ABTest类似于以前的对比实验,是让组成成分相同(相似)的群组在同一时间维度下去随机的使用一个方案(方案A、或者B、C…),收集各组用户体验数据和业务数据,最后分析出哪个方案最好。
目录
2、某app,用户活跃周期是14天,这时,上线了一个实验,计划跑20天在看效果,结果有位新同学,在10天时做了统计推断,发现数据已经有了显著差异,认为可以停止实验,这样做对吗?
ABtest 意义:
1、消除不同意见,提高团队效率
2、通过实验可以验证问题的原因
3、降低人为决策风险,用统计数字对运营提高科学支持
ABtest 目标:
1、希望尽快得到实验结论,尽快决策
2、希望收益最大化,用户体验影响最小
一、实现步骤

- 现状分析:分析业务数据,确定当前最关键的改进点。
- 假设建立:根据现状分析作出优化改进的假设,提出优化建议。
- 设定目标:设置主要目标,用来衡量各优化版本的优劣;设置辅助目标,用来评估优化版本对其他方面的影响。
- 设计开发:制作若干个优化版本的设计原型。
- 确定分流方案:使用各类ABTest平台分配流量。初始阶段,优化方案的流量设置可以较小,根据情况逐渐增加流量。注意分流时要尽可能做到没有区别。
- 采集数据:通过各大平台自身的数据收集系统自动采集数据。
- 分析ABTest结果:统计显著性达到95%或以上并且维持一段时间,实验可以结束;如果在95%以下,则可能需要延长测试时间;如果很长时间统计显著性不能达到95%甚至90%,则需要决定是否中止试验或重新设计方案。
选取实验单位:
1、
用户粒度
:以一个用户的唯一标识来作为实验样本。
好处是符合AB测试的分桶单位唯一性,不会造成一个实验单位处于两个分桶,造成的数据不置信。
2、设备粒度:以一个设备标识为实验单位。相比用户粒度,如果一个用户有两个手机,那么也可能出现一个用户在两个分桶中的情况,所以也会造成数据不置信的情况。
3、行为粒度:以一次行为为实验单位,也就是用户某一次使用该功能,是实验桶,下一次使用可能就被切换为基线桶。会造成大量的用户处于不同的分桶。强烈不推荐这种方式。
计算样本量:
中心极限定理:
只要样本量足够大,无论是什么指标,无论对应的指标分布是怎样的,样本的均值分布都会趋于正态分布。
大数定律

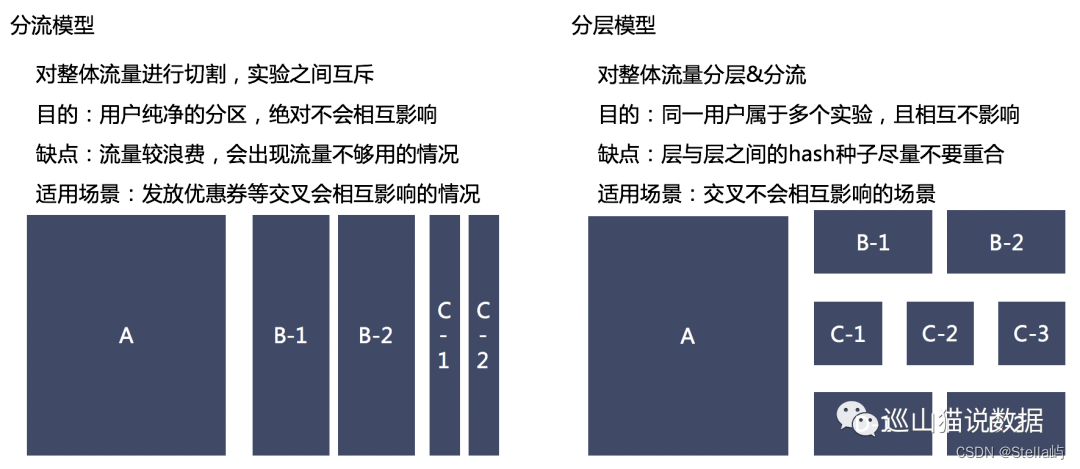
流量分割:
两种方式:分流和分层
尽量科学,使每组实验对象具备一致的用户特征
1、分流:指直接将整体用户切割为几块,用户只能在一个实验中。但是这种情况很不现实,因为如果我要同时上线多个实验,流量不够切怎么办?那为了达到最小样本量,就得延长实验周期。
2、分层:将同一批用户,不停的随机后,处于不同的桶。也就是说,一个用户会处于多个实验中,只要实验之间不相互影响,我们就能够无限次的切割用户。这样在保证了每个实验都能用全流量切割的同时,也保证了实验数据是置信的。
实验周期计算
切分流量,知道了实验桶一天大概能有多少样本量(也可以算小时,如果产品的流量足够大)。我们直接用 最小样本量 / 实验桶天均流量 即可以得到相应的实验周期。
线上验证:
很多公司不会做,但建议做。验证两个方向:
1、验证实验策略是否真的触发。即我们上线的实验桶,是否在产品上实际落地了。比如你优化了一个产品功能,你可以去实际体验下,实验桶产品是否真的有优化。
2、验证同一个用户只能在同一个桶中,要是同时出现在两个桶中,后期数据也会不置信。这个上文有说过。
二、假设检验
A组和B组之间的差异,来源于2种情况:
- 分配对象的随机可能性
- A组与B组之间的真实差异
假设检验的基本思想:
“小概率事件”原理
1、假设检验的基本步骤:
- 原假设+备择假设:
- 根据备择假设确定检验方向:单向检验+双向检验
- 选定统计方法:Z检验、T检验,秩和检验和卡方检验……
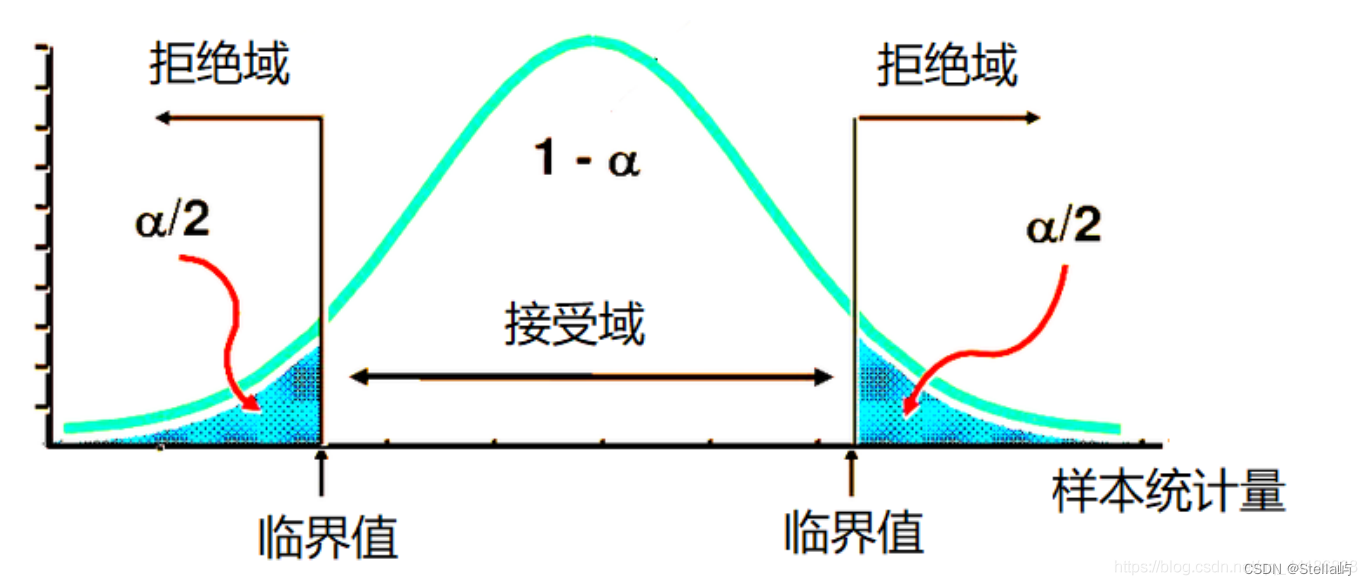
- 选定显著性水平α。无论接受或拒绝检验假设,都有判断错误的可能性。
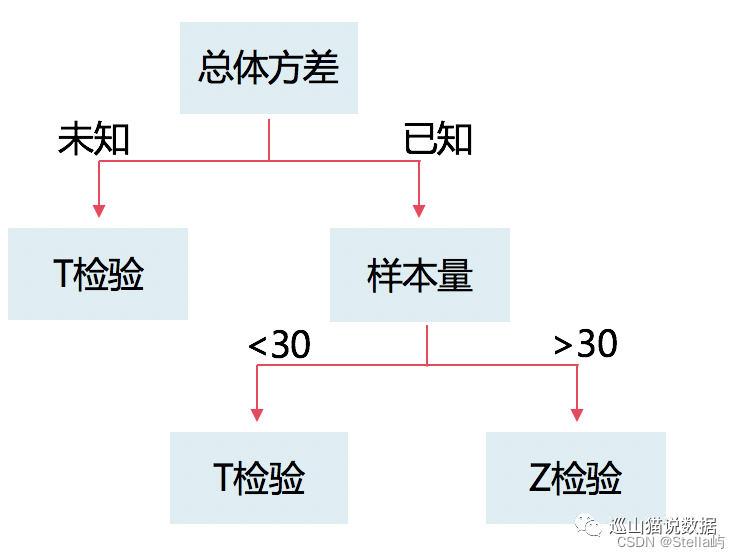
如何选择统计方法?如何判断统计量服从什么分布?


2、各分布+拒绝域
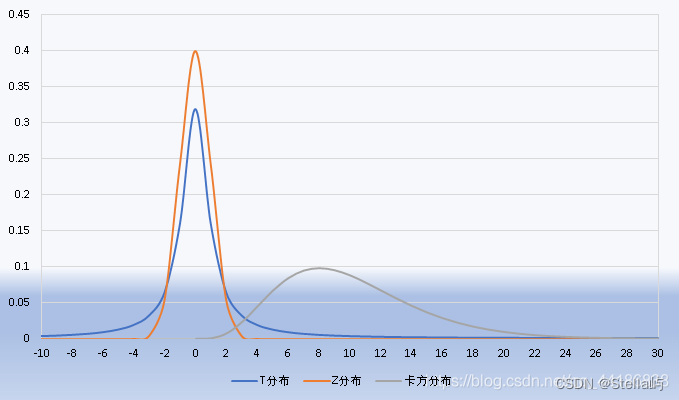
2.1 对称性(t分布+正态z分布)
T分布与标准正态分布(Z分布)都是以0为对称的分布,T分布的方差大所以分布形态更扁平些。
双侧:
单侧:
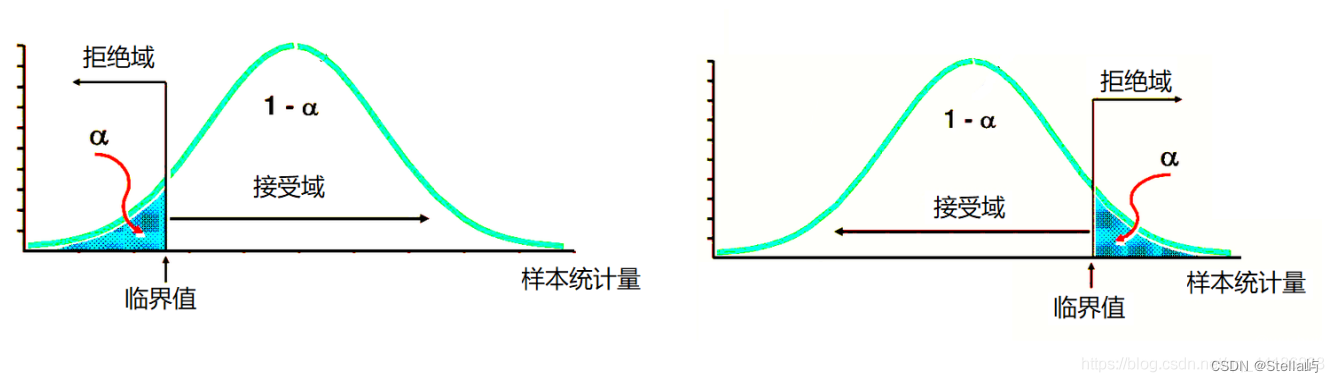
2.2 非对称型(F分布、卡方分布)
卡方分布:左侧拒绝域特别小,故卡方检验拒绝域一般放在右侧。
ROI—投资回报率哪个更高?
成本方面,每个实验组成本可以直接计算,对于收益方面,就要和对照组相比较,假定以总日活跃天(即 DAU 按日累计求和)作为收益指标,需要假设不做运营活动,DAU 会是多少,可以通过对照组计算,即:
- 实验组假设不做活动日活跃天 = 对照组日活跃天 * (实验组流量 / 对照组流量)
- 实验组收益 = 实验组日活跃天 – 实验组假设不做活动日活跃天
这样就可以量化出每个方案的 ROI。
三、注意事项
1、不适合用ABtest:(三种情况)
变量不可控,或者样本量比较小不足以支撑AB测试,或者我们的投放是全流量投放。
变量不可控,比如我们业务有两个APP,我们想做一个策略,验证是否能够提高用户使用了A产品,再去使用B产品的概率。这种是不支持AB测试的,因为用户关闭一个APP后,非常多的不可控因素。
样本量较小也不支持AB测试,因为从统计学上来说,我们要验证一个数据是否有效,还是需要一定的样本量的。
2、网络效应
常出现在社交网络,以及共享经济场景(如滴滴)。
eg.微信改动了某一个功能,这个功能
让实验组用户更加活跃
。但是相应的,实验组的用户的好友没有分配到实验组,而是对照组。但是,实验组用户更活跃(比如更频繁的发朋友圈),作为对照组的我们也就会经常去刷朋友圈,那相应的,
对照组用户也受到了实验组用户的影响
。本质上,对照组用户也会受到新功能的影响,那么AB实验就不再能很好的检测出相应的效果。【要保持实验组间的独立性】
解决办法:
从地理上区隔用户
,这种情况适合滴滴这种能够从地理上区隔的产品,比如
北京是实验组,上海是对照组,只要两个城市样本量相近即可
。或者从用户上直接区隔,比如我们刚刚举的例子,我们
按照用户的亲密关系区分为不同的分层
,按照用户分层来做实验即可。但是这种方案比较复杂,建议能够从地理上区隔,就从地理上区隔。
3、学习效应(新奇效应)
产品做了一个醒目的改版,比如将某个按钮颜色从暗色调成亮色。那相应的,很多用户刚刚看到,会有个新奇心里,去点击该按钮,导致按钮点击率在一段时间内上涨,但是长时间来看,点击率可能又会恢复到原有水平。反之,如果我们将亮色调成暗色,也有可能短时间内点击率下降,长时间内又恢复到原有水平。这就是学习效应。
解决办法:拉长周期,不要一开始就去观察该指标,而是在一段时间后再去观察指标。新奇效应会随着时间推移而消失。另一种办法是只看新用户,因为新用户不会有学习效应这个问题,毕竟新用户并不知道老版本是什么样子的。
4、多重检验问题
不断的检验指标是否有差异,会造成我们的结果不可信。也就是说,多次检验同一实验导致第一类错误概率上涨;同时检验多个分组导致第一类错误概率上涨。、

当不断的去检验实验效果时,第一类错误的概率会直线上涨。所以我们在实验结束前,不要多次去观察指标,更不要观察指标有差异后,直接停止实验并下结论说该实验有效。
5、小tips
-
用户属性要一致
如果上线一个实验,我们对年轻群体上线,年老群体不上线,实验后拿着效果来对比,即使数据显著性检验通过,那么,实验也是不可信的。因为AB测试的基础条件之一,就是
实验用户的同质化。
即实验用户群,和非实验用户群的 地域、性别、年龄等自然属性因素分布基本一致。
-
一定要在同一时间维度下做实验
如果某一个招聘app,年前3月份对用户群A做了一个实验,年中7月份对用户群B做了同一个实验,结果7月份的效果明显较差,但是可能本身是由于周期性因素导致的。所以我们在实验时,一定要排除掉季节等因素。
-
AB测试一定要从小流量逐渐放大
如果上线一个功能,直接流量开到50%去做测试,那么如果数据效果不好,或者功能意外出现bug,对线上用户将会造成极大的影响。所以,建议一开始从最小样本量开始实验,然后再逐渐扩大用户群体及实验样本量。
-
如果最小样本量不足该怎么办
如果我们计算出来,样本量需要很大,我们分配的比例已经很大,仍旧存在样本量不足的情况,那么我们只能通过
拉长时间周期
,通过累计样本量来进行比较
-
是否需要上线第一天就开始看效果?
由于AB-Test,会影响到不同的用户群体,所以,我们在做AB测试时,尽量设定一个测试生效期,这个周期一般是用户的一个活跃间隔期。如招聘用户活跃间隔是7天,那么生效期为7天,如果是一个机酒app,用户活跃间隔是30天,那生效期为30天
-
用户是否生效
用户如果被分组后,未触发实验,我们需要排除这类用户。因为这类用户本身就不是AB该统计进入的用户(这种情况较少,如果有,那在做实验时打上生效标签即可)
-
用户不能同时处于多个组
如果用户同时属于多个组,一个是会对用户造成误导(如每次使用,效果都不一样),一个是会对数据造成影响,我们不能确认及校验实验的效果及准确性
四、面试问题:
1、滴滴准备升级司机端的一个功能,该如何校验功能效果?
ABtest+网络效应
AB测试的流程是 确定目标 –> 确定实验单位 –> 确定最小样本量 –> 确认流量分割方案 –> 实验上线 –> 规则校验 –> 数据收集 –> 效果检验。
实验分桶,以两个量级相近城市分割,避免网络效应的相互影响
2、某app,用户活跃周期是14天,这时,上线了一个实验,计划跑20天在看效果,结果有位新同学,在10天时做了统计推断,发现数据已经有了显著差异,认为可以停止实验,这样做对吗?
实验周期应该跨越一个活跃周期+多重检验
由于AB测试的实验周期尽量跨越一个用户活跃周期,且在
实验结束时再做统计推断
,所以该做法不对,建议跑慢20天再看数据效果
3、如何处理多个实验并行?
正交实验:
每个独立实验为一层,层与层之间流量是正交的,一份流量穿越每层实验时,都会再次随机打散,且随机效果离散。
eg:我们有100个兵乓球,随机拿出来50个染成蓝色,50个染成白色,则我们有蓝色、白色兵乓球各50个,现在我们把这100个兵乓球重新放在袋子中摇匀,随机拿出50个兵乓球,那么这50个兵乓球颜色蓝色和白色各25。
互斥实验
eg:我们有 100 个兵乓球,每 25 个为一组,分别染成蓝、白、橘、绿。
若 X 实验拿的是蓝色、白色,则 Y 实验只能拿橘色和绿色,我们说 X 实验和 Y 实验是互斥的。
- AB test 需要注意的点
(1)先验性:低代价、小流量实验,再推广到全流量
(2)并行性:不同版本、不同方案在验证时,要保证其他条件一致
(3)分流科学+数据科学(通过置信区间、假设检验等得出结论)
(4)网络效应+学习效应+多重检验问题
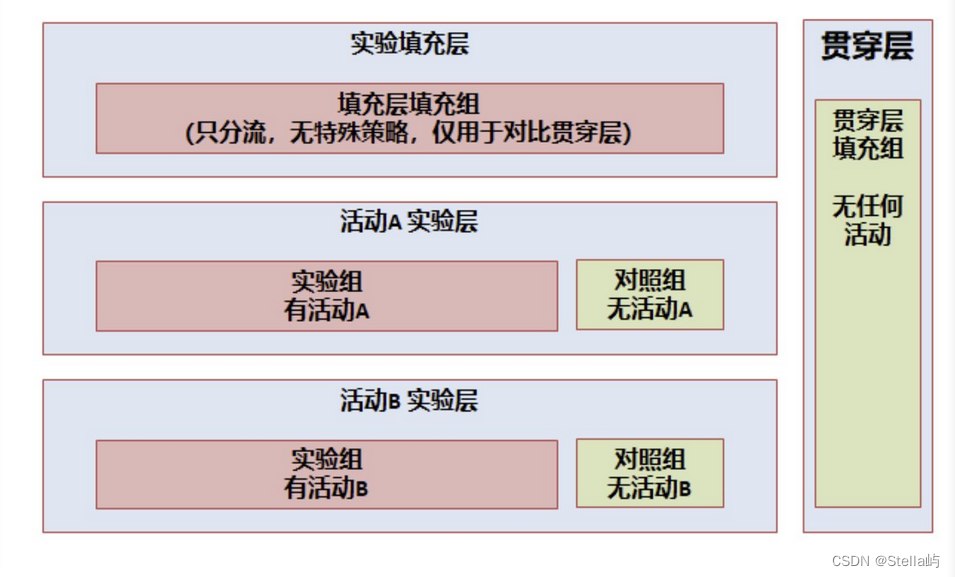
4、多个活动交集量化的实验设计:
春节活动各个子活动的贡献之和,不等于春节活动的贡献,为什么呢?
- 活动 A 和活动 B,有着相互放大的作用,1+1 > 2
- 活动 A 和活动 B,本质上是在做相同的事情, 1+1 < 2
5、辛普森悖论:
eg:取出1%用户跑了一个试验,发现试验版本购买率比对照版本高,就说试验版本更好,我们要发布试验版本。其实,可能只是我们的试验组里
圈中了一些爱购买的用户
而已。最后发布试验版本,反而可能降低用户体验,甚至可能造成用户留存和营收数额的下降。
解决方法
:合理的进行正确的流量分割,保证试验组和对照组里的用户特征是一致的,并且都具有代表性,可以代表总体用户特征。