目录
介绍
行转列操作是一种常见的数据转换技术,它可以将原始的行数据转换为列数据,从而更方便地进行分析和可视化。然而,传统的行转列方式只能处理固定数量的行转列操作,无法处理不确定数量的行转列操作。为了解决这个问题,我们可以使用动态行转列技术。
动态行转列可以处理不确定数量的行转列操作,因为它使用动态 SQL 语句生成动态的列名。动态行转列具有高度的灵活性和扩展性,可以适应不同的数据结构和应用场景。在本文中,我们将介绍如何使用动态 SQL 实现动态行转列,并提供一个具体的案例演示。
分析过程
数据样例
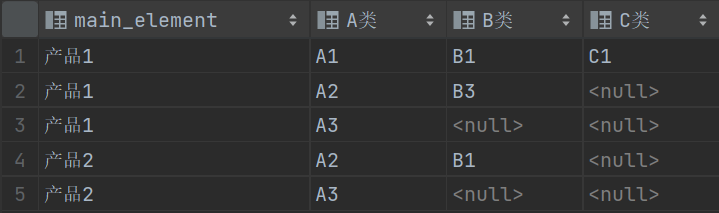
假设我们有若干产品BOM信息,现有数据样例及期望得到的结果如下图:
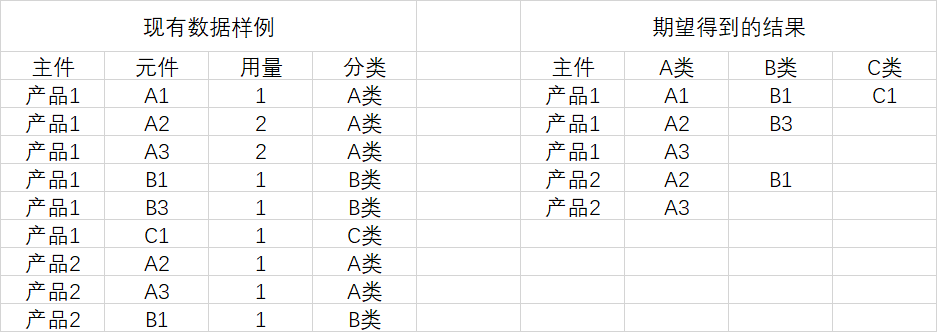
这个不像网上普遍的销售数据的转换那么简单,多行转换为多列,同时还有多行数据需要合并。那我们先简化问题,假设分类是固定的,先写出SQL看看,然后再针对分类未知的情况做改进。
开始动手
我们先试试将行列进行转换,对着数据分析,看看离我们的目标有多远。先创建表,简单插入一些数据,然后行转列:
create table prod (
main_element varchar(10) not null,
element char(2) not null,
num int not null,
type varchar(4) not null
);
insert into prod values('产品1','A1',1,'A类');
insert into prod values('产品1','A2',2,'A类');
insert into prod values('产品1','A3',2,'A类');
insert into prod values('产品1','B1',1,'B类');
insert into prod values('产品1','B3',1,'B类');
insert into prod values('产品1','C1',1,'C类');
insert into prod values('产品2','A2',1,'A类');
insert into prod values('产品2','A3',1,'A类');
insert into prod values('产品2','B1',1,'B类');
select main_element,type,if(type='A类',element,'') as A类,
if(type='B类',element,'') as B类,
if(type='C类',element,'') as C类
from prod;
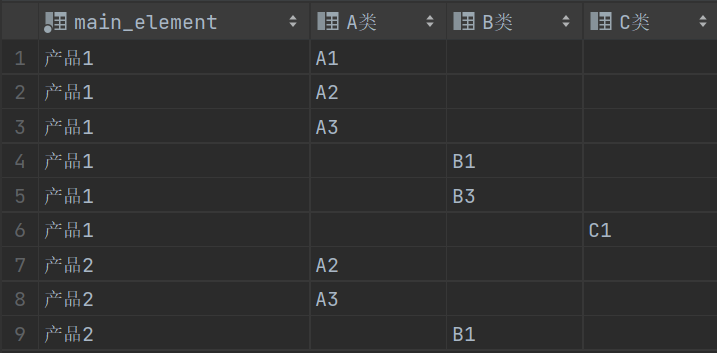
结果如上,我们需要将同一主件的这些行合并,把A类、B类、C类的数据看成是在不同的表中,通过全连接可以实现合并。
添加辅助列
因为要分别筛选出A类、B类、C类的元件数据,因此原表的分类列也需要查询出来。另外不同的分类数据如果仅通过主件名称关联,会产生笛卡尔积,因此还需要为每个元件按主件分组编号来辅助关联,修改后的SQL及查询结果如下:
select main_element,type,row_number() over (partition by main_element,type order by element) seq,
if(type='A类', element, '') AS 'A类',
if(type='B类', element, '') AS 'B类',
if(type='C类', element, '') AS 'C类'
from prod;
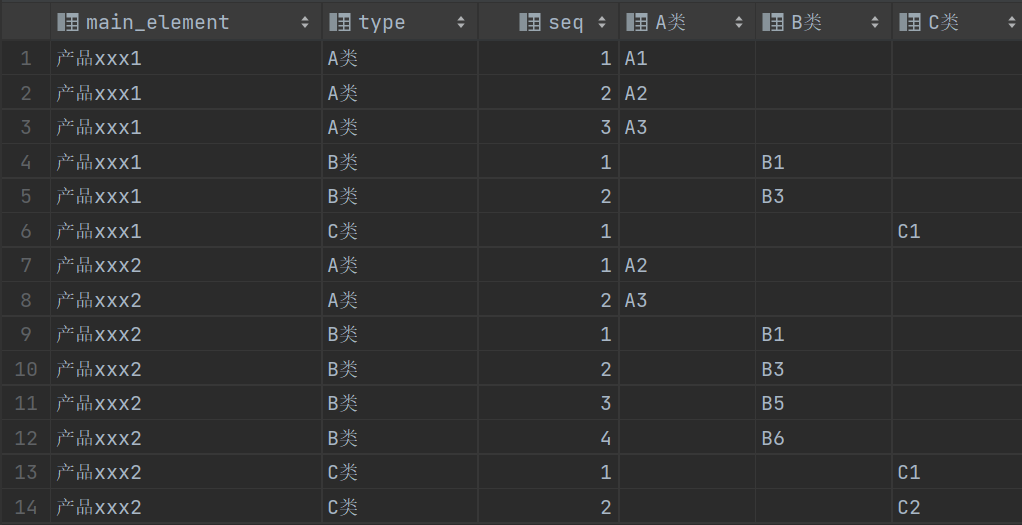
然后就是使用上面的结果,分别筛选出A类、B类、C类的数据,然后连接起来,各个分类的元件数量不一,应使用全连接。即使MySQL没有全连接,咱也不要使用左连接再union右连接,会增加后面动态SQL的复杂度。
全连接换左连接
那就想想别的办法,只要从上述数据获取所有的主件和元件编号,就可以简化为使用左连接了。使用with as将上述数据放入临时表(后续需要多次查询),先获取所有的主件和元件编号:
with prod1 as (
select main_element,type,
row_number() over (partition by main_element,type order by element) seq,
if(type='A类', element, '') AS A类,
if(type='B类', element, '') AS B类,
if(type='C类', element, '') AS C类
from prod
)
select distinct main_element,seq from prod1;
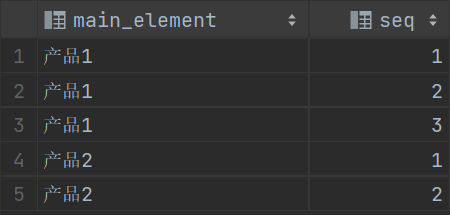
完成静态SQL
最后,从临时表prod1分别筛选出A类、B类、C类的数据,与上面的查询结果(放入另一临时表p)进行左连接,就得到我们需要的结果了:
-- 静态SQL
with prod1 as (
select main_element,type,
row_number() over (partition by main_element,type order by element) seq,
if(type='A类', element, '') AS A类,
if(type='B类', element, '') AS B类,
if(type='C类', element, '') AS C类
from prod
), p as (
select distinct main_element,seq from prod1
)
select p.main_element,p1.A类,p2.B类,p3.C类
from p left join prod1 p1
on p.main_element=p1.main_element and p.seq=p1.seq and p1.type='A类'
left join prod1 p2
on p.main_element=p2.main_element and p.seq=p2.seq and p2.type='B类'
left join prod1 p3
on p.main_element=p3.main_element and p.seq=p3.seq and p3.type='C类';
到此,事情完成一半。因为分类是不固定的,我们的SQL中也不能出现明确的分类。现在回去查看上面的静态SQL,找到与具体分类相关的部分,它是可变的,而且是有规律的!如果将这几部分动态生成,咱们的SQL里面就不会出现明确的分类和与分类数量有关的代码了。
将动态部分设置到变量
上述静态SQL中与具体分类相关的部分有三处。第一处是临时表prod1的查询,将分类转为列。第二处是要查询出来的列。第三处是有多少个分类就需要左连接多少次,每次的别名和过滤的类型不同。对于这三部分,分别通过查询产生,设置到三个不同的变量中。
-- 变量1
set @dynamic_sub_cols = (select group_concat(distinct concat('if(type=''',type,''', element, '''') AS ',type)) from prod);
select @dynamic_sub_cols;变量1生成的结果是:
if(type='A类', element, '') AS A类,if(type='B类', element, '') AS B类,if(type='C类', element, '') AS C类-- 变量2
set @dynamic_main_cols = (
select group_concat('p',seq,'.',type) from (
select type,row_number() over (order by type) seq from (select distinct type from prod) t
) t1
);
select @dynamic_main_cols;变量2生成的结果是:
p1.A类,p2.B类,p3.C类-- 变量3
set @dynamic_left_join = (
select group_concat('left join prod1 p',seq,
'\non p.main_element=p',seq,'.main_element and p.seq=p',seq,'.seq and p',seq,'.type=''',type,'''' separator '\n')
from (select type,row_number() over (order by type) seq from (select distinct type from prod) t) t1
);
select @dynamic_left_join;变量3生成的结果是:
left join prod1 p1
on p.main_element=p1.main_element and p.seq=p1.seq and p1.type='A类'
left join prod1 p2
on p.main_element=p2.main_element and p.seq=p2.seq and p2.type='B类'
left join prod1 p3
on p.main_element=p3.main_element and p.seq=p3.seq and p3.type='C类'
改编为动态SQL
然后将上述三个变量,分别替换掉前面静态SQL中的三处与具体分类相关的部分,得到动态SQL,将内容设置到变量中,通过执行变量中的动态SQL就可以得到之前的结果:
-- 动态SQL
set @dynami_sql = concat('with prod1 as (
select main_element,type,
row_number() over (partition by main_element,type order by element) seq,\n ',
@dynamic_sub_cols,'
from prod
), p as (
select distinct main_element,seq from prod1
)
select p.main_element,',@dynamic_main_cols,'
from p ',@dynamic_left_join);
select @dynami_sql;
prepare stmt from @dynami_sql;
execute stmt;
验证
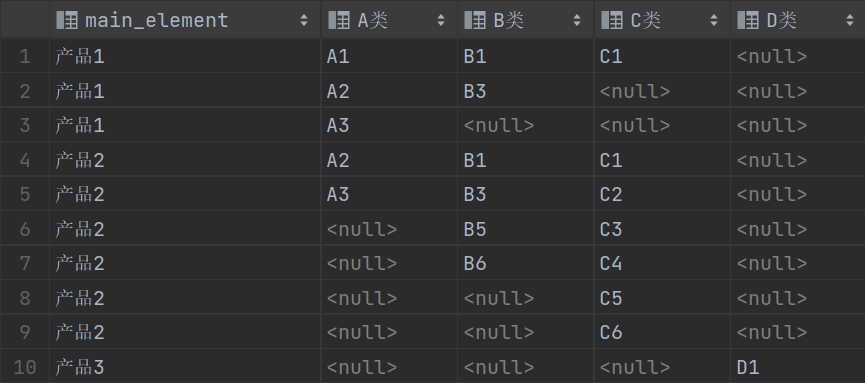
我们现在再向产品表中插入一些数据,以验证结果:
insert into prod values('产品2','B3',2,'B类');
insert into prod values('产品2','B5',2,'B类');
insert into prod values('产品2','B6',2,'B类');
insert into prod values('产品2','C1',1,'C类');
insert into prod values('产品2','C2',1,'C类');
insert into prod values('产品2','C3',1,'C类');
insert into prod values('产品2','C4',1,'C类');
insert into prod values('产品2','C5',1,'C类');
insert into prod values('产品2','C6',1,'C类');
insert into prod values('产品3','D1',1,'D类');
然后执行上述变量1、变量2、变量3和动态SQL,得到如下结果,经验证,咱们的动态SQL满足要求:
总结
动态行转列是一种高效、灵活、扩展性强的数据转换技术,可以处理不确定数量的行转列操作。在本文中,我们介绍了如何使用动态 SQL 实现动态行转列,并提供了一个具体的案例演示。通过本文可以了解到如何使用动态行转列处理不确定数量的行转列操作,从而更方便地进行数据分析和可视化。