目前网络上已有很多文章讲解了zookeeper的选举机制,但都比较抽象难懂,于是写下此文,用最通俗易懂的语言阐述zookeeper的选举机制,希望能帮助大家理解
zookeeper的选举机制一言以蔽之:得票数超过半数的服务器就是leader
举例:zookeeper节点为5台
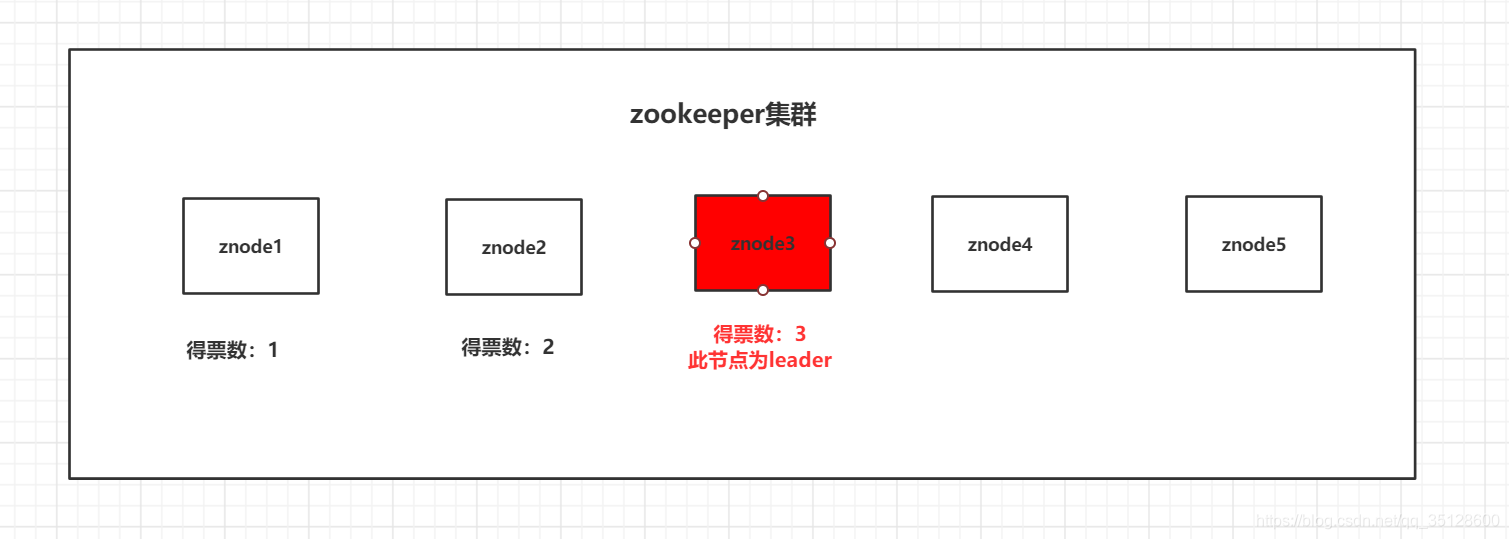
只要有一台节点的得票数为3 即为leader, 其他节点统统是follower
那么znode是如何投票呢?
假设这五台服务器它们都是最新启动的,没有历史数据,那么投票是根据两点决定的:
1. 启动顺序
2. Myid
Myid是提供应用的唯一标识
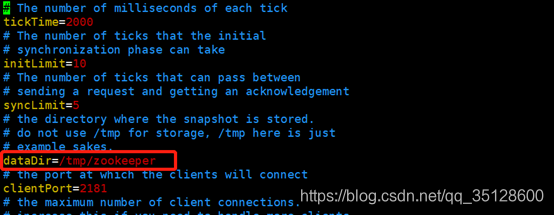
在 Zookeeper 集群中,每个节点需要一个唯一标识。这个唯一标识要求是自然数。
且唯一标识保存位置是:$dataDir/myid。
其中 dataDir 为配置文件 zoo.cfg 中的配置参数
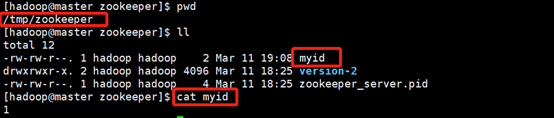
在 data 目录中创建文件 myid,为应用提供唯一标识。本环境中使用 1、2、3、4、5 作为每个节点的唯一标识。
那么此时的zookeeper集群应该长这个样子:
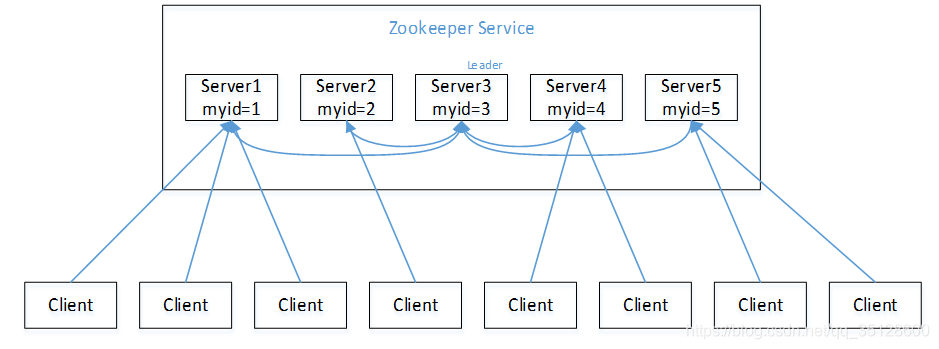
回到上文,投票是根据启动顺序和myid两点决定的,那么我们假设启动顺序是依次进行:
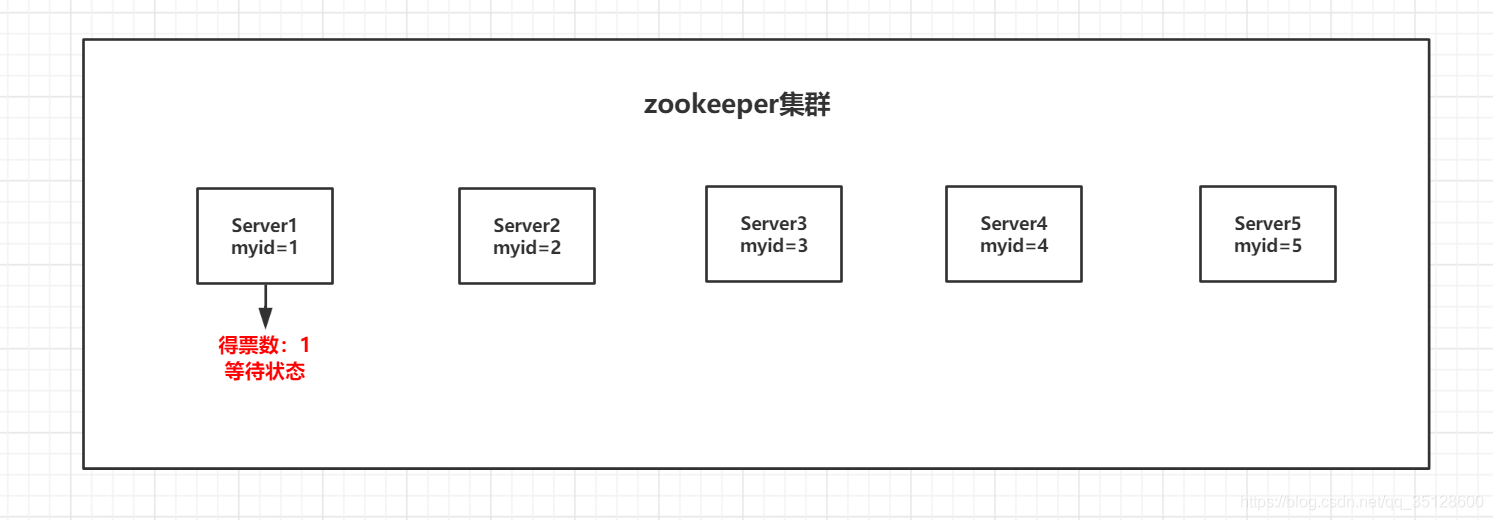
(1)服务器1启动,此时只有它一台服务器启动了,先给自己投一票,因为没超过半数,所以一直处于等待状态(LOOKING)
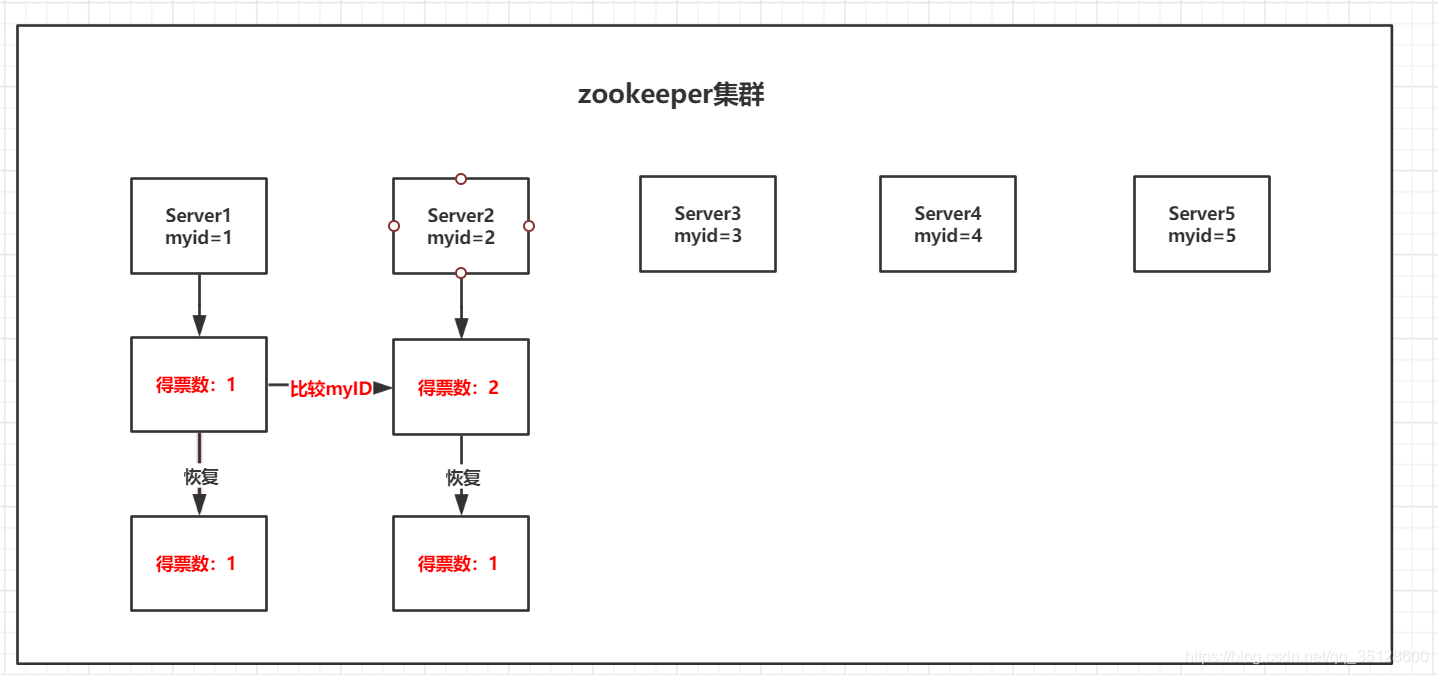
(2)服务器2启动,先给自己投一票,然后它与最开始启动的服务器1进行通信,互相交换自己的选举结果,因为各自得票都是1票,所以开始比较myid的值,于是server2胜出,Server1将自己的一票投给Server2,但即便如此Server2的票数还是没有达到超过半数以上,所以服务器1、2还是继续保持LOOKING状态,恢复到各自得票数为1
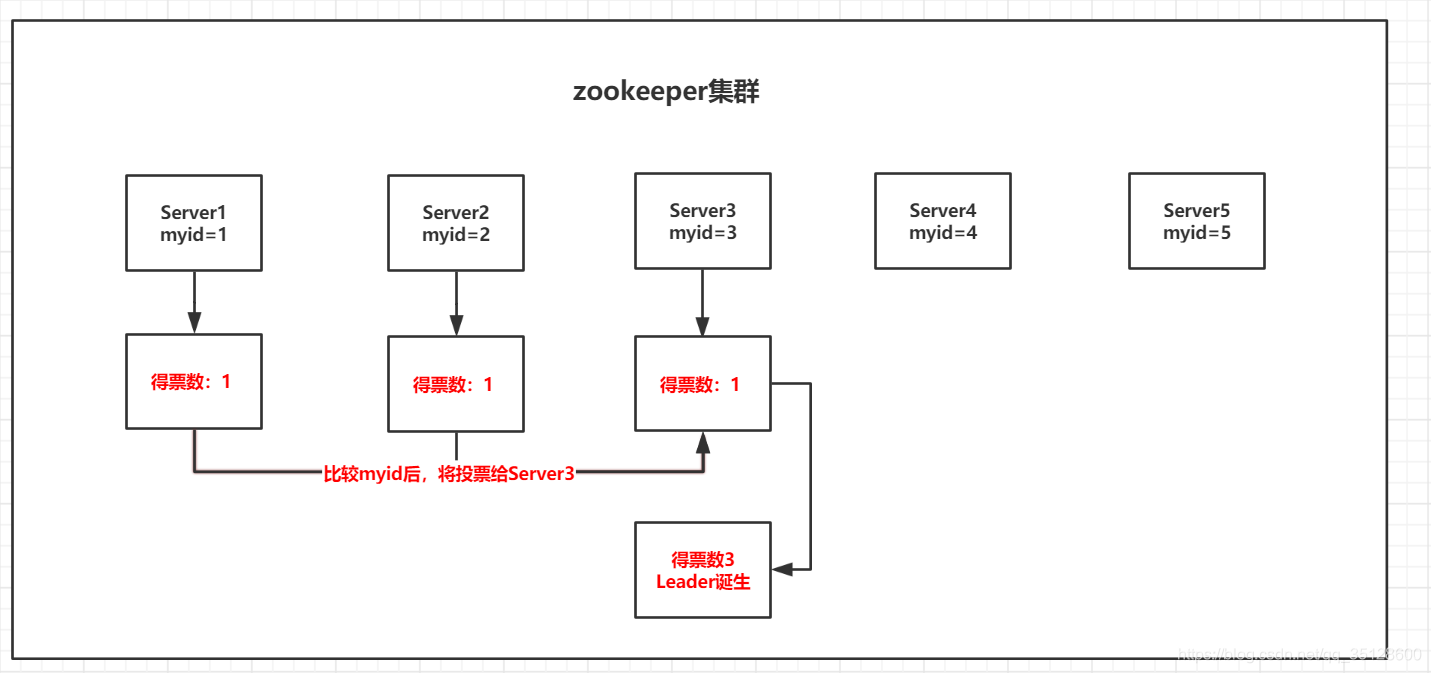
(3)服务器3启动,根据前面的理论分析,服务器3先给自己投一票,然后它与最开始启动的服务器1,服务器2进行通信,互相交换自己的选举结果,因为各自得票都是1票,所以开始比较myid的值,于是server3胜出,Server1和Server2将自己的一票都投给Server3,此时Server3得票数超过半数,所以它成为了这次选举的Leader。
(4)此时服务器4,5启动,由于Servre3已经是Leader,所以Server4,5只能是Follower
至此选举结束
2.那么我们假设启动顺序是乱序的,再走一遍:
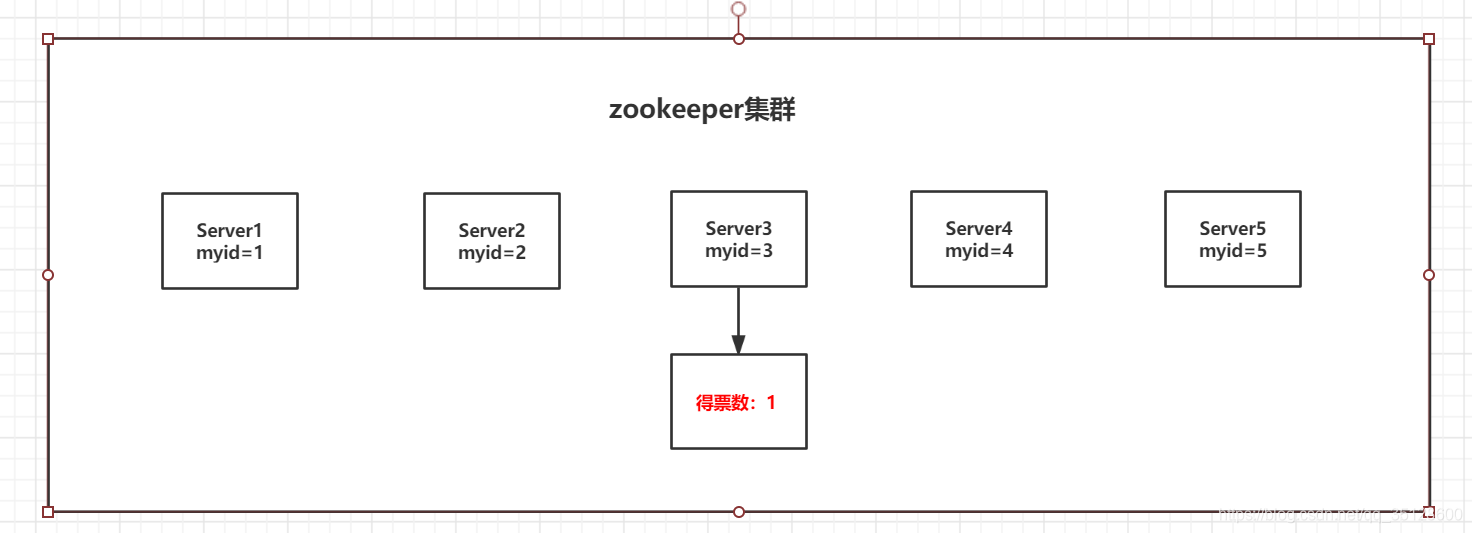
(1)服务器3先启动,此时只有它一台服务器启动了,先给自己投一票,因为没超过半数,所以一直处于等待状态(LOOKING)
(2)然后服务器2启动,先给自己投一票,然后它与最开始启动的服务器3进行通信,互相交换自己的选举结果,因为各自得票都是1票,所以开始比较myid的值,于是server3胜出,Server2将自己的一票投给Server3,但即便如此Server3的票数还是没有达到超过半数以上,所以服务器2、3还是继续保持LOOKING状态,恢复到各自得票数为1
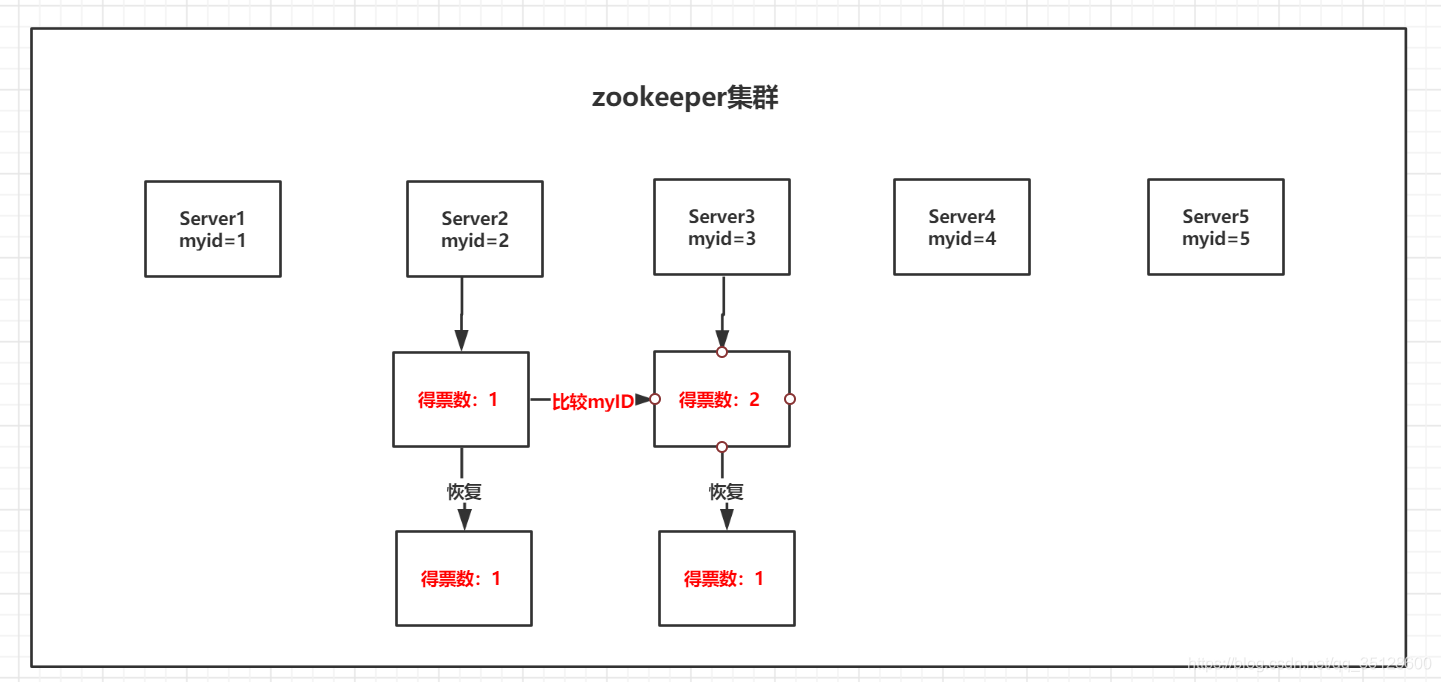
(3)再然后服务器5启动,根据前面的理论分析,服务器5先给自己投一票,然后它与最开始启动的服务器2,服务器3进行通信,互相交换自己的选举结果,因为各自得票都是1票,所以开始比较myid的值,于是server5胜出,Server2和Server3将自己的一票都投给Server5,此时Server5得票数超过半数,所以它成为了这次选举的Leader。
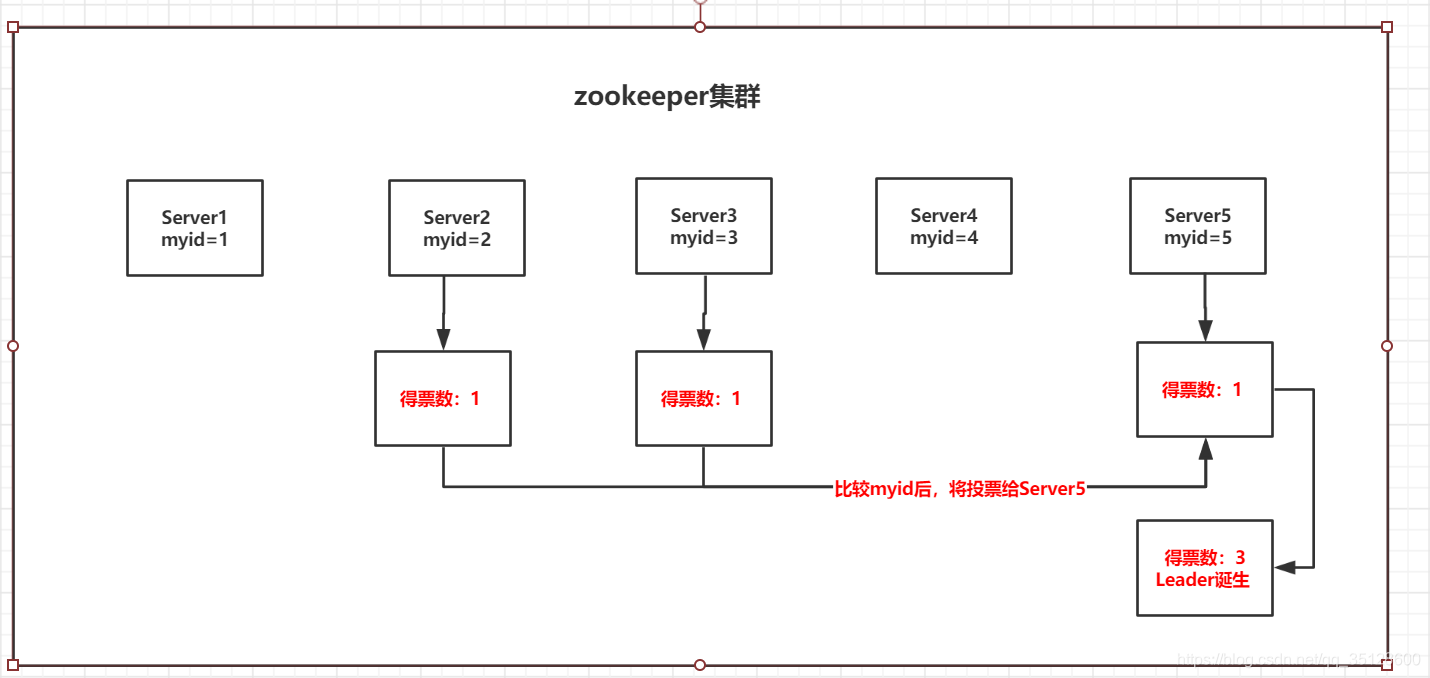
(4)此时服务器1,4启动,由于Servre5已经是Leader,所以Server1,4只能是Follower,至此选举结束
以上就是zookeeper的选举过程,有收获的小伙伴给作者点个赞吧~