一、性能测试概述
软件性能:
系统的性能是个很大的概念,覆盖面非常广泛,对一个软件系统而言,包括执行效率、资源占用、稳定性、安全性、兼容性、可扩展性、可靠性等等。
性能测试:
性能测试主要是通过自动化工具模拟多种正常、峰值以及异常负载条件对系统进行操作,以获得系统各项性能指标的一种测试。即对被测试系统按照一定策略施加压力,获取系统响应时间、TPS、吞吐量、资源利用率等性能指标,以期保证系统的性能。
性能测试重要性:
随着公司业务发展越来越快,原有的服务体系已不能满足现在的业务需求,渐渐地暴露出了线上性能不足的问题,所以为了满足用户需求,亟需提升服务整体性能。
性能问题会严重影响用户体验,很多线上用户反馈卡顿等性能问题,性能测试以后会被公司越来越重视。
性能测试涉及面较广,要求性能测试者具备的能力很全面,也是将来发展的趋势,在这里我希望各位都能了解一下。
性能测试概述:
1、为什么进行性能测试
评估系统
系统调优
验证稳定
2、性能测试的目标
寻找瓶颈
性能优化
预测未来
性能测试类型:
1、基本类型
负载测试
压力测试
大数据量测试
疲劳强度测试
失效恢复测试
2、实战类型
单交易基准测试
单交易负载测试
混合交易测试
稳定性测试
高可用性测试
异常测试
批量程序测试
流控超时测试
参数调优测试
……
性能测试指标:
RepsonseTime – RT
:响应时间,用户从客户端发起一个请求开始计算,到客户端接收到服务端的响应结束,整个过程所耗费的时间。
Hits Per Second – HPS
:用户每秒点击次数,也就是每秒向后台发送的请求次数
QPS
:系统每秒内处理查询的次数。
MaxRT
:最大响应时间,指用户发出请求到服务端返回响应的最大时间。
MiniRT
:最少响应时间,指用户发出请求到服务端返回响应的最少时间。
90%响应时间
:将所有用户的响应时间进行升序排序,取 90 % 的位置。
吞吐量
:每秒钟系统能处理的请求数/任务数。在测试中,我们往往会比较注重系统接口的QPS/TPS,因为QPS/TPS体现了接口的性能,QPS/TPS越大,性能越好。
响应时间
:服务处理一个请求或一个任务的耗时。
错误率
:一批请求中结果出过错的请求所占比例。
二、性能测试的步骤:
1、前期准备
性能测试虽然是核心功能稳定后才开始压测,但是在需求阶段就应该参与,这样可以深入了解系统业务、重要功能的业务逻辑,为后续做准备。
准备的内容:
测试策略(方案)
2、性能需求分析(评审)
明确性能测试范围、目标。
关注点:
测试范围、目标的合理性:
推荐方式:引导产品、需求或者开发出压测目标(分别是单场景、混合场景、稳定性场景的),自己给建议,大家一起确定一个当前合理的目标。
定性能指标:
定性能指标,分为迭代项目和新项目,迭代项目就根据生产监控、日志分析来评估指标,这里需要做容量规划,新项目单独评估。
3、熟悉系统架构
1、做性能测试,必须要熟悉项目的架构,这样你才知道监控哪些服务器,以及准备监控方案(监控方式及监控的性能指标点);
2、包含具体用到的web服务器、应用服务器、缓存数据库服务器、数据库服务器、文件服务器等;
3、主流的技术栈:nginx、dubbo、mysql、redis、jvm等等
4、制定性能测试方案
项目背景及架构分析,
需要的资源,
技术策略(比如压测、监控、分析工具选择等),
场景设计,
计划什么时候做什么事等等。
5、搭建测试环境,准备测试数据
1、搭建测试环境是测试必备的技能,当然,如有困难,你也可以找运维、开发一起配合;
2、测试数据分为基础环境数据和业务数据;
3、基础环境数据可以从功能测试的库导过来,改一些配置即可;
4、业务数据包含:存量数据+容量规划数据,比如一个查询接口,都是并发100用户,对应的表数据量是1万和100万,压测结果是不一样的;
5、数据量要参考生产环境,如果是新项目,除了空库压,最好也做一下存量数据压。
6、压测脚本开发
主流程稳定后,调试被测接口、开发压测脚本(也可以在功能测试环境进行);
客户端并发工具,推荐用Locust,主流、开源、轻量、免费、功能强大;
根据实际情况,对脚本调整,比如:参数化、关联、事务、检查点、思考时间、信息头管理器等;
7、预压测(基准测试)
少量并发(比如1个用户),压测10分钟,
第一:可以看压测环境功能是否通;
第二:估算并发过程中需要多少参数化数据的数据量;
8、执行压测并监控
场景设计好后,就可以执行压测了,然后监控查看测试各项指标是否满足需求;如果不满足,可以结合表象及根据自己的经验直接去看预估的瓶颈点;
否则,从请求开始,一步一步排查请求流经的节点,包括服务器资源(cpu、内存、磁盘io、网络)是否存在性能瓶颈、是否存在队列、线程池、连接池、线程死锁、数据库死锁、慢sql、长事务等性能问题;
用什么工具监控?我大部分都是用的命令,为了方便,也会写shell脚本来监控;
linux服务器,常用的命令是top、vmstat、free、df、sar、iostat、netstat等,一般是多个命令配合着用;
java应用:jvisualvm、jconsole、jmap、jstat、jstack等,以及自己写的一些shell脚本; redis、mysql、jvm等等。
9、分析定位
基于上一步的监控数据,对瓶颈进行分析、定位,模块隔离分析、日志分析、内存分析、线程栈分析、代码跟踪等等;
这个真需要实战积累,没有捷径!
10、性能优化
定位到问题了,大部分情况下,优化方案也就有了,测试可以把自己建议的优化方案告诉开发,开发会结合自己的方案,一起做优化方案评估;
如果测试没有优化方案,那就把问题反馈给开发吧,但是也好好学学开发的优化思路,这就是成长的过程。
11、性能回归
开发优化后,复测。
12、编写性能报告
测试结果是多少?
测试是否通过?
发现了什么性能问题?
原因是什么?
如何优化解决的?
系统性能提升了多少倍?
优化方案务必写详细,以便上线同事知道,把优化同步到其它各个环境。
三、经典案例:
性能测试要求有很强的基本功和知识面,很考察一个人的功底。
现象1:
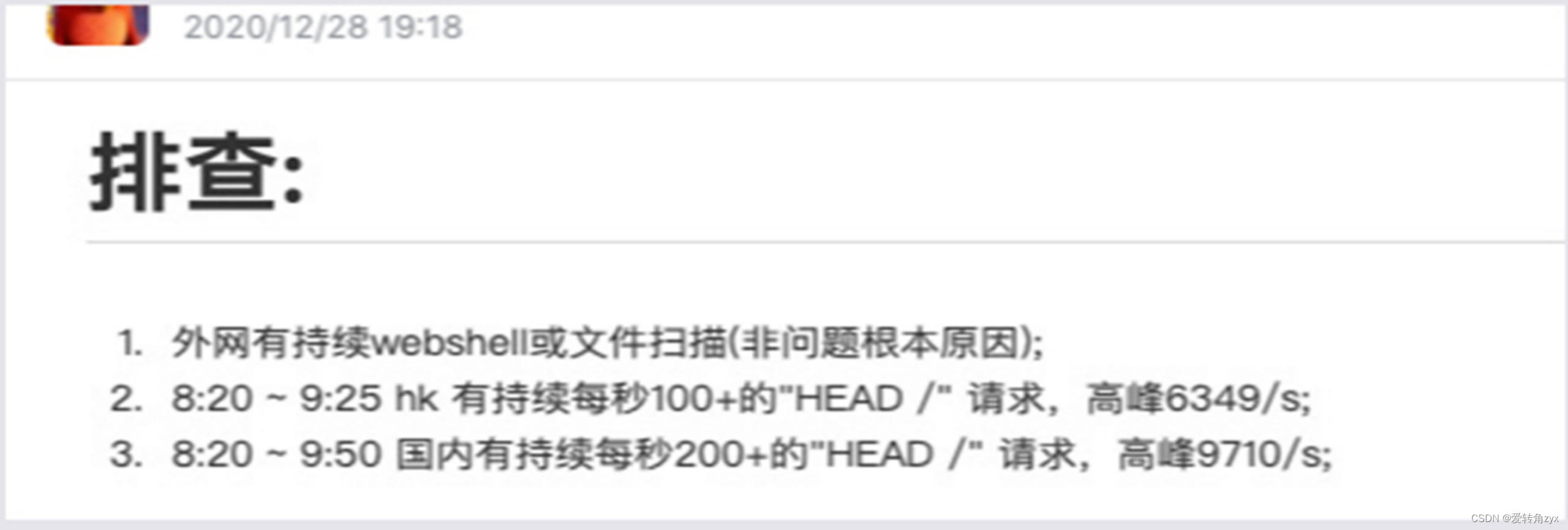
现象2:
排查思路:
1、通过压测来模拟犯罪现场。
2、通过线上问题现象来深入分析。
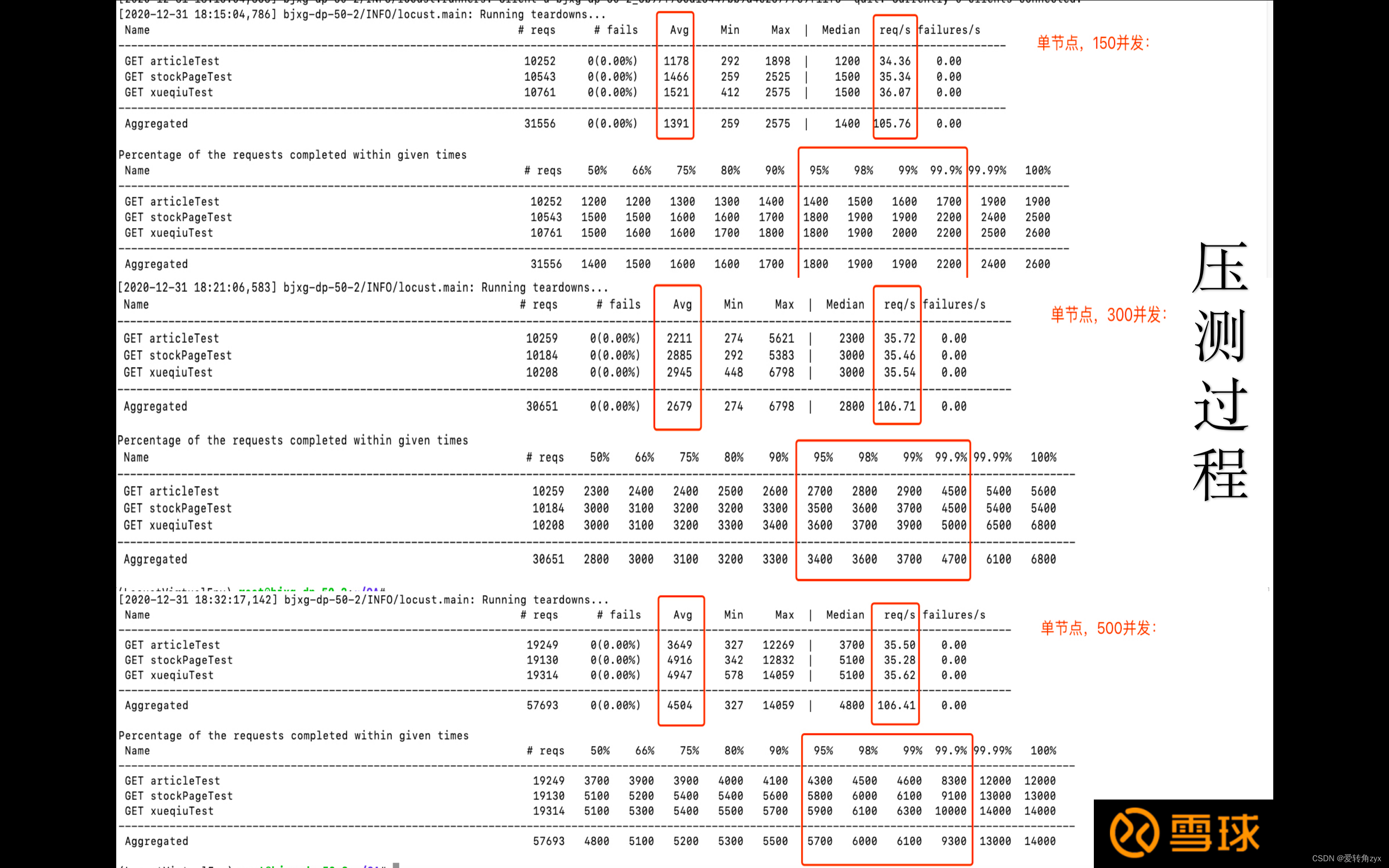
压测过程:
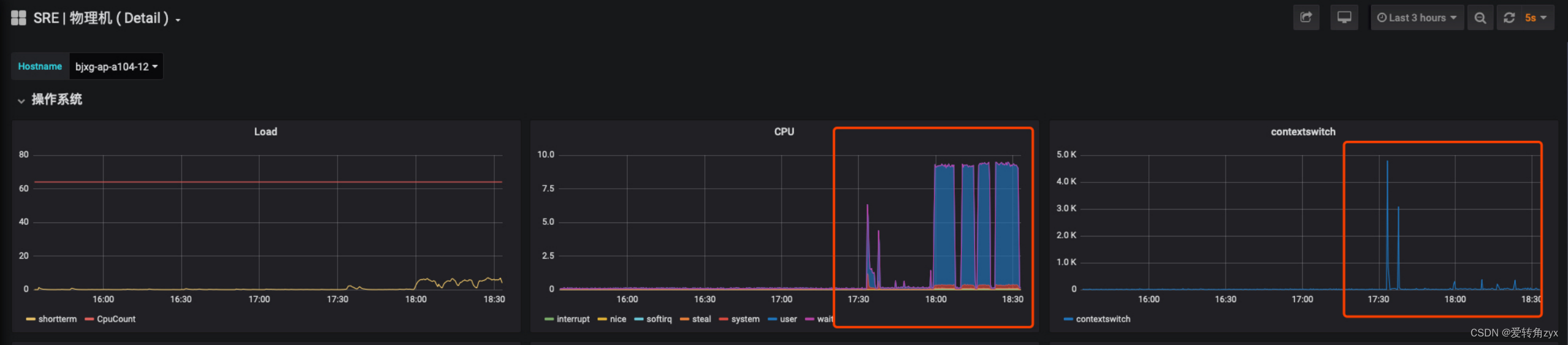
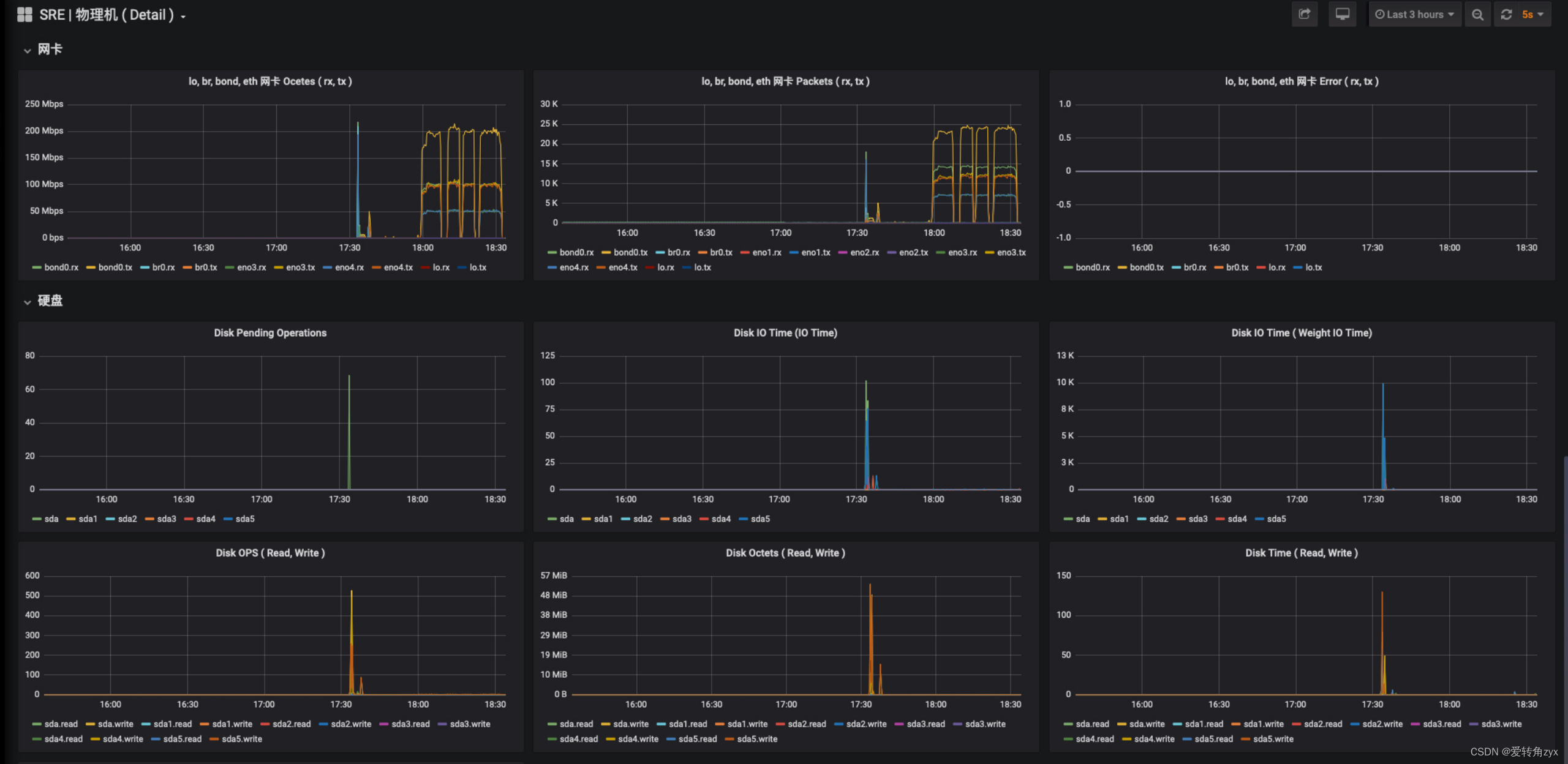
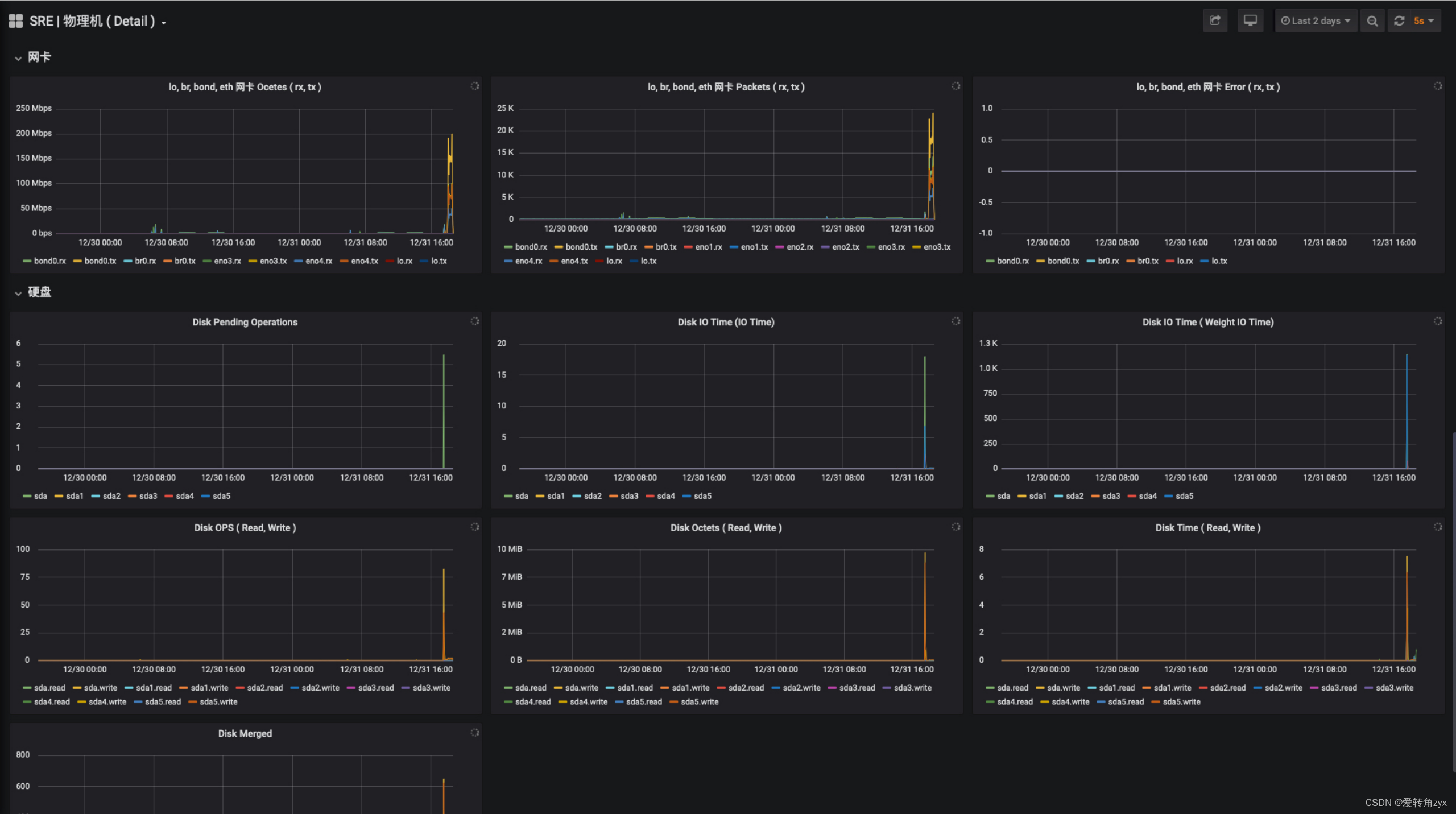

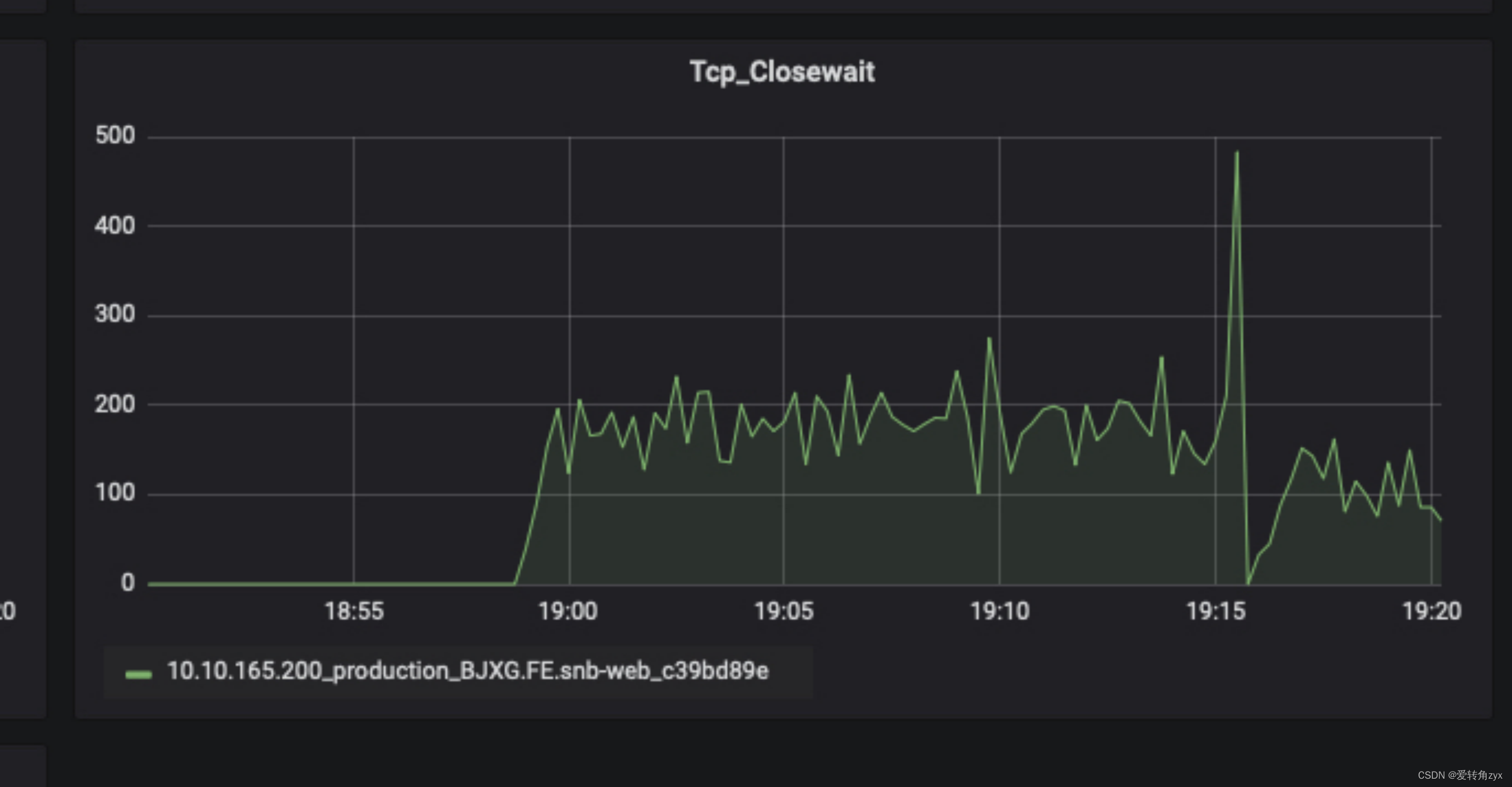
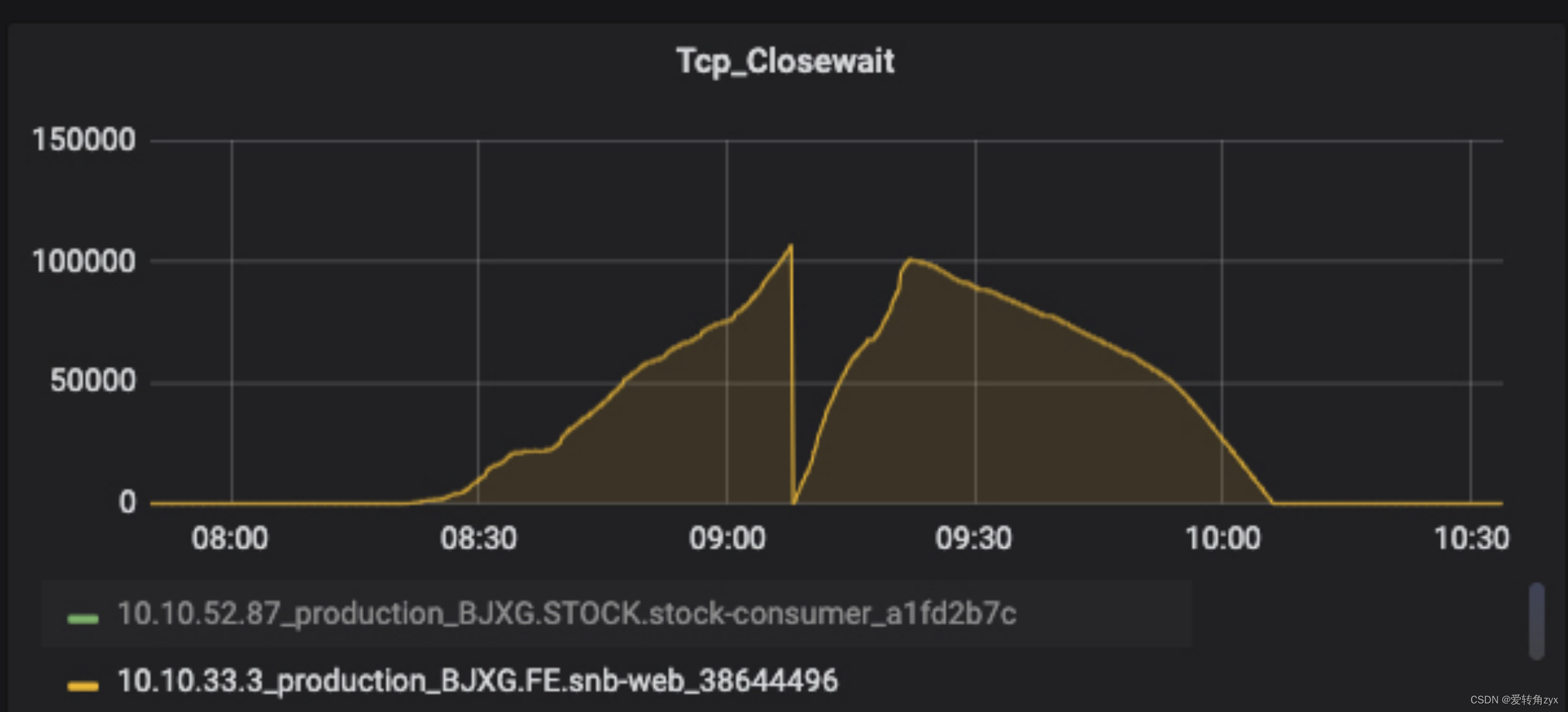
通过线上问题现象来深入分析:
通过线上问题现象二,我们看到close_wait数非常大,已经达到了10万多个,造成这种现象的原因,我在这里详细说一下:
这里需要你知道socket通信的知识,即三次握手,四次挥手的具体通信流程。

那到底什么原因会造成close_wait增多呢?
直接原因:
服务端的第二个FIN报文一直没有给客户端发,而客户端httpClient一般都有请求超时时间,默认是5s,超时之后就会抛出异常,关闭连接,关闭连接导致客户端发送了FIN报文,服务端收到后会返回ACK报文,但是由于服务端处理请求的线程还处于阻塞的状态,所以服务端当前的连接状态是close_wait状态,这个过程就一直这样循环下去,导致服务端的close_wait会不断增多。
间接原因:那什么原因造成服务端阻塞呢?
答:
1、服务端线程池问题
线程池设置不合理,设置的过低造成排队阻塞现象;这里就用到线程池的知识了,线程池设置一般根据服务器的CPU核数来设定,一般线程池的大小设置成为CPU的核数。
2、服务端连接池问题
比如你的数据库连接池设置的过小,每来一个请求就创建一个连接,特别是高并发下,很快就会把连接池打满了,连接池被打满了,即没有可用的连接了,后面来的请求就会一直阻塞,客户端的请求就会一直等待,造成客户端等待超时,主动关闭连接并发送FIN报文…这样恶性循环下去,服务端的close_wait会越来越多。
3、资源释放问题
服务端没有释放资源,比如数据库连接池打满,每个线程处理完没有释放资源,造成线程阻塞。
4、锁或同步代码块问题
高并发下同步代码块中使用了重量级锁,没有使用轻量级锁或自旋,或者由于同步代码块逻辑比较重,出现了死锁,这样同步代码块就会一直阻塞下去。
以上几种情况,在高并发下,服务端资源使用不当或消耗殆尽,很容易被打挂,造成死锁、服务hang住,对新来的请求不再处理了,也处理不过来了,造成迟迟不会主动给客户端发送第二个FIN报文,最终造成服务端close_wait数目越来越多。
思考:
假设我们的服务遭到别人恶意攻击了,那我们该怎么做才能使服务能抗住这些攻击而不让服务挂掉呢?
我的回答是:打铁还需自身硬,无须扬鞭自奋蹄~
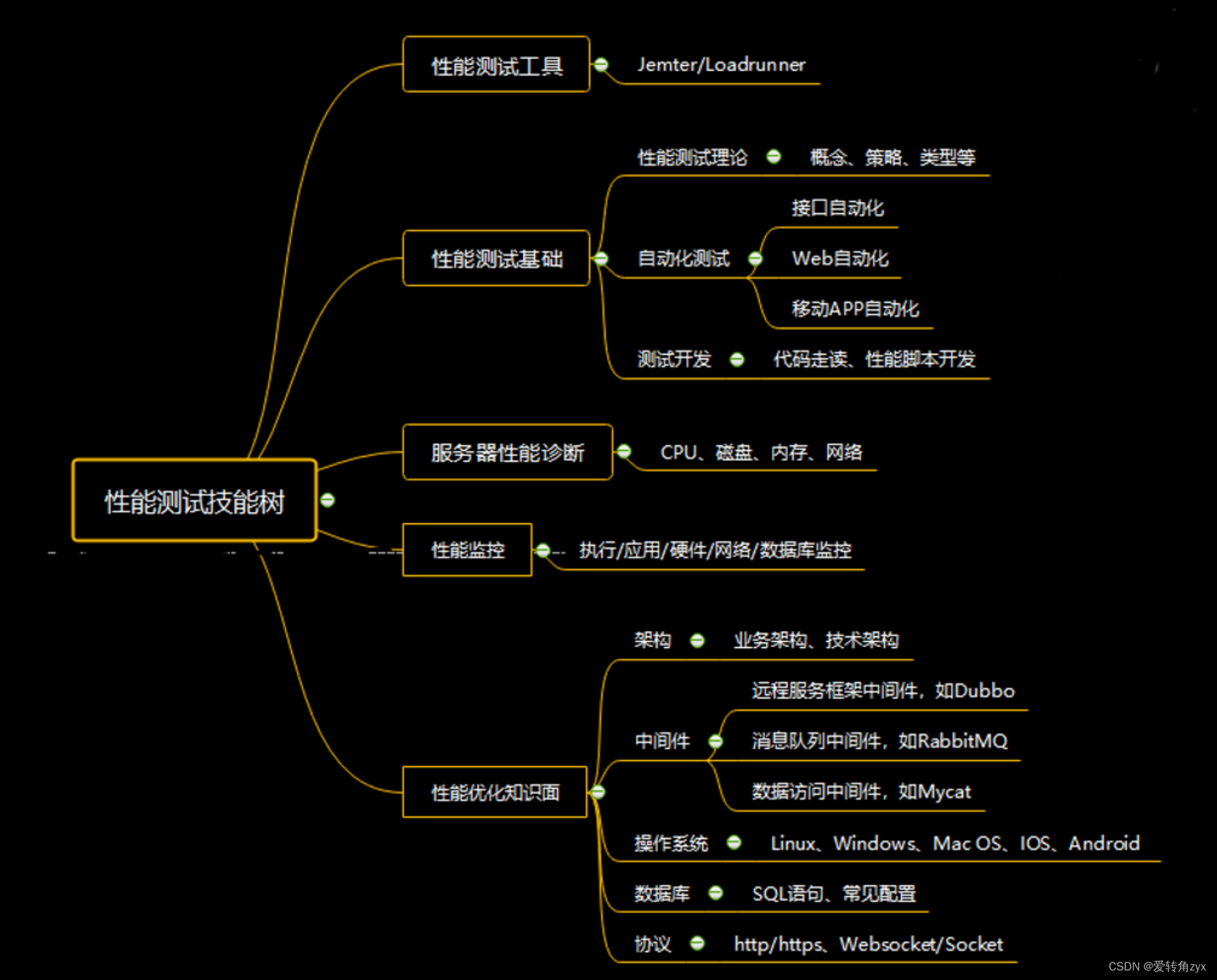
最后附上性能测试技能树: