谈从10亿个数中找出前100个最大的(阿里java二面)
单位关系:
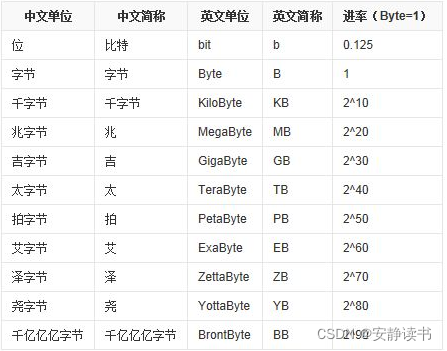
基本数据类型占用字节数:
|
|
|
|
|
|
|
|
布尔型 |
boolean |
Boolean |
1字节 |
true,false |
false |
|
字符型 |
char |
Character |
2字节 |
16位Unicode字符,可容纳各国字符集。Unicode范围为‘\u0000’到‘ufff’。整数范围是0~65535。例如,65代表‘A’,97代表‘a’ |
‘\u0000’ Null |
|
字节型 |
byte |
Byte |
1字节 |
-128~127 (-27~27-1) |
0 |
|
短整型 |
short |
Short |
2字节 |
-32768~32767 (-215~215-1) |
0 |
|
整形 |
int |
Integer |
4字节 |
-231~231-1 |
0 |
|
长整型 |
long |
Long |
8字节 |
-263~263-1 |
0 |
|
单精度型 |
float |
Float |
4字节 |
0.0F |
|
|
双精度型 |
double |
Double |
8字节 |
0.0D |
一个单精度浮点数占用4字节,10亿个浮点数是40亿字节,对应G与字节转换为2^30/1,所以10亿个浮点数大概占据3G左右的空间,因此全部一次性读入内存目前在个人PC上是不太现实的。本次讨论不考虑内存等等,只考虑算法。
如果一次性比较排序,然后输出前面最大的100个,那么众所周知,算法的时间复杂度不下于O(N logN),此处的N为数的个数(10亿)。
如果用堆排序,由于堆排序像合并排序而不像插入排序,堆排序的运行时间为O(N logN);又像插入排序而不像合并排序,堆排序是一种原地排序。因此堆排序具有相对小的运行时间和占用相对小的额外空间的优点。
再则,利用最小堆的性质,堆顶元素是整棵树中具有最小值的元素,因此,我们可以构建这样的一个最小堆:
step1:取前m个元素(例如m=100),建立一个小顶堆
保持一个小顶堆得性质的步骤,运行时间为O(logm);
建立一个小顶堆运行时间为m*O(logm)=O(m logm);
其实建立一个小顶堆实际运行时间为O(m);具体分析参考算法导论。
step2:顺序读取后续元素,直到结束
每次读取一个元素,如果该元素比堆顶元素小,直接丢弃
如果大于堆顶元素,则用该元素替换堆顶元素,然后保持最小堆性质
最坏情况是每次都需要替换掉堆顶的最小元素,因此需要维护堆的代价为(N-m)*O(logm);
最后这个堆中的元素就是前最大的100个。
时间复杂度为O(10亿 log100),即时间复杂度为O(N logm)。