论文题目(Title):
Multi-Modal Sarcasm Detection in Twitter with Hierarchical Fusion Model
研究问题(Question):
主要研究了推特中由文本和图像组成的推文的多模态讽刺检测
研究动机(Motivation):
以往的讽刺检测工作主要集中在文本上。然而,越来越多的社交媒体平台(如Twitter)允许用户创建多模式消息,包括文本、图像和视频。仅通过文本来检测多模型信息中的讽刺是不够的。
主要贡献(Contribution):
提出了一种新的层次融合模型来解决具有挑战性的推特中的多模态反讽检测任务。是第一个将图像、属性和文本这三种形态深度融合在一起的,而不是简单的连接推特讽刺检测。
研究思路(Idea):
利用了三种类型的特征,即文本、图像和图像属性特征,并以一种新颖的方式融合它们。在早期融合过程中,使用属性特征初始化双向LSTM网络(Bi-LSTM),然后使用该网络提取文本特征。然后将三个特征进行表示融合,将它们转换为重建的表示向量。模态融合层对向量进行加权平均,并将它们送入分类层以产生最终结果。
研究方法(Method):

研究过程(Process):
1.数据集(Dataset)
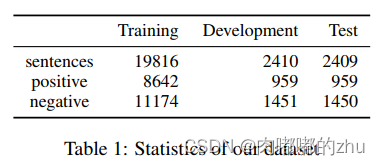
2.评估指标(Evaluation)
F-score,Precision,Accuracy,Recall
3.实验结果(Result)
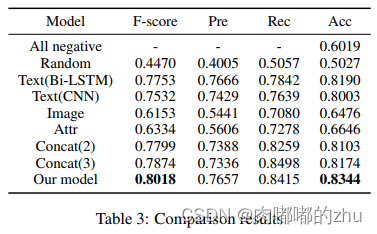
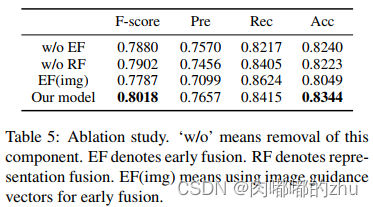
总结(Conclusion):
作者提出了一种新的分层融合模型,以充分利用三种模态(图像、文本和图像属性)来解决具有挑战性的多模态讽刺检测任务。评估结果证明了提出的模型的有效性和三种模式的有用性。在未来的工作中,将把其他模态,如音频,纳入到讽刺检测任务中,也将研究在所提出的模型中使用常识知识。