第2章 机器学习概述
2.2 机器学习三要素
- 模型
- 学习准则
- 优化算法
2.2.1 损失函数
-
0-1损失函数
虽然0-1损失能够客观的评价模型的好坏,但缺点是数学性质不是很好:不连续且导数为0,难以优化。因此常用连续可微的损失函数替代。
-
平方损失函数
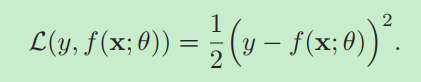
平方损失函数一般不适用于分类问题。 -
交叉熵损失函数

交叉熵损失函数是最常用的损失函数。
2.2.2 过拟合和欠拟合
-
过拟合
:
概念:
经验风险最小化原则很容易导致模型在训练集上错误率很低,但是在未知数据上错误率很高。这就是所谓的过拟合(Overfitting)
造成的原因:
往往是由于训练数据少和噪声以及模型能力强等原因造成的
解决措施:
一般在经验风险最小化的基础上再引入参数的正则化(Regularization),来限制模型能力,使其不要过度地最小化经验风险.

-
欠拟合
:
概念:
即模型不能很好地拟合训练数据,在训练集的错误率比较高。欠拟合一般是由于模型能力不足造成的
2.2.3 梯度下降
1.随机梯度下降

由于其每次只选择一个样本进行训练并更新参数,因此随机梯度下降法的一个缺点是无法充分利用计算机的并行计算能力。
2.小批量梯度下降
:
小批量梯度下降法(Mini-Batch Gradient Descent)是批量梯度下降 和随机梯度下降的折中。每次迭代时,我们随机选取一小部分训练样本来计算梯度并更新参数,这样既可以兼顾随机梯度下降法的优点,也可以提高训练效率。

2.3 最大似然估计
机器学习任务可以分为两类,一类是样本的特征向量 x 和标签 y 之间存在未知的函数关系
y
=
h
(
x
)
y = h(x)
y
=
h
(
x
)
,另一类是条件概率
p
(
y
∣
x
)
p(y|x)
p
(
y
∣
x
)
服从某个未知分布。
最大似然估计(Maximum Likelihood Estimate,MLE)是指找到一组参数w使得似然函数
p
(
y
∣
X
;
w
,
σ
)
p(y |X; w, σ)
p
(
y
∣
X
;
w
,
σ
)
最大, 等价于对数似然函数
l
o
g
p
(
y
∣
X
;
w
,
σ
)
log p(y|X; w, σ)
l
o
g
p
(
y
∣
X
;
w
,
σ
)
最大

2.4 偏差-方差分解
-
偏差
(Bias),是指一个模型的在不同训练集上的平均性能和最优模型的差异。
偏差可以用来衡量一个模型的拟合能力
; -
方差
(Variance), 是指一个模型在不同训练集上的差异,
可以用来衡量一个模型是否容易过拟合
。

上图给出了偏差和方差组合的四种情况,其中
- 图2.6a给出了一种理想情况,方差和偏差都比较小。
- 图2.6b为高偏差低方差的情况,表示模型的泛化能力很好,但拟合能力不足。
- 图2.6c为低偏差高方差的情况,表示模型的拟合能力很好,但泛化能力比较差。当训练数据比较少时会导致过拟合。
- 图2.6d为高偏差高方差的情况,是一种最差的情况
如何解决高(低)方差/偏差的问题
-
一般来说,当一个模型在训练集上的错误率比较高时,说明模型的拟合能力不够,偏差比较高。这种情况可以增加数据特征、提高模型复杂度,减少正则化系数等操作来改进模型。
-
当模型在训练集上的错误率比较低,但验证集上的错误率比较高时,说明模型过拟合,方差比较高。这种情况可以通过降低模型 复杂度,加大正则化系数,引入先验等方法来缓解。
2.5 机器学习算法分类
-
监督学习
:如果机器学习的目标是通过建模样本的特征 x 和标签 y 之间的关系:
y=
f
(
x
;
θ
)
y = f(x; θ)
y
=
f
(
x
;
θ
)
或
p(
y
∣
x
;
θ
)
p(y|x; θ)
p
(
y
∣
x
;
θ
)
,并且训练集中每个样本都有标签,那么这类机器学习称为监督学习(Supervised Learning) -
无监督学习
:无监督学习(Unsupervised Learning, UL)是指从不包含目标标签 的训练样本中自动学习到一些有价值的信息。典型的无监督学习问题有聚类、密 度估计、特征学习、降维等。 -
强化学习
:是一类通过交互来学习的机器学习算法。
2.6 数据的特征表示
2.7 P/R/F
解释一:
假设一共有10篇文章,里面4篇是你要找的。根据你某个算法,你认为其中有5篇是你要找的,但是实际上在这5篇里面,只有3篇是真正你要找的。那么你的这个算法的precision是3/5=60%,也就是,你找的这5篇,有3篇是真正对的这个算法的recall是3/4=75%,也就是,一共有用的这4篇里面,你找到了其中三篇。
解释二:
准确率(P值)
假设我此时想吃香蕉,实验室里面每天都会安排10个水果,水果种类分别是6个香蕉,3个橘子,1个菠萝。哎,但是,实验室主任搞事情啊,为了提高我们吃水果的动力与趣味,告诉我们10个水果放在黑盒子中,每个人是看不到自己拿的什么,每次拿5个出来,哎,我去抽了,抽出了2个香蕉,2个橘子,1个菠萝。
下面我们来分别求求P值,R值,F值!
按照一开始说的,精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。这里我们的正样本就是我想吃的香蕉!
在预测结果中,有2个香蕉,总个数是我拿的5个,那么P值计算如下:
P
=
2
/
5
P = 2 / 5
P
=
2
/
5
召回率(R值)
按照开始总结所说。
召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。我们这里的正类是我想吃的香蕉,而在样本中的香蕉个数是6个,召回率的召回也可以这么理解,代表了,原始样本中正类召回了多少。R值计算如下:
R
=
2
/
6
R = 2 / 6
R
=
2
/
6
分母已经变成了样本中香蕉的个数啦
F值
可能很多人就会问了,有了召回率和准确率这俩个评价指标后,不就非常好了,为什么要有F值这个评价量的存在呢?按照高中语文老师所说的,存在即合理的说法,既然F值存在了,那么一定有它存在的必要性,我们在评价的时候,当然是希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,在我们这个例子中,我们只搜索出了一个结果,且是香蕉,那么Precision就是100%,但是Recall为1/6就很低;而如果我们抽取10个水果,那么比如Recall是100%,但是Precision为6/10,相对来说就会比较低。因此P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure,通过计算F值来评价一个指标!
我这里给出最常见的F1计算方法,如下:
F
1
=
(
2
∗
P
∗
R
)
/
(
P
+
R
)
F1 = (2*P*R)/(P+R)
F
1
=
(
2
∗
P
∗
R
)
/
(
P
+
R
)
F那么在我们这个例子中
F
1
=
(
2
∗
2
/
5
∗
2
/
6
)
/
(
2
/
5
+
2
/
6
)
F1 = (2*2/5*2/6)/(2/5+2/6)
F
1
=
(
2
∗
2
/
5
∗
2
/
6
)
/
(
2
/
5
+
2
/
6
)
解释三:
假设我们手上有60个正样本,40个负样本,我们要找出所有的正样本,系统查找出50个,其中只有40个是真正的正样本,计算上述各指标。
TP: 将正类预测为正类数 40
FN: 将正类预测为负类数 20
FP: 将负类预测为正类数 10
TN: 将负类预测为负类数 30
准确率(accuracy) = 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN) = 70%
精确率(precision) = TP/(TP+FP) = 80%
召回率(recall) = TP/(TP+FN) = 2/3
第3章 线性回归
3.2 Logistic回归
激活函数
(Activation Function),其作用是把线性函数的值域 从实数区间“挤压”到了(0, 1)之间,可以用来表示概率。
Logistic 回归采用交叉熵作为损失函数,并使用梯度下降法来对参数进行优化。
风险函数:

参数更新
:
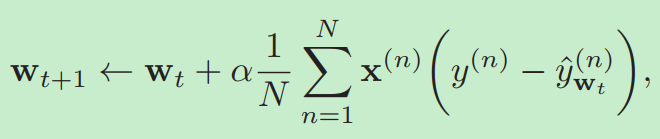
3.6 损失函数的对比
https://blog.csdn.net/lwc5411117/article/details/84885427
梯度下降算法
https://www.jianshu.com/p/88fa33750d3a
-
什么是梯度:
首先我们来认识一下什么叫做梯度。在微积分中,对多元函数的参数求偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。如f(x,y),其梯度向量就是
(∂
f
∂
x
,
∂
f
∂
y
)
T
(\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y}) T
(
∂
x
∂
f
,
∂
y
∂
f
)
T
。简称 grad f(x,y)。
梯度向量的几何意义
,就是代表了函数变化最快的方向。这里可以这样理解,一个函数在某一个方向上的方向向量为 grad*cos∂,于是梯度就代表了其变化最快的方向。即沿着梯度向量的方向,就是函数增加最快的方向,更容易找到函数的最大值。这是整个梯度下降法的基本思想。 -
梯度下降与梯度上升
在机器学习中,我们需要对损失函数求最小化,这时候我们通过梯度下降法来一步步迭代求解。同样的,做一个变化可以反过来求解损失函数 -f(θ) 的最大值,这时候就转化为了梯度上升法。简单来说,就是上山和下山的关系。
梯度下降函数的对比
几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
- Batch gradient descent(BGD)的优点是理想状态下经过足够多的迭代后可以达到全局最优。但是缺点也很明显,就是如果你的数据集非常的大(现在很常见),根本没法全部塞到内存(显存)里,所以BGD对于小样本还行,大数据集就没法娱乐了。而且因为每次迭代都要计算全部的样本,所以对于大数据量会非常的慢。
- SGD也有缺点,因为每次只用一个样本来更新参数,会导致不稳定性大些(可以看下图(图片来自ng deep learning 课),每次更新的方向,不想batch gradient descent那样每次都朝着最优点的方向逼近,会在最优点附近震荡)。因为每次训练的都是随机的一个样本,会导致导致梯度的方向不会像BGD那样朝着最优点
- mini-batch gradient descent 相对SGD在下降的时候,相对平滑些(相对稳定),不像SGD那样震荡的比较厉害。mini-batch gradient descent的一个缺点是增加了一个超参数 batch_sizebatch_size ,要去调这个超参数。最大的一个优点湿可以利用GPU加速训练。
第四章 前馈神经网络
4.1 神经元
4.1.1 激活函数
https://www.jianshu.com/p/22d9720dbf1a(常用激活函数总结和对比)
为什么要使用激活函数
:
如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。所谓激活函数,就是在神经网络的神经元上运行的函数,
负责将神经元的输入映射到输出端
。常见的激活函数包括上面列出的Sigmoid、tanh、ReLu、 softplus以及softmax函数(激活函数Softmax,它只会被用在网络中的最后一层,用来进行最后的分类和归一化)

-
Logistic(也叫做Sigmoid函数)
缺点:
激活函数计算量大,反向传播求误差梯度时,求导涉及除法反向传播时,很容易就会出现
梯度消失
的情况,从而无法完成深层网络的训练。-
Logistic函数为什么会出现梯度消失

由图可知,导数从 0 开始很快就又趋近于 0 了,易造成“梯度消失”现象
-
-
Tanh函数
也称为双切正切函数
取值范围为[-1,1]。tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。与 sigmoid 的区别是,tanh 是 0 均值的,因此实际应用中 tanh 会比 sigmoid 更好。 -
ReLU函数
-
ReLU 的优点:
Krizhevsky et al. 发现使用 ReLU 得到的 SGD 的收敛速度会比 sigmoid/tanh 快很多 -
ReLU 的缺点:
训练的时候很”脆弱”,很容易就”die”了。
-
ReLU 的优点:
4.4 反向传播算法
反向传播算法的含义是:第
l
l
l
层的一个神经元的误差项(或敏感性)是所有与该神经元相连的第
l
+
1
l+1
l
+
1
层的神经元的误差项的权重和。然后,再乘上该神经元激活函数的梯度。

深度学习的优化方案(optimizer)
常用的optimizer
:
- BGD(Batch Gradient Descent),SGD(Stochastic Gradient Descent),MBGD(Mini-Batch Gradient Descent),
- Momentum & Nesterov Momentum
- AdaGrad & Adadelta
- RMSProp
- Adam
- first-order optimization & second- order optimization & L-BFGS
第五章 卷积神经网络
5.2 卷积神经网络
5.2.1 卷积层代替全连接层
局部链接
权重共享
5.2.2 卷积层
卷积层的作用是提取一个局部区域的特征,不同的卷积核相当于不同的特征提取器。
5.2.3 池化层(汇聚层)
上采样
:
下采样
: