实验环境
Ubuntu18.04.1,linux内核:5.6.3,VMware15,gcc编译器,内存:3G,CPU:4×2=8核,外存:100G。
Ubuntu18.04.1.iso镜像网盘下载地址:
链接:
https://pan.baidu.com/s/1CYVD-2ZlU2lfYD5bisBIvA
提取码:1ork
设计目的
Linux 是开源操作系统,用户可以根据自身系统需要裁剪、修改内核,定制出功能更加
合适、运行效率更高的系统,因此,编译 Linux 内核是进行内核开发的必要基本功。
在系统中根据需要添加新的系统调用是修改内核的一种常用手段,通过本次实验,读
者应理解 Linux 系统处理系统调用的流程以及增加系统调用的方法。
内容要求
1、添加一个系统调用,实现对指定进程的 nice 值的修改或读取功能,并返回进程最
新的 nice 值及优先级 prio。建议调用原型为:
int mysetnice(pid_t pid, int flag, int nicevalue,void __user * prio, void __user * nice);
参数含义:
- pid:进程 ID。
- flag:若值为 0,表示读取 nice 值;若值为 1,表示修改 nice 值。
- nicevalue:为指定进程设置的新 nice 值。
- prio、nice:指向进程当前优先级 prio 及 nice 值。
- 返回值:系统调用成功时返回 0,失败时返回错误码 EFAULT。
2、写一个简单的应用程序测试1、中添加的系统调用。
3、若程序中调用了 Linux 的内核函数,要求深入阅读相关函数源码。
nice与prio的关系
Linux 系统调用基本概念
系统调用的实质是调用内核函数,于内核态中运行。Linux 系统中用户(或封装例程)通过执行一条访管指令“int $0x80”来调用系统调用,该指令会产生一个访管中断,从而让系统暂停当前进程的执行,而转去执行系统调用处理程序,通过用户态传入的系统调用号从系统调用表中找到相应服务例程的入口并执行,完成后返回。
1、系统调用号与系统调用表
Linux 系统提供了多达几百种的系统调用,为了唯一的标识每一个系统调用,Linux 为每个系统调用都设置了一个唯一的编号,称为系统调用号;同时每个系统调用需要一个服务例程完成其具体功能。Linux 内核中设置了一张系统调用表,用于关联系统调用号及其相对应的服务例程入口地址,定义在./arch/x86/entry/syscalls/syscall_64.tbl 文件中(32 位系统是 syscall_32.tbl),每个系统调用占一表项,比如大家比较熟悉的几个系统调用的调用号如表所示:
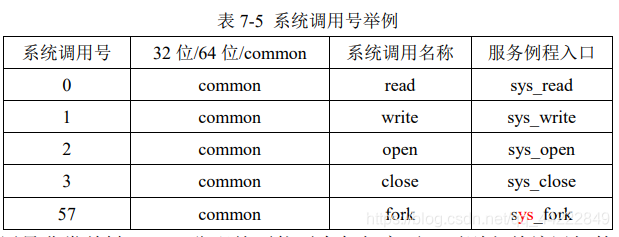
系统调用号非常关键,一旦分配就不能再有任何变更,否则之前编译好的应用程序就会崩溃。在 x86 中,系统调用号是通过 eax 寄存器传递给内核的。在陷人内核之前,先将系统调用号存入eax 中,这样系统调用处理程序一旦运行,就可以从 eax 中得到调用号。
2、系统调用服务例程
每个系统调用都对应一个内核服务例程来实现该系统调用的具体功能,其命名格式都是以“sys_”开头,如 sys_read 等,其代码实现通常存放在./kernel/sys.c 文件中。服务例程的原型声明则是在./include/linux/syscalls.h 中,通常都有固定的格式,如 sys_open 的原型为:asmlinkage long sys_open(const char __user *filename,int flags, int mode);
其中“asmlinkage”是一个必须的限定词,用于通知编译器仅从堆栈中提取该函数的参
数,而不是从寄存器中,因为在执行服务例程之前系统已经将通过寄存器传递过来的参数
值压入内核堆栈了。在新版本的内核中,引入了宏“SYSCALL_DEFINEN(sname)”对服务例程
原型进行封装,其中的“N”是该系统调用所需要参数的个数,如上述 sys_open 调用
在./kernel/sys.c 文件中的实现格式为:
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, int, mode)
3、系统调用参数传递
与普通函数一样,系统调用通常也需要输入/输出参数。在 x86 上,Linux 通过 6 个寄存器来传入参数值,其中 eax 传递系统调用号,后面 5 个寄存器 ebx, ecx, edx, esi 和 edi 按照顺序存放前五个参数,需要六个或六个以上参数的情况不多见,此时,应该用一个单独的寄存器存放指向所有这些参数在用户空间地址的指针。服务例程的返回值通过 eax 寄存器传递,这是在执行 rutern 指令时由 C 编译器自动完成的。
当系统调用执行成功时,将返回服务例程的返回值,通常是 0。但如果执行失败,为防止和正常的返回值混淆,系统调用并不直接返回错误码,而是将错误码放入一个名为 errno的全局变量中,通常是一个负值,通过调用 perror()库函数,可以把 errno 翻译成用户可以理解的错误信息描述。
4.、系统调用参数验证
系统调用必须仔细检查用户传入的参数是否合法有效,比如与进程相关的调用必须检查用户提供的 PID 等是否有效。最重要的是要检查用户提供的指针是否有效,以防止用户进程非法访问数据。内核提供了两个函数来完成必须的检查以及内核空间与用户空间之间数据的来回拷贝:
copy_to_user()和 copy_from_user(),对 2.6.24 内核,在/include/asm-x86/uaccess_64.h 文件中
申 明 原型 , 在 ./arch/x86/lib/usercopy_32.c 文 件 中实 现 函数 ; 对于 内核 4.12 ,定 义 在./include/linux/uaccess.h 文件中。
下载内核源码
linux内核:5.6.3获取:
-
百度网盘下载
链接:
https://pan.baidu.com/s/1nQV6jmwoMkCUy51EFgtVPw
提取码:fo1u -
CSDN下载地址
linux-5.6.3
-
官网下载,Linux 的内核源代码是完全公开的
https://www.kernel.org/ -
特别提醒:
我是在Windows上下载好的,然后通过SSH上传到了Linux的用户指定的Downloads目录下。
如果,不知道SSH上传,可看我之前的博客(当然也可以通过Ubuntu自带的浏览器,官网下载):
Xshell 连接 Ubuntu 教程(超详细),并解决二个常见问题(一直连不上、root用户拒绝密码)
解压下载好的linux5.6.3内核
首先切换到 root 用户(后面所有操作都必须以 root 用户进行),将下载的新内核压缩文
件复制到/home 或其他比较空闲的目录中,然后进入压缩文件所在子目录,分两步解压缩:
(1)xz -d linux-5.6.3.tar.xz,大概执行 1 分钟左右,中间没有任何信息显示。
(2)tar –xvf linux-5.6.3.tar
下图,是我解压缩好的文件,
以后操作都是以root身份进入linux-5.6.3文件进行操作
。

注意:由于编译过程中会生成很多临时文件,所以要确保压缩文件所在子目录有足够的
空闲空间,最好能有 15-20GB。笔者在建立虚拟机时预留了 100GB 磁盘空间。
Linux 添加系统调用的步骤:
注意:必须以 root身份才能完成下述操作。进入解压后的linux-5.6.3文件中
1、分配系统调用号,修改系统调用表
vim ./arch/x86/entry/syscalls/syscall_64.tbl
下图,是我添加的439调用号,64和common不用深究,调用号,在末尾累加。

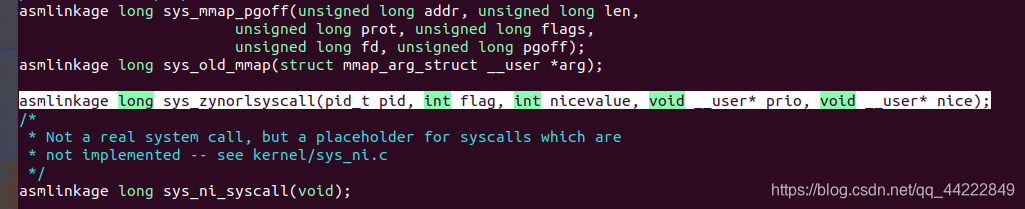
2、 申明系统调用服务例程原型
Linux 系统调用服务例程的原型声明在文件 linux-5.6.3/include/linux/syscalls.h 中,可在
文件末尾添加如图 :
vim ./include/linux/syscalls.h
asmlinkage long sys_zynorlsyscall(pid_t pid, int flag, int nicevalue, void __user* prio, void __user* nice);
3.实现系统调用服务例程
下面为新调用 zynorlsyscall 编写服务例程 sys_zynorlsyscall,通常添加在 sys.c 文件中(我放到了尾端,用快捷键:shift+g),其完整路径为:linux-5.6.3/kernel/sys.c:
注意:SYSCALL_DEFINE5字段中的5不要随意更该。它代表该函数除了zynorlsyscall外有5个参数
vim ./kernel/sys.c
SYSCALL_DEFINE5(zynorlsyscall, pid_t, pid, int, flag, int, nicevalue, void __user *, prio, void __user *, nice)
{
int cur_prio, cur_nice;
struct pid *ppid;
struct task_struct *pcb;
ppid = find_get_pid(pid);
pcb = pid_task(ppid, PIDTYPE_PID);
if (flag == 1)
{
set_user_nice(pcb, nicevalue);
}
else if (flag != 0)
{
return EFAULT;
}
cur_prio = task_prio(pcb);
cur_nice = task_nice(pcb);
copy_to_user(prio, &cur_prio, sizeof(cur_prio));
copy_to_user(nice, &cur_nice, sizeof(cur_nice));
return 0;
}
重新编译内核
上面三个步骤已经完成添加一个新系统调用的所有工作,但是要让这个系统调用真正
在内核中运行起来,还需要重新编译内核。
作为自由软件,Linux 内核版本不断更新,新内核会修订旧内核的 bug,并增加若干新
特性,如支持更多的硬件、具备更好的系统管理能力、运行速度更快、更稳定等。用户若
想使用这些新特性。而我们是想添加新的系统调用,需要编译内核。
1、预先安装一些辅助工具包,如果没有编译过程中会出错:
apt-get install libncurses5-dev
apt-get install libssl-dev
apt-get install bison
apt-get install flex
apt-get install pkg-config
2、清除残留的.config 和.o 文件
在开始完全重新编译之前,需要清除残留的.config 和.o 文件,后续如果编译过程中出
现错误,再次开始完全重新编译之前也需要如此清理。方法是进入 linux-5.6.3 子目录,
执行以下命令:
#make mrproper
3、 配置内核
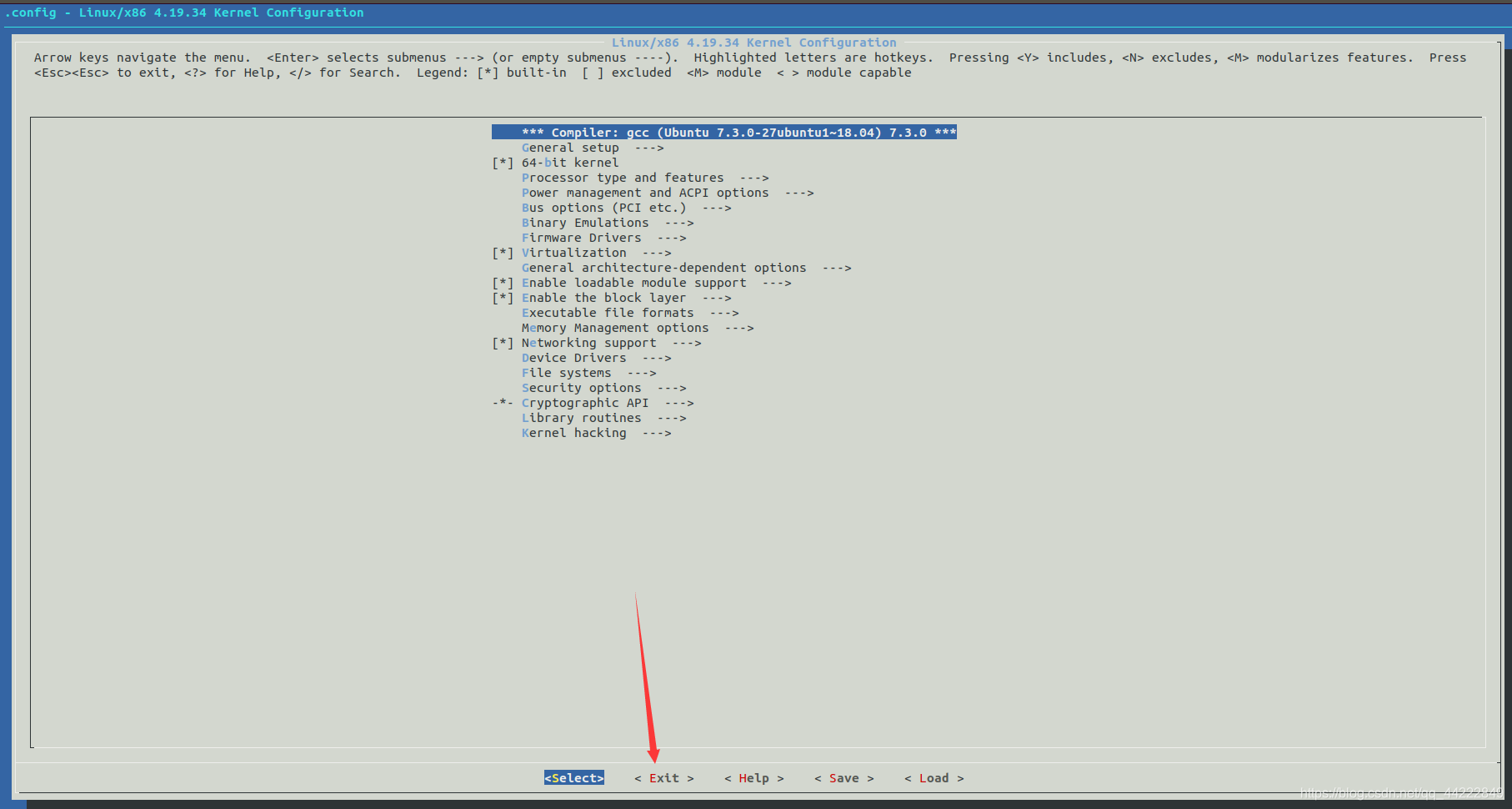
make menuconfig
此命令将打开如图 所示配置对话框,对于每一个配置选项,用户可以回答”y”、“m”或”n”:中”y”表示将相应特性的支持或设备驱动程序编译进内核;”m”表示将相应特性的支持或设备驱动程序编译成可加载模块,在需要时,可由系统或用户自行加入到内核中去;”n”表示内核不提供相特性或驱动程序的支持。一般采用默认值即可:选择保存配置信息,文件名采用默认的.config,然后选择退出。
4、 编译内核,生成启动映像文件
内核配置完成后,执行 make 命令开始编译内核,如果编译成功,则生成 Linux 启动映
像文件 bzImage(位于./arch/x86_64/boot/bzImage):
make
可使用 make -j2(双核 CPU)或 make -j4(4 核 CPU)来加快编译速度。编译过程中,可能会出现一些错误,通常都是因为缺少某个库,一般根据相应的错误提示,安装相应的包即可,然后重新编译。
我的虚拟机是8核的,所以我用1如下命令:
make -j8
我大约用了不到20分钟,如果你是一核的,用make去编译,会花费几个小时。
5、 编译模块
make modules -j8
第一次编译模块需要时间比较长,但没有make长,我用了不到10分钟。(同样-j8会加快速度)
6、安装内核
安装模块:make modules_install
安装内核:make install
7、配置 grub 引导程序
update-grub2
该命令会自动修改 grub
8、重启系统
reboot
9、将使用新内核启动 linux。启动完成后进入终端查看内核版本,如图 :
uname -a

编写用户态程序测试新系统调用
1、编写测试C程序验证上述添加的系统调用:
#include <unistd.h>
#include <sys/syscall.h>
#include <stdio.h>
#define _SYSCALL_MYSETNICE_ 439
#define EFALUT 14
int main()
{
int pid, flag, nicevalue;
int prev_prio, prev_nice, cur_prio, cur_nice;
int result;
printf("Please input flag:\n");
scanf("%d", &flag);
if (flag == 1)
{
printf("Please input variable(pid, nicevalue):\n ");
scanf("%d\n%d", &pid, &nicevalue);
syscall(_SYSCALL_MYSETNICE_, pid, 1, nicevalue, &cur_prio, &cur_nice);
printf("Current priority is : [%d], current nice is [%d]\n", cur_prio,
cur_nice);
}
else if (flag == 0)
{
printf("Please input pid:\n ");
scanf("%d", &pid);
result = syscall(_SYSCALL_MYSETNICE_, pid, 0, nicevalue, &prev_prio, &prev_nice);
if (result == EFALUT)
{
printf("ERROR!");
return 1;
}else{
printf("Current priority is : [%d], current nice is [%d]\n", prev_prio,
prev_nice);
}
}
return 0;
}
2、编译程序
gcc -o zynorlsyscall zynorlsyscall.c
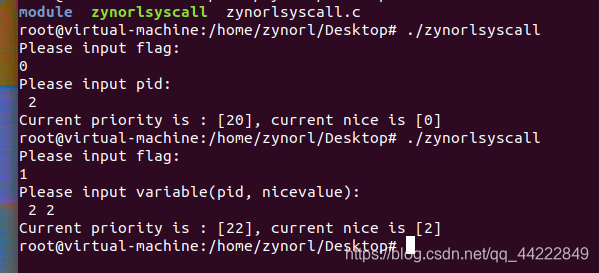
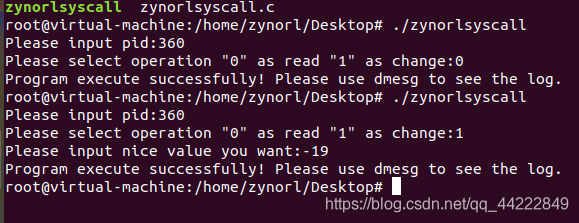
3、执行程序
:
./zynorlsyscall
4、程序说明:
syscall(439,a,b,c);
函数 syscall()宏调用新添加的系统调用,它是 Linux 提供给用户态程序直接调用系统调用的一种方法,其格式为:int syscall(int number, …);其中 number 是系统调用号,number 后面应顺序接上该系统调用的所有参数。
5、执行用户态程序,使用top指令随意找一个进程
top
如图:
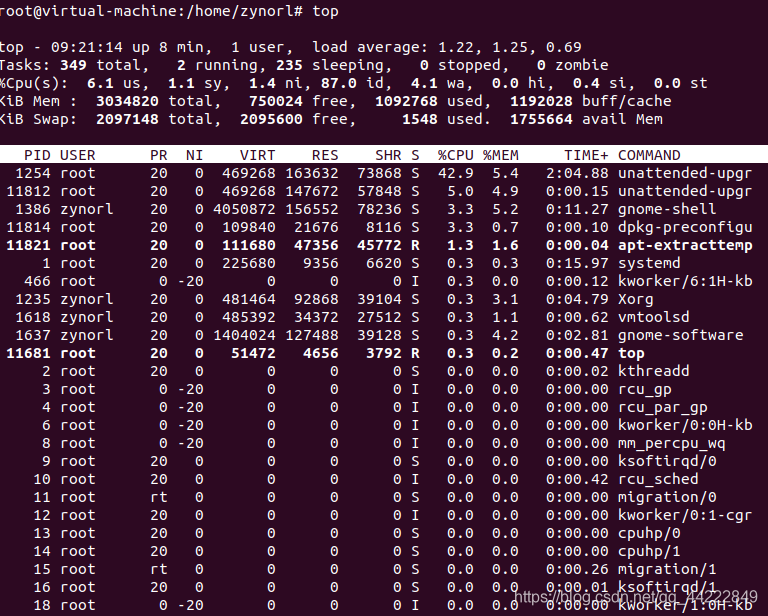
我任意选择了PID为360的进程(这里有一个错误,我是想截图360,截成了370,因为,在我截图的时候,画面在动。但他们的nice都为-20):

6、运行截图:
7、编译该程序并运行后,使用 dmesg -T 命令查看输出内容,如图 :
dmesg -T

8、然后再转到top查看360pid的nice值,已经变成了-19,说明我们测试成功了。但,因为,top运行出来的图,一直在动,不方便截图。这里就没有图片演示了。
系统调用所涉及的源码讲解
以下代码是在Linux内核官方文档copy而来,注释是自己的理解,个人能力有限,有错误的地方还请大家见谅。
set_user_nice源码链接:
https://elixir.bootlin.com/linux/v5.6.3/source/kernel/sched/core.c#L4503
在讲代码之前,我先上一些预备知识:
-
在由task_struct定义的进程控制块PCB定义中,每个进程有4个优先级成员变量,如下:
prio(动态优先级)、normal_prio(归一化优先级)、static_priority(静态优先级1)和rt_priority(实时优先级)。
关于进程优先级的更多解读:
Linux调度器 ——进程优先级
-
我们知道,在调度时使用了prio,其数值0对应最高优先级,99为最低实时优先级。Prio和normal_prio 数值越大优先级越小,而rt_priority的数值越大优先级越大。这就是为什么有人说实时进程优先级数值越小优先级越高,也有人说实时进程优先级数值越大优先级越高的原因。
-
对于普通进程而言,进程优先级就是nice value,从-20(优先级最高)~19(优先级最低),通过修改nice value可以改变普通进程获取cpu资源的比例。nice只针对普通进程有效,对实时进程无效,nice可以被user设置其相关的优先级(-20~19)来辅助进程调度。nice,并不直接影响实际的调度策略(prio动态优先级)。
具体可参考我的博客:
进程优先级,进程nice值和%nice的解释
-
task_truct中的policy成员记录了该线程的调度策略,有DL(deadline)调度器 与 RT(rt_priority)调度器。
具体可参考我的博客:
实时调度器之 DL(deadline)调度器 与 RT(rt_priority)调度器 详解
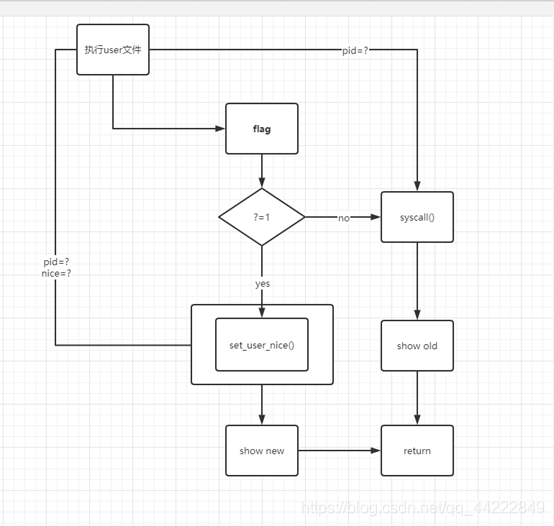
set_user_nice
/*
* 1、从上面的系统调用,和set_user_nice命名可以看出,该方法是设置user即普通进程的优先级,说白了
* 不是实时进程。
* 2、NICE是反应进程优先级的一个值,范围是[-19,+20],一共有40个值,值越小,代表的优先级更高;反 * 之,值越大,优先级越低。
* 3、task_struct结构体是Linux下的进程控制块PCB,PCB里包含着一个进程的所有信息。*p可以简单地理* 解为就是我们要set的进程。
*/
void set_user_nice(struct task_struct *p, long nice)
{
bool queued, running;//布尔值 就绪队列状态或运行状态
int old_prio;//原优先级
struct rq_flags rf;//运行队列的标志
struct rq *rq;//运行队列
//如果传入的要设置的nice与原本的nice相同就不用再次设置,直接return,退出该函数。
//如果传入的要设置nice不在规定的[-19,+20]的范围内也直接return.
if (task_nice(p) == nice || nice < MIN_NICE || nice > MAX_NICE)
return;
/*
* We have to be careful, if called from sys_setpriority(),
* the task might be in the middle of scheduling on another CPU.
*/
rq = task_rq_lock(p, &rf);//上锁,进程在访问一个临界资源时,要有加锁操作。
update_rq_clock(rq);//更新运行队列时钟
/*
* The RT priorities are set via sched_setscheduler(), but we still
* allow the 'normal' nice value to be set - but as expected
* it wont have any effect on scheduling until the task is
* SCHED_DEADLINE, SCHED_FIFO or SCHED_RR:
*/
/*
* 1、task_has_policy(),task_has_rt_policy() 分别判断当前进程 p 是不是实时进程
*(DL(deadline)+ RT(rt_priorit));在PCB中的policy成员记录了该线程的调度策略。
* 2、如果是实时进程,nice就会不起作用,也不会实际改变调度器行为,但这里还是将传入的nice赋
* 值给了p->static_prio静态优先级。
* 3、但,值得注意的是,如果是实时进程就没有了入队和出队操作(queued,running),直接释放
* 之前占用的锁,然后return。
*/
if (task_has_dl_policy(p) || task_has_rt_policy(p)) {
p->static_prio = NICE_TO_PRIO(nice);
goto out_unlock;
}
//执行到这里,只可能是普通进程了
queued = task_on_rq_queued(p);//排队状态
running = task_current(rq, p);//运行状态
if (queued)
dequeue_task(rq, p, DEQUEUE_SAVE | DEQUEUE_NOCLOCK);//dequeue_task 出队
if (running)
put_prev_task(rq, p);//用另一个进程代替当前运行的进程之前调用,将切换出去的进程插入到队尾
p->static_prio = NICE_TO_PRIO(nice);//将进程的静态优先级赋值
/*
* 负责根据非实时进程类型极其静态优先级计算符合权重(cpu资源),CFS调度器在计算进程的虚拟运
* 行时间或者调度延迟时都是使用的权重(cpu资源)。
* 当系统中没有实时进程或者deadline进程的时候,所有的runnable的进程一起来瓜分cpu资源,以此
* 不同的进程分享一个特定比例的cpu资源,我们称之load weight。不同的nice value对应不同的
* cpu load weight,因此,当更改nice value的时候,也必须通过set_load_weight来更新该进程
* 的cpu load weight。除了load weight,该线程的动态优先级也需要更新,这是通过p->prio =
* effective_prio;来完成的
*/
set_load_weight(p, true);
/*
* task struct中的prio成员表示了该线程的动态优先级,也就是调度器在进行调度时候使用的那个优
* 先级。动态优先级在运行时可以被修改,例如在处理优先级翻转问题的时候,系统可能会临时调升一个
* 普通进程的优先级。
* */
//通过effective_prio()更新进程p的动态优先级(prio).
old_prio = p->prio;
p->prio = effective_prio(p);
//
if (queued)
enqueue_task(rq, p, ENQUEUE_RESTORE | ENQUEUE_NOCLOCK);//enqueue_task:入队
if (running)
set_next_task(rq, p);
/*
* If the task increased its priority or is running and
* lowered its priority, then reschedule its CPU:
*/
//如上文英文注释代码所说的,在当前进程的调度策略发生变化时调用,那么需要调用这个函数改变CPU
p->sched_class->prio_changed(rq, p, old_prio);
out_unlock:
task_rq_unlock(rq, p, &rf);//解锁
}
effective_prio
static int effective_prio(struct task_struct *p)
{
p->normal_prio = normal_prio(p);
/*
* If we are RT tasks or we were boosted to RT priority,
* keep the priority unchanged. Otherwise, update priority
* to the normal priority:
* 如果是实时进程,keep the priority unchanged,直接return该进程的动态优先级.
* 如不是,更新动态优先级为normal_prio(归一化优先级),那什么是归一化优先级请看下段代码
*/
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
}
normal_prio
static inline int normal_prio(struct task_struct *p)
{
int prio;
/*
* MAX_RT_PRIO-1是99,MAX_RT_PRIO-1 - p->rt_priority则翻转了实时进程的scheduling
* priority,最高优先级是0,最低是98。
* */
//如果该优先级是基于deadline调度策略实时优先级,那么动态优先级是最大的DL-1=-1
//因此,deadline的进程比RT进程和normal进程的优先级还要高
if (task_has_dl_policy(p))
prio = MAX_DL_PRIO-1;
else if (task_has_rt_policy(p))
//MAX_RT_PRIO-1 - p->rt_priority ; 由这条语句可以看出Prio与rt_priority的优先级与数值的关系成反比
prio = MAX_RT_PRIO-1 - p->rt_priority;
else
//prio和normal_prio是等似的,都与rt_priority的优先级与数值的关系正好相反。
prio = __normal_prio(p);
return prio;
}
对于普通进程,set_user_nice()顺下来:
p->static_prio = NICE_TO_PRIO(nice);
p->prio=p->normal_prio;
最后我们也可以得出一个这样的结论:
对于非实时进程的prio和normal_prio 一直保持相同
参考于: