res.getVersion());
}
} else {
out.writeUTF(res.getErrorMessage());
}
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
bos.flush();
bos.close();
int len = bos.writtenBytes();
// 10. checkPayload检查协议数据部分是否超过了设置的大小,如果是则抛出异常
checkPayload(channel, len);
// 如果检查合法,则把协议数据部分的大小写入协议头的第12~16字节。
Bytes.int2bytes(len, header, 12);
// write
// 11. 将协议头写入缓存
// 首先把缓存的写入下标移动到写入协议数据前的位置。
// 然后把协议头写入缓存,这时缓存里存放了完整的Dubbo协议帧(协议头+协议数据体),
// 最后把缓存的写入下标设置为写入Dubbo协议帧后面的位置。
buffer.writerIndex(savedWriteIndex);
buffer.writeBytes(header); // write header.
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
} catch (Throwable t) {
....
}
}
2. DubboCodec#decode
上面分析完 编码过程后,我们这里通过 DubboCodec#decode 来分析一下解码过程。DubboCodec#decode 的具体实现在其父类 ExchangeCodec 中
// ExchangeCodec#decode
@Override
public Object decode(Channel channel, ChannelBuffer buffer) throws IOException {
// 读取 Dubbo 协议头 到 header 中
int readable = buffer.readableBytes();
byte[] header = new byte[Math.min(readable, HEADER_LENGTH)];
buffer.readBytes(header);
// 解析 Dubbo协议数据部分
return decode(channel, buffer, readable, header);
}
@Override
protected Object decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header) throws IOException {
// check magic number.
// 检查魔数,确定为 Dubbo协议帧
if (readable > 0 && header[0] != MAGIC_HIGH
|| readable > 1 && header[1] != MAGIC_LOW) {
int length = header.length;
if (header.length < readable) {
header = Bytes.copyOf(header, readable);
buffer.readBytes(header, length, readable - length);
}
for (int i = 1; i < header.length - 1; i++) {
if (header[i] == MAGIC_HIGH && header[i + 1] == MAGIC_LOW) {
buffer.readerIndex(buffer.readerIndex() - header.length + i);
header = Bytes.copyOf(header, i);
break;
}
}
return super.decode(channel, buffer, readable, header);
}
// check length.
// 检查是否读取了一个完整的 Dubbo协议头
if (readable < HEADER_LENGTH) {
return DecodeResult.NEED_MORE_INPUT;
}
// get data length.
// 从协议头的最后四个字节读取 协议数据的大小
int len = Bytes.bytes2int(header, 12);
// 检查数据大小的合法性
checkPayload(channel, len);
// 如果遇到半包问题,直接返回 (可读数据小于 协议头 + 协议体 则说明当前是半包)
int tt = len + HEADER_LENGTH;
if (readable < tt) {
return DecodeResult.NEED_MORE_INPUT;
}
// limit input stream.
ChannelBufferInputStream is = new ChannelBufferInputStream(buffer, len);
try {
// 解析协议数据部分
return decodeBody(channel, is, header);
} finally {
....
}
}
可以看到, 上面诸多代码都用来解码 Dubbo协议头,在解析协议头的时候判断如果遇到了半包,则直接返回,等待后续数据到来后再进行解码。
解析协议内容的工作则交由
decodeBody(channel, is, header);
来完成,其实现在 DubboCodec#decodeBody 中,具体如下:
@Override
protected Object decodeBody(Channel channel, InputStream is, byte[] header) throws IOException {
// 解析请求类型和消费端序列化类型
byte flag = header[2], proto = (byte) (flag & SERIALIZATION_MASK);
// get request id.
// 获取请求id
long id = Bytes.bytes2long(header, 4);
// 解码响应
if ((flag & FLAG_REQUEST) == 0) {
// decode response.
Response res = new Response(id);
// 事件类型
if ((flag & FLAG_EVENT) != 0) {
res.setEvent(Response.HEARTBEAT_EVENT);
}
// get status.
// 获取响应码
byte status = header[3];
res.setStatus(status);
try {
// 使用与序列化一致的反序列化类对数据部分进行解码
ObjectInput in = CodecSupport.deserialize(channel.getUrl(), is, proto);
if (status == Response.OK) {
Object data;
// 解码心跳数据
if (res.isHeartbeat()) {
data = decodeHeartbeatData(channel, in);
} else if (res.isEvent()) {
// 解码事件
data = decodeEventData(channel, in);
} else {
// 解码响应信息
DecodeableRpcResult result;
if (channel.getUrl().getParameter(
Constants.DECODE_IN_IO_THREAD_KEY,
Constants.DEFAULT_DECODE_IN_IO_THREAD)) {
result = new DecodeableRpcResult(channel, res, is,
(Invocation) getRequestData(id), proto);
result.decode();
} else {
result = new DecodeableRpcResult(channel, res,
new UnsafeByteArrayInputStream(readMessageData(is)),
(Invocation) getRequestData(id), proto);
}
data = result;
}
res.setResult(data);
} else {
res.setErrorMessage(in.readUTF());
}
} catch (Throwable t) {
if (log.isWarnEnabled()) {
log.warn("Decode response failed: " + t.getMessage(), t);
}
res.setStatus(Response.CLIENT_ERROR);
res.setErrorMessage(StringUtils.toString(t));
}
return res;
} else {
// decode request.
// 请求类型为请求类型
Request req = new Request(id);
req.setVersion(Version.getProtocolVersion());
req.setTwoWay((flag & FLAG_TWOWAY) != 0);
if ((flag & FLAG_EVENT) != 0) {
req.setEvent(Request.HEARTBEAT_EVENT);
}
try {
Object data;
// 使用与序列化一致的反序列化类对数据部分进行解码
ObjectInput in = CodecSupport.deserialize(channel.getUrl(), is, proto);
if (req.isHeartbeat()) {
// 解码心跳数据
data = decodeHeartbeatData(channel, in);
} else if (req.isEvent()) {
// 解码事件
data = decodeEventData(channel, in);
} else {
// 解码响应信息
DecodeableRpcInvocation inv;
if (channel.getUrl().getParameter(
Constants.DECODE_IN_IO_THREAD_KEY,
Constants.DEFAULT_DECODE_IN_IO_THREAD)) {
inv = new DecodeableRpcInvocation(channel, req, is, proto);
inv.decode();
} else {
inv = new DecodeableRpcInvocation(channel, req,
new UnsafeByteArrayInputStream(readMessageData(is)), proto);
}
data = inv;
}
req.setData(data);
} catch (Throwable t) {
// ...
// bad request
req.setBroken(true);
req.setData(t);
}
return req;
}
}
上面的代码比较简单,其流程与编码时的流程是相反的。值得注意的是,decode 方法在过程中使用“自定义协议header+body”的方式来解决粘包、半包问题,其中header记录了body 的大小,这种方式便于协议的升级。另外需要注意的是,在读取header 后,message的读取指针已经后移了,如果后面发现出现了半包现象,则需要把读取指针重置。
以上:内容部分参考
《深度剖析Apache Dubbo 核心技术内幕》
https://dubbo.apache.org/zh/docs/v2.7/dev/source
https://blog.csdn.net/shenchaohao12321/article/details/89713518
https://blog.csdn.net/lxgwm2008/article/details/7735231
如有侵扰,联系删除。 内容仅用于自我记录学习使用。如有错误,欢迎指正