flink的精确一次性需要有以下保证:

一 checkpoint
checkpoint是flink实现的精确一次性的保证,checkpoint的原理其实与flink
的watermark是相似的,简而言之是一定时间后触发操作,进行状态的保存,在所有任务保存完毕后,向JobManager提示检查点保存工作完成。
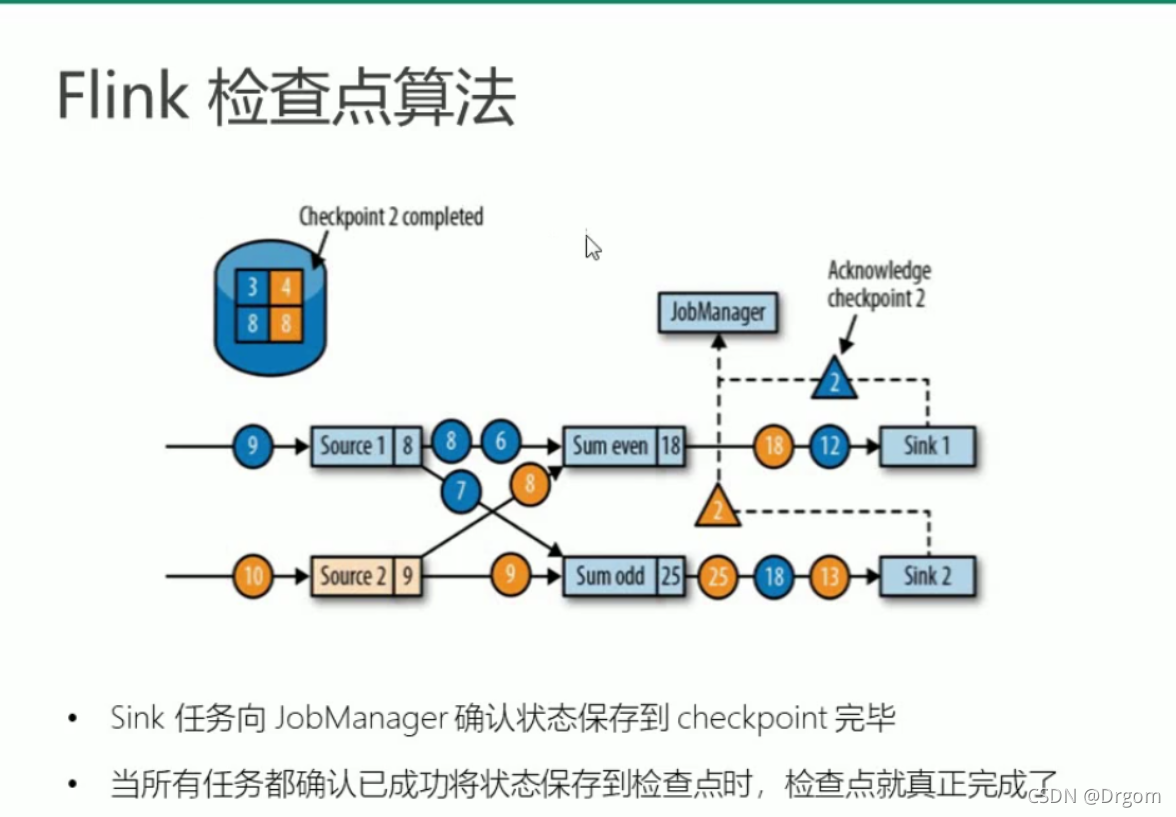
一旦flink执行出错,可根据检查点重启,尽快恢复工作

二 source端是可重放的
根据检查点机制只能恢复到上一个状态,但如果新的数据是不可重放的,意味着任务失败前,上一个检查点的状态的数据会丢失,如kafka这些
三 保证Sink的写入不会重复
防止Sink写入重复的数据,Sink执行可考虑使用事务机制,具体的一般有两种方法:
一 wal(预写日志)

但无法保证不会写入重复数据,如sink写入外部的数据库中途失败,重新执行时,会重新写入失败前的数据,
二两段提交
真正实现了精确一次性

版权声明:本文为qq_43662627原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。