python
网络爬虫的本质就是两步:
- 设置请求参数(url,headers,cookies,post或get验证等)访问目标站点的服务器;
- 解析服务器返回的文档,提取需要的信息。
而API的工作机制与爬虫的两步类似,但也有些许不同:
-
1、
API
一般只需要设置
url
即可,且请求方式一般为
“get”
方式 -
2、
API
服务器返回的通常是
json
或
xml
格式的数据,解析更简单
本篇我们就演示如何运用Python结合百度地图API来批量获取想要的信息。
-
访问百度地图需要一个信令(
ak
), 具体申请百度
api
的
ak
网上都有教程, 这里就不叙述了… -
Place API
及
Web
服务
API
-
打开百度地图
API
的
POI
模块,网址:http://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-placeapi,这个页面详细介绍了
Place API
的请求参数及返回数据的情况。 - 今天我们使用百度地图api的地点检索
-
打开百度地图
import requests
import json
import pymysql
ak = '你自己申请的百度地图api的ak'
url = 'http://api.map.baidu.com/place/v2/search?query=药店®ion=郑州&output=json&output=json&ak={}&page_num={}&page_size=20'
# query=药店 是你想查询的内容
# region=郑州 是你想查询的城市
# page_num={} 是页码, 意思是第几页
# page_size=20 是每页显示的个数, 最大是20个
i = 0 # 这里可以使用for循环 ,不过容易出现并发量超过约定,所以我这里先不用循环了
response = requests.get(url.format(ak,i)) # 对网页进行请求
jsondata = json.loads(response.text) # 对下载的内容进行loads一下
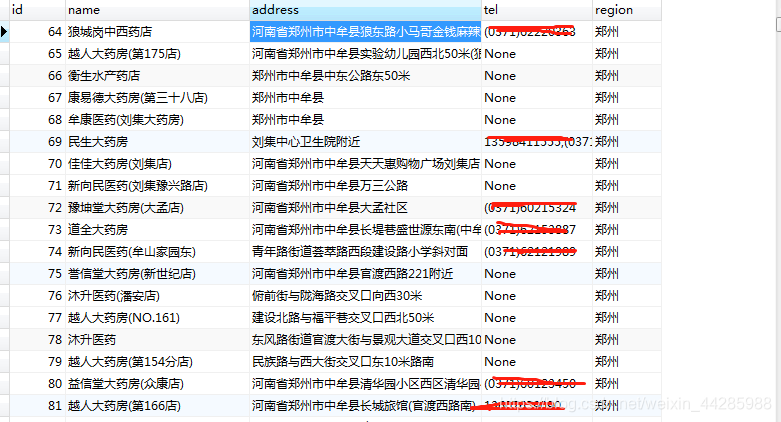
for j in jsondata['results']:
name = j.get('name')
print('商店名字是:', name)
# print(type(name))
address = j.get('address')
print('详细地址是:', address)
tel = j.get('telephone')
print('联系电话是:', tel)
print('*' * 50)
# 我做的是存入mysql的操作, 具体结果如下:
版权声明:本文为weixin_44285988原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。